
PART I - Building Dataset & Preprocessing Dataset
Afif Syaefudin



Summary
Ulasan dari sebuah aplikasi adalah sebuah hal yang biasa ditemui dalam setiap aplikasi. Dengan ulasan, kita dapat mengetahui peforma saat itu, seperti baik atau buruknya yang dapat kita temui dengan komentar yang cenderung positif atau negatif mengenai aplikasi tersebut . Oleh karena itu, kami dari kelompok 12 projek capstone akan membuat sebuah aplikasi Sentiment Analysis Kepuasan Penggunaan Aplikasi E-Commerce dengan algoritma Naive Bayes. Dalam prosesnya kami membagi tugas dengan Scraping data dan text preprocessing yang dilakukan oleh saya Afif Syaefudin, selanjutnya pembuatan model dengan algoritma naive bayes oleh Arief Rachman Hakim. Terakhir, akan dilakukan deployment model dengan secara Local dan Hosting dengan framework web Flask oleh Wand Aizul Fahmi.
Description
Penjelasan Projek :
Projek ini bertujuan untuk membuat sebuah aplikasi sentiment analysis mengenai kepuasan penggunaan aplikasi e-commerce di Indonesia dalam hal ini aplikasi e-commerce yang dipakai untuk penelitian adalah Shopee, Tokopedia, dan Bukalapak. Dengan aplikasi ini kita dapat mengetahui termasuk kedalam negatif atau positif dari ulasan yang diberikan terhadap aplikasi e-commerce tersebut sehingga selanjutnya dapat dijadikan sebuah feedback untuk developer atau pengembang aplikasi tersebut.
Anggota Kelompok :
Afif Syaefudin
Arief Rachman Hakim
Wanda Aizul Fahmi
Kontribusi Saya :
Saya melakukan proses scraping data untuk membangun dataset baru yang nantinya akan digunakan dalam sentimen analisis kelompok saya. Setelah proses scraping data selesai saya melakukan text preprocessing bertujuan untuk membersihkan dataset dan membuat data menjadi lebih testruktur supaya saat digunakan pada pembuatan model dapat menghasilkan hasil yang maksimal.
Tahapan Proses:
Beberapa tahapan yang saya lakukan dalam scraping data dan text preprocessing sebagai berikut :
1. Meng-install library google-play-scraper menggunakan pip. Ini merupakan library python yang saya gunakan untuk scraping data.

2. Meng-import beberapa library yang diperlukan.

3. Scraping data ulasan aplikasi shopee
Pertama, kita identifikasi dahulu package aplikasi pada google play dengan memperhatikan url ketika kita mengakses pada google play. Ada tiga aplikasi e-commerce yang saya gunakan dalam scraping data yaitu tokopedia, shopee dan bukalapak disini saya mencontohkan aplikasi shopee saya karena proses yang dilakukan di aplikasi lain sama dan supaya tidak berulang.

Selanjutnya, kita masukkan nama package aplikasi ‘com.shopee.id’, bahasa dengan lang = ‘id’, negara dengan country = ‘id’, disusun dengan
kriteria apa misal dengan yang paling relevan sort = ‘Sort.MOST_RELEVANT’, jumlahnya dari datanya dengan count = ‘jumlah’, dan filter scorenya dengan filter_score_with = None (Isi None jika kita perlu score dengan rentang 1 - 5).

4. Menyimpan data yang sudah diperoleh tadi ke dalam sebuah data frame. 
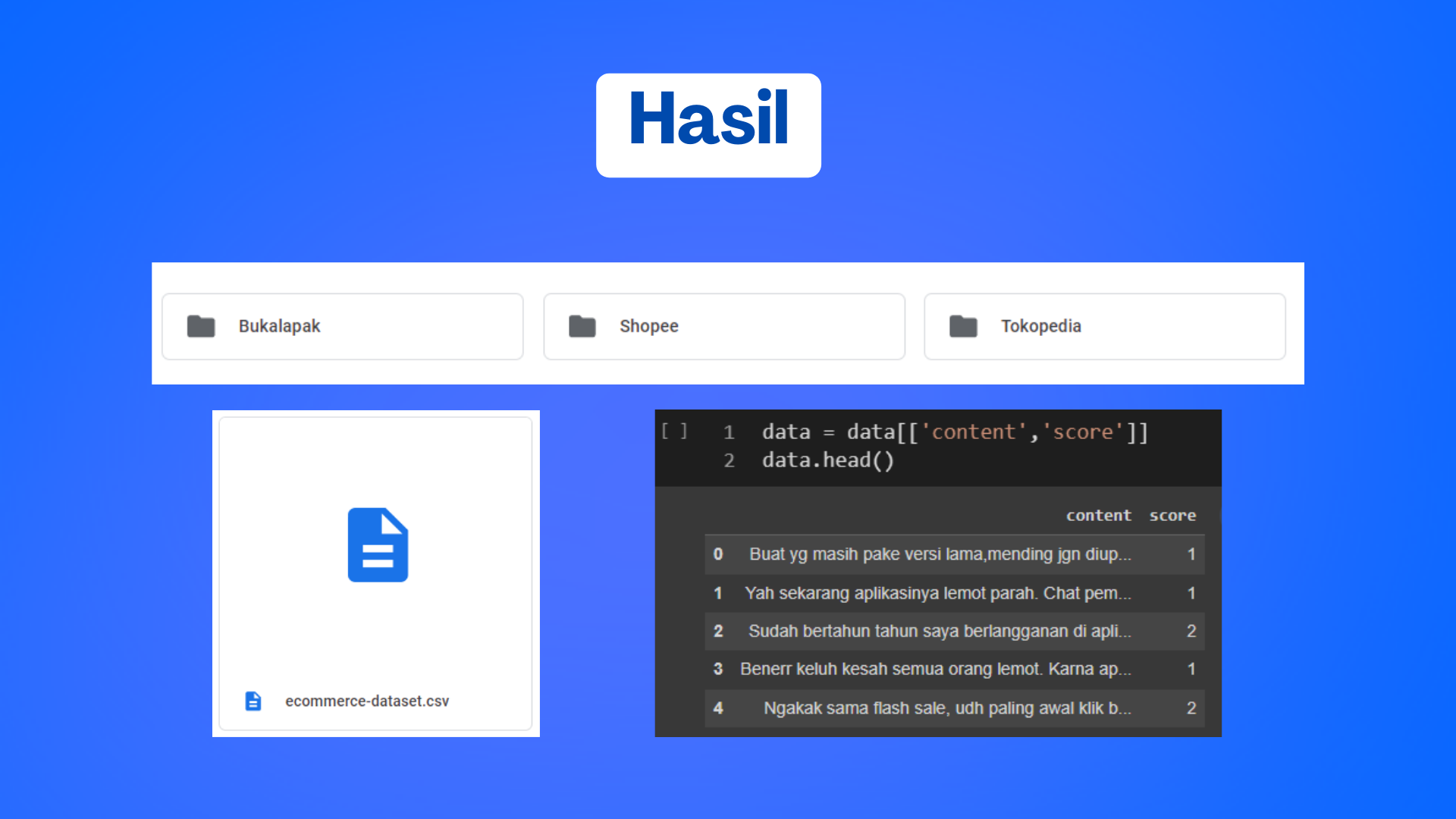
5. Mengambil hanya fitur content dan score
Kita ambil fitur content dan score untuk kebutuhan sentimen analisis. Fitur content menggambarkan ulasan dan fitur score menggambarkan
label dari yang menunjukan puas atau tidak. 
6. Menghapus fitur score dengan nilai 3 karena kami tidak menggunakan label netral.

7. Filter data untuk score yang buruk (1 - 2) Kami menetapkan bahwa ulasan dengan label 1 - 2 termasuk kedalam ulasan yang menggambarkan negatif output atau tidak puas. 
Melakukan drop data pada fitur score yang bernilai 4 
Drop data pada fitur score yang bernilai 5 
Simpan data ke dalam format csv 
Sebelum filter data untuk score yang baik (4 - 5), Kami mengulang mengulang langkah pertama dari scraping data sehingga kami mendapat
data yang sama besarnya dalam score baik dan buruk.
8. Filter data untuk score yang baik (4 - 5) Kami menetapkan bahwa ulasan dengan label 4 - 5 termasuk kedalam ulasan yang menggambarkan positif output atau puas.

Drop data pada fitur score yang bernilai 1 
Drop data pada fitur score yang bernilai 2 
Save data ke dalam format csv 
9. Identifikasi dalam colab maka terdapat dua file dengan format csv 
10. Meng-import library untuk menggabungkan dua file csv. Dengan menggabungkan dua file csv tadi diharapkan kita dapat mendapatkan dataset yang benar-benar balance.

Proses concat (menggabungkan beberapa dataset ) file agar menjadi satu 
Simpan kedalam data menjadi format csv 
11. Kita dapat mendownloadnya sehingga data dapat digunakan untuk kebutuhan sentiment analisis 
12. Kami melakukan Scraping seperti cara diatas untuk tiga aplikasi ecommerce yang terkenal di Indonesia yaitu, Bukalapak, Shopee, dan
Tokopedia 
13. Setelah dataset terkumpul dari ketiga aplikasi, selanjutnya akan dilakukan merger dataset agar menjadi satu kesatuan dataset.
Setelah tahap scraping dataset selesai dan sudah menghasilkan dataset yang baru langkah selanjutnya yang dilakukan yaitu melakukan text processing dari dataset yang sudah dibuat. Berikut adalah tahapan yang saya lakukan dalam proses text preprocessing.
1. Mengimport library yang akan digunakan untuk proses text preprocessing

2. Hubungkan google colab dengan drive yang menyiman dataset

3. Meng-load dataset yang akan digunakan sesuai dengan tepat kita menyimpan dataset di google drive.

4. Melakukan proses EDA (Exploratory data analysis) yang bertujuan untuk mengekplorasi dataset yang kita gunakan.
Untuk mengetahui ukuran dan apakah ada data yang null dari dataset yang digunakan.

Mengetahui info dari dataset yang digunakan seperti type data pada dataset.

Melihat nilai unik yang ada pada dataset

Untuk mengetahui berapa jumlah data pada setiap nilai unik dari dataset kolom score.

Memvisualisasikan nilai score dengan menggunakan library seaborn.

Mengganti nama kolom score menjadi value dan kita lihat data awalnya.

5. Menerapkan label encoding untuk membuat fitur target menjadi numerik. Nilai value yang kurang dari sama dengan dua akan menjadi negative label dan nilai yang lebih dari sama dengan 4 akan menjadi positif label.

6. Setelah itu kita lakukan label encoder dan tranform label dari kolom value

7. Membagi data menjadi independen dan dependen. Variabel x kolom content akan variabel independen dan y menjadi variabel dependen yang berikan nilai dari value.

8. Meng-install library emoji dan stopword yang nantinya digunakan untuk menghapus emoji yang ada pada dataset dan untuk memlakukan proses stopword removal.

9. Membuat fungsi untuk menghapus karakter emoji yang terdapat di kolom content pada dataset.

10. Membuat fungsi clearEmoji yang digunakan sebagai cara untuk menghapus emoji sesuai dengan asccii nya.

11. Melakukan proses filtering data dengan menghapus karakter tulisan yang tidak diperlukan dengan menggukan library regex.

12. Melakukan proses lower case pada dataset. Dan melakukan stopword dalam sesuai dengan bahasa yang digunakan pada dataset yaitu bahasa indonesia.

13. Hasil akhir dari tahapan text preprocessing dataset sudah bersih tidak terdapat karaktek tertentu maupun emoji yang tidak diperlukan.

Itulah tahapan dari building dataset dan text preprocessing yang saya lakukan untuk project sentimen analisis mengenai kepuasan penggunaan aplikasi e-commerce di Indonesia dan langkah selanjutya yaitu pembuatan model yang dikerjakan oleh temen saya.
Informasi Course Terkait
Kategori: Natural Language ProcessingCourse: Dasar Pemrograman Natural Language Programming dengan Python



