
Indihome Sentiment Analysis
Muhamad Rizal Ridlo



Summary
Indihome sentiment analysis aims to understand how Indihome product performs in the customer's sight. We will look deeper into how society values indihome product.
Description
Background
Indonesia Digital Home (abbreviated IndiHome) is one of the service products from PT Telkom Indonesia (Persero) Tbk in the form of communication and data service packages such as home telephones (voice), internet (Internet on Fiber or High Speed Internet), and interactive television services. (UseeTV). cable, IPTV). Because of this offer, Telkom labels IndiHome as three services in one package (3-in-1) because apart from the internet, customers also get pay TV shows and telephone lines. Indihome service that we will discuss next is the internet service, since this service is most Indonesians are familiar with
Indihome sentiment analysis is utilised to understand indihome's product deeper and better. This can be used as an evaluation purpose for PT. Telkom Indonesia to fix the weaknesses of their product. Furthermore, this also can be used by other competitors to better understand Indihome's product and plot strategy to increase their revenue. Many things can be done by performing sentiment analysis.
Exploratory Data Analysis
The dataset number is 981 and it contains 3 labels, positive, neutral ,and negative, and written in Bahasa.

It can be seen that the dataset is relatively imbalanced. The label visualization shows that there are lots more of negative labels than neutral or positive labels. It can be sign that Indihome product needs improvement, since many people dislike this product, and the least number is the positive label.
Text Processing
- Lowercase and Substitution
- Lowercase aims to make our words not varying. If we are working with text processing, word ‘apple’ and ‘Apple’ has different representation, and not equal. We desire both words to have the exact same meaning by lowering the text.
- Substition aims to remove the special character and substitute it with white space or another substitution
2. Stemming and Tokenizing
- Stemming is used for reducing the inflection in words to their root forms
- Tokenizing is used for separating each word so it can be encoded into numerical form later
3. Removing the stop words
- Stop words removal is used to eliminate unimportant words, allowing applications to focus on the important words instead.
Dataset Visualization
After performing the dataset preprocessing, we can get a closer look lying within the dataset. Visualizing the most frequent words which appear in the entire dataset. First for the positive reviews, followed by neutral and negative reviews.
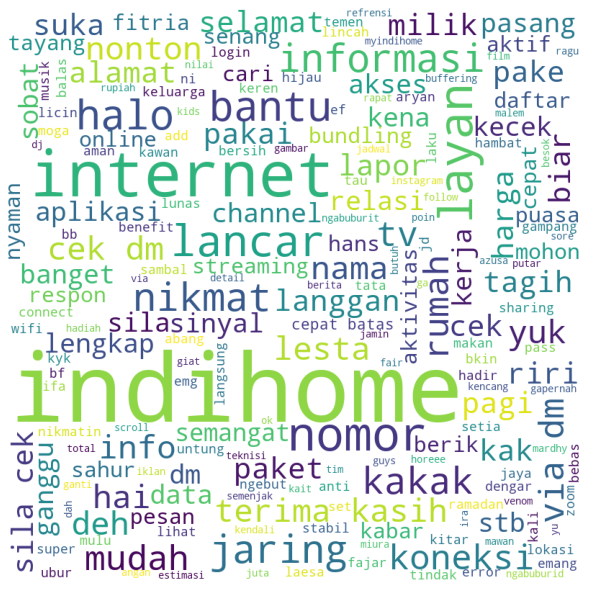
Below is the word cloud for positive review

The most frequent word that appears in positive sentiment is Indihome, internet, and nomor. It means if our sentence contains one of these words, chances are it will be classified as positive sentiment. This is followed by several positive words like terima kasih, nikmat, lancar, and so on. Since this class is the minority, thus we can not expect to gather much information about this class

The most frequent words that appear in neutral sentiment are indihome, internet, sobat, yuk, and followed by puasa, ramadan, tagih, pagi and many more. It gives us notion that most people with neutral sentiment will be inclined to tell stories, or ask for giveaway,rather than to complain or to compliment.

And this is the part in which Indihome should pay attention to, the most frequent words are indihome, ganggu, error, sinyal jelek, error and many more. It could be concluded that Indihome has issues in signalling, so many people complain about that.
Machine Learning Model
In this section, we are going to deep dive about how our ML model performs for specific task, in this case is sentiment analysis. We will use traditional method first which are KNN and Multinomial Naive Bayes.
- Splitting the data
- Splitting data becomes 75% training and the rest is testing data
2. TF-IDF Vectorizer
- Secondly, preprocess the data, by using TFIDF vectorizer, it is like counting how many words that appear and transform it using TF-IDF.
- There are several parameters, min_df means ignoring the words that occur less than 5 documents, max_df means ignoring the words that appear more than 80% of the document, sublinear_tf is applying the tf scaling, ngram_range means to vectorize one to bigram.
3. Hyperparameter Tuning
- Applying Grid Search CV to perform hyperparameter tuning in k-Nearest Neighbors and SVC
4. Create PIpeline (Count Vectorizer, Tfidf Transformer, SMOTE, and Multinomial NB)
- I add SMOTE in the pipeline, so it can better the model generalization and I decide to utilise Multinomial Naive Bayes to perform model prediction
Deep Learning Model
- Tokenizer and Padding
- We transform our words into numerical representation using texts_to_sequence in Tokenizer Keras, and use padding sequence to make our vector representation lenghts are equal
2. Embedding Layer and Spatial Dropout
- We use embedding layer which enables us to find the relationship between words that is difficult to capture. Spatial dropout here means to drop one feature at random to reduce the chance of overfitting.
3. LSTM
- LSTM is used to reduce the chance of vanishing gradient due to the long dependencies of vanilla RNN, and generally used in NLP to capture long dependencies such as subject and verb agreement that has long sentence in between.

The loss goes down as the epochs increase, and the training loss can be lesser than the validation loss. It might be the sign of overfitting.

The accuracy is higher as the epochs increase.
Evaluation Metrics
We will evaluate the model using some metrics, the favorable metrics are accuracy and F1-score. This visualization uses Confusion Matrix. Confusion Matrix can easily visualize how many prediction turns right and wrong.
Multinomial NB

kNN

SVC

Neural Network

Model selection is considered using accuracy, and F1-score.
As the figure shows, 0.89 in deep learning model accuracy seems to be decent. However, the model could not predict class 1. In this case, we would prefer to have Multinomial NB as our model selection, since even if its accuracy is not as superior as KNN with hyperparameter tuning, but it could predict class 1 much better than other models, and has 0.92 F1 score in predicting class 2 similar to KNN's
Conclusion :
Telkom Indonesia needs to improve their signalling system so their service is much more stable and its subscriber will not churn and choose another product. Multinomial NB has much decent in predicting class 1 or positive sentiment than other models.
Informasi Course Terkait
Kategori: Artificial IntelligenceCourse: Persiapan Ujian Sertifikasi Internasional DSBIZ - AIBIZ
