
PART II - Pemodelan Data Text dengan Naive Bayes
Arief Rachman Hakim



Summary
Portofolio ini adalah lanjutan dari PART I - Building Dataset : Scraping & Preprocessing Ulasan E-Commerce yang telah menghasilkan corpus yang siap pakai. Portofolio tersebut dapat diakses pada link berikut: https://bisa.ai/portofolio/detail/MTYwMQ . Selanjutnya, pada PART II ini saya akan membuat model dengan dari data text atau corpus tadi menjadi Algoritma Naive Bayes. Dari proses pemodelan ini kita dapat menghasilkan dapat sebuah model berformat pkl yang dapat digunakan untuk aplikasi dengan deployment yang selanjutnya akan dipraktekan pada PART III - Deployment Model Local & Hosting oleh teman saya.
Description
Kelompok 12 Projek Capstone SIB AI-Hacker Batch 3

Penjelasan Projek :
Projek ini bertujuan untuk membuat sebuah aplikasi sentiment analysis mengenai kepuasan penggunaan aplikasi e-commerce di Indonesia dalam hal ini aplikasi e-commerce yang dipakai untuk penelitian adalah Shopee, Tokopedia, dan Bukalapak. Dengan aplikasi ini kita dapat mengetahui termasuk kedalam negatif atau positif dari ulasan yang diberikan terhadap aplikasi e-commerce tersebut sehingga selanjutnya dapat dijadikan sebuah feedback untuk developer atau pengembang aplikasi tersebut.
Anggota Kelompok :
- Afif Syaefudin
- Arief Rachman Hakim
- Wanda Aizul Fahmi
Kontribusi Saya :
Saya membuat model machine learning dengan algoritma naive bayes dari data text yang sebelumnya sudah melalui scraping dan text preprocesing oleh Afif Syaefudin berikut link portofolionya https://bisa.ai/portofolio/detail/MTYwMQ . Data text yang sudah kita dapatkan akan kita oleh dengan metode NLP Pipeline, yaitu

Untuk tahap pertama, Problem Solving, kami mencari latar belakang dan rumusan masalah dari kasus ulasan sebuah aplikasi e-commerce (dalam hal ini aplikasi Bukalapak, Shopee, dan Tokopedia). Dari hasil diskusi, kami menemukan masalah bahwa dari tiap-tiap aplikasi tersebut terkadang mempunyai sebuah kekurangan contohnya, lambatnya dalam meload data, atau pelayanan dari aplikasi terkadang tidak berjalan dengan semestinya. Setelah mendiskusikan hal tersebut, kami memulai Data Acqusition atau mengidentifikasi data apakah yang akan menjadi bahan untuk menjawab masalah yang ditemukan sebelumnya. Kami menemukannya bahwa diperlukan ulasan untuk menjadi feedback dari user dalam hal ini terhadap developer. Ulasan tersebut harus diklasifikasikan menjadi positif atau negatif agar feedback yang diberikan lebih sederhana.
Kami selanjutnya mencari data yang cocok digunakan untuk bahan pembuatan sistem sentimen analisis tersebut. Kami menemukannya dalam ulasan dari tiap-tiap aplikasi tersebut pada google play, yaitu berbagai komentar mengenai aplikasi tersebut. Maka, kami putuskan untuk menggunakan data ulasan tersebut untuk menjadi dataset acuan untuk projek kami.
Selanjutnya pada tahap Data Exploration, kami mulai melakukan Building Dataset dengan Scraping data ulasan ketiga aplikasi diatas pada Google Play yang dilanjutkan dengan Preprocessing atau membersihkan dataset tersebut dari karakter-karakter yang tidak digunakan. Selanjutnya, kami melakukan Feature Extraction untuk mendapatkan makna dari Corpus yang sudah dilakukan Preprocessing sebelumnya.
Setelah melakukan Feature Extraction, kami selanjutnya melakukan pemodelan dengan Machine Learning. Selanjutnya, Model akan dilakukan proses Evaluation sehingga kami tahu berapa hasil akurasi yang dihasilkan.
Terakhir, model yang sudah dilakukan Evaluation maka akan digunakan dalam Deployment sehingga hasil akhirnya menjadi sebuah aplikasi yang dapat mengklasifikasikan kalimat yang diinputkan termasuk positif atau negatif.
Tahapan Proces:
1. Import Library
Library yang dibutuhkan antara lain :
- pandas
- numpy
- sklearn
- nltk
- re
- seaborn

2. Mengecek corpus yang diperoleh dari data text yang sudah melalui text preprocessing sebelumnya. Sebelumnya data text sudah melalui text preprocessing oleh teman saya yaitu Afif Syaefudi, berikut link portofolionya https://bisa.ai/portofolio/detail/MTYwMQ

3. Menggunakan TFIDF untuk feature extraction
TF-IDF merupakan suatu metode algoritma yang berguna untuk menghitung bobot setiap kata yang umum digunakan atau disebut pembobotan kata. Metode ini akan menghitung nilai Term Frequency (TF) dan Inverse Document Frequency (IDF) pada setiap token (kata) di setiap dokumen dalam korpus. Singkatnya, metode ini digunakan untuk mengetahui berapa sering suatu kata muncul di dalam dokumen.

4. Split data
Setelah melalui feature extraction, selanjutnya kita melakukan train text split dengan komposisi 80 : 20 untuk perbandingan data train dan data test dengan random_state sebesar 101. Kita juga melakukan visualisasi hasil dari train_test_split dengan hasil pada gambar dibawah ini.

5. Training data yang sudah di split dengan Algortima Naive Bayes
Kita dapat melakukan training data dengan membuat object MultinomialNB() dari library sklearn yang sudah diimport dan selanjutnya kita train dengan data train.

6. Melakukan prediksi dengan data test
Selanjutnya, kita prediksi model dengan data test. Hal ini bertujuan untuk mengetahui bagaimana peforma hasil prediksi jika menggunakan data test sebelum menggunakan data real.

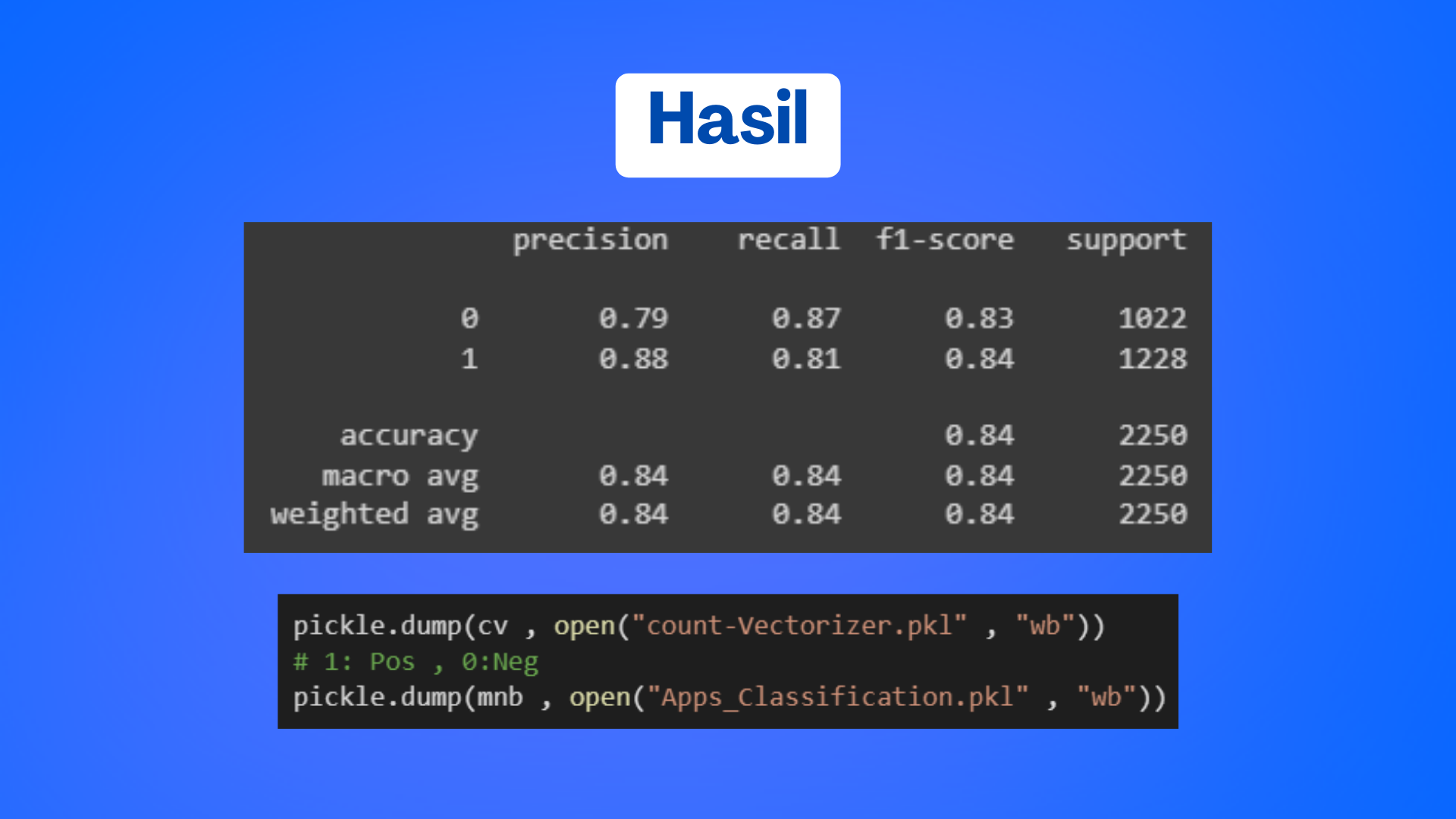
7. Evaluasi Model dari hasil prediksi dengan confussion matrix
Dapat kita lihat dengan model naive bayes kita dapat menghasilkan akurasi sebesar 84%, lalu disusul dengan f1-score yang tidak beda jauh.

8. Melakukan visualisasi data aktual dan data hasil prediksi
Dengan menggunakan model yang sudah kita train, kita dapat memvisualkan bagaimana peforma ketika model memprediksi data Actual dan Predicted. Dapat kita lihat dari lima data yang terprediksi hanya satu saja yang mengalami kesalahan dalam prediksi.

9. Save model yang sudah dibuat
Maka kita hasilkan dengan model dengan format pkl yang dapat digunakan untuk pembuatan aplikasi yang selanjutnya akan dideploy agar bisa diakses oleh semua orang.

10. Membuat fungsi untuk mengetes model
Dengan fungsi ini kita dapat melakukan sentiment analysis menggunakan model hasil TfIdf dan Model Naive Bayes yang sudah kita train. Untuk cara kerjanya, ketika fungsi menerima inputan data text maka data text akan melakukan vectorisasi dengan model TfIdf dan selanjutnya akan masuk kedalam prediksi dengan model naive bayes. Model naive bayes akan memberikan return 1 yang berarti ‘Positive Review’ dan 0 yang berarti ‘Negative Review’.

11. Hasil ketika model memprediksi sentimen positif

12. Hasil ketika model memprediksi sentimen negatif

Itulah tahapan dari pemodelan data text dengan algoritma naive bayes. Selanjutnya, proses deployment akan dikerjakan oleh teman saya.
Informasi Course Terkait
Kategori: Natural Language ProcessingCourse: Dasar Pemrograman Natural Language Programming dengan Python

