
Scraping Website bisa.business dengan Python
Bintang Fajar Julio
Summary
Web scraping merupakan salah satu metode untuk mencari dataset dengan melakukan pencarian informasi digital dari sebuah website dengan mengambil intisari informasi yang diinginkan dari struktur HTML nya. Pada portofolio kali ini akan membahas secara singkat percobaan dari metode web scraping terhadap nama course dari kelas yang ada di platform website bisa.business
Description
Mengapa perlu web scraping?
Tahap preprocessing merupakan tahapan paling krusial dalam pembelajaran mesin karena pada dasarnya pada tahap ini kita akan memberikan material atau pengetahuan yang akan dijadikan bahan pembelajaran oleh komputer agar dapat menjadi AI. Pengetahuan tersebut disebut dengan dataset yang mana dataset dapat diperoleh dari berbagai sumber dan dapat dicari lalu dikumpulkan dengan berbagai metode salah satunya adalah web scraping. Web scraping merupakan salah satu metode untuk mencari dataset dengan melakukan pencarian informasi digital dari sebuah website dengan mengambil intisari informasi yang diinginkan dari struktur HTML nya.
Python sebagai alat web scrapping
Python dapat dipergunakan untuk melakukan web scraping karena dengan bantuan berbagai library-library berikut ini:
- selenium => webdriver, sebagai loader konten website
- bs4 => BeautifulSoup, sebagai selector tag HTML
- pandas, sebagai pengekstrak data menjadi file dataset (.csv)
Dengan demikian, web scrapping dapat dilakukan dengan mudah hanya dengan bermodalkan 20 baris kode rapih dari program python.
Tahapan dan Penjelasan Program
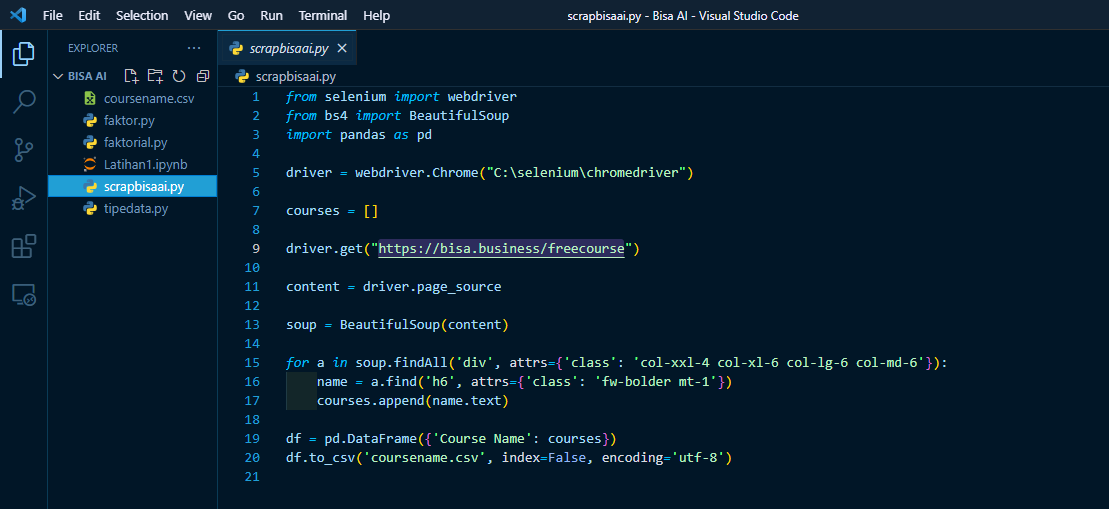
1. Import library yang diperlukan

2. Deklarasikan variabel driver lalu isi dengan method dari library, yaitu webdriver.Chrome untuk memuat file menggunakan browser chrome dengan cara mengisi parameter method tersebut dengan path aplikasi chromedriver.exe menyesuaikan lokasi penyimpanan masing-masing


3. Deklarasikan variabel list courses untuk menampung data scraping nantinya, lalu tambahkan method driver.get dengan parameter berisi url website target scraping.
Kemudian dilanjutkan dengan deklarasi variabel content untuk menyimpan hasil method driver.page_source yang dipergunakan untuk membuka dan memuat laman website berdasarkan url yang sudah diisi pada method driver.get

Kemudian deklarasikan variabel soup berisi constructor dari library BeautifulSoup dengan parameter content yang berisi hasil muatan laman website
4. Langkah terakhir adalah dengan melakukan selector tag menggunakan method soup.findAll yang digunakan untuk memuat semua tag div dari isi url website yang bernama class spesifik: col-xxl-4 col-xl-6 col-lg-6 col-md-6 yang merupakan struktur tag HTML untuk card dari masing-masing course.
Tentu saja hasilnya akan >1 sehingga akan bertipe data list yang dapat kita iterasikan dengan looping for untuk menyeleksi nama course dari masing-masing card secara efisien dengan menggunakan method a.find pada tiap iterasi dengan target tag h6 dengan class spesifik: fw-bolder mt-1 yang merupakan tag dari judul course yang kemudian akan ditampung pada variabel name untuk disimpan ke varibel list courses dengan method .append agar tersimpan ke index terbelakang.
Tahapan paling penting adalah dengan menambahkan method .text ketika melakukan .append karena untuk membersihkan tag dan menyisakan teks yang diapit oleh tag tersebut.

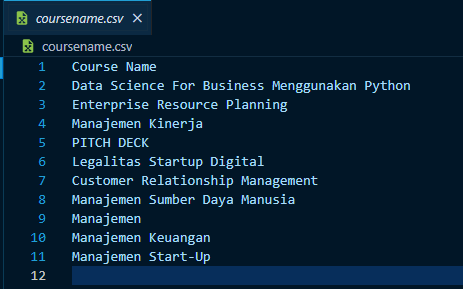
Kemudian pandas digunakan untuk mengekstrak data menjadi .csv dengan isi hasil scraping nama course sebagai berikut:

Informasi Course Terkait
Kategori: Artificial IntelligenceCourse: Information Retrieval for Beginner
