
stastistika
Risqa Ciety Windari



Summary
After login, you can download your Kaggle API credentials at https://www.kaggle.com/settings by clicking on the "Create New Token" button under the "API" section.
You have four different options to authenticate. Note that if you use kaggle-api (the kaggle command-line tool) you have already done Option 3 and can skip this.
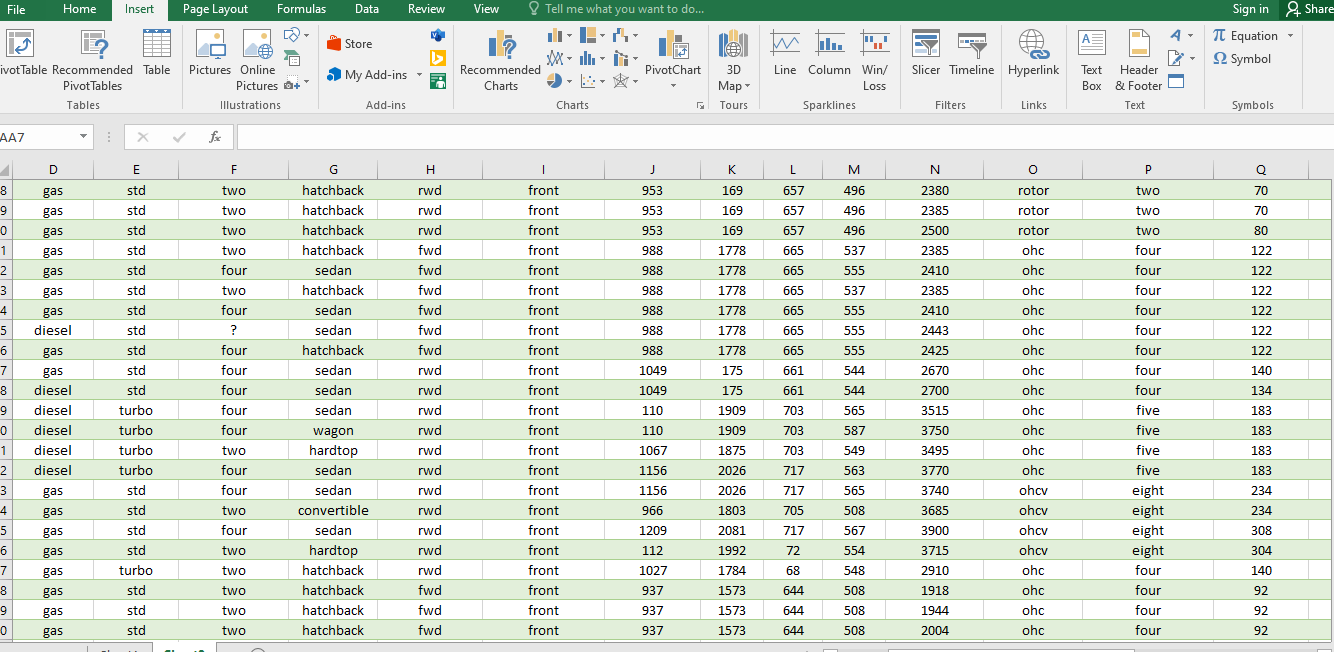
Statistika deskriptif adalah metode-metode yang berkaitan dengan pengumpulan dan penyajian suatu data sehingga memberikan informasi yang berguan. Disini saya akan memberikan sebuah hipotesis dari sebuah data sehingga menghasilkan informasi yang berguna diambil berdasarkan atribut yang telah ditentukan. Data yang dugunakan pada hipotesis ini diambil dari sebuah website yaitu kaggel.com.
Description
Option 1: Calling kagglehub.login()
This will prompt you to enter your username and token:
import kagglehub
kagglehub.login()
Option 2: Read credentials from environment variables
You can also choose to export your Kaggle username and token to the environment:
export KAGGLE_USERNAME=datadinosaur
export KAGGLE_KEY=xxxxxxxxxxxxxx
Option 3: Read credentials from kaggle.json
Store your kaggle.json credentials file at ~/.kaggle/kaggle.json.
Alternatively, you can set the KAGGLE_CONFIG_DIR environment variable to change this location to $KAGGLE_CONFIG_DIR/kaggle.json.
Note for Windows users: The default directory is %HOMEPATH%/kaggle.json.
Option 4: Read credentials from Google Colab secrets
Store your username and key token as Colab secrets KAGGLE_USERNAME and KAGGLE_KEY.
Instructions on adding secrets in both Colab and Colab Enterprise can be found in this article.
Download Model
The following examples download the answer-equivalence-bem variation of this Kaggle model: https://www.kaggle.com/models/google/bert/tensorFlow2/answer-equivalence-bem
import kagglehub # Download the latest version. kagglehub.model_download('google/bert/tensorFlow2/answer-equivalence-bem') # Download a specific version. kagglehub.model_download('google/bert/tensorFlow2/answer-equivalence-bem/1') # Download a single file. kagglehub.model_download('google/bert/tensorFlow2/answer-equivalence-bem', path='variables/variables.index') # Download a model or file, even if previously downloaded to cache. kagglehub.model_download('google/bert/tensorFlow2/answer-equivalence-bem', force_download=True)
Upload Model
Uploads a new variation (or a new variation's version if it already exists).
import kagglehub # For example, to upload a new variation to this model: # - https://www.kaggle.com/models/google/bert/tensorFlow2/answer-equivalence-bem # # You would use the following handle: `google/bert/tensorFlow2/answer-equivalence-bem` handle = '<KAGGLE_USERNAME>/<MODEL>/<FRAMEWORK>/<VARIATION>' local_model_dir = 'path/to/local/model/dir' kagglehub.model_upload(handle, local_model_dir) # You can also specify some version notes (optional) kagglehub.model_upload(handle, local_model_dir, version_notes='improved accuracy') # You can also specify a license (optional) kagglehub.model_upload(handle, local_model_dir, license_name='Apache 2.0') # You can also specify a list of patterns for files/dirs to ignore. # These patterns are combined with `kagglehub.models.DEFAULT_IGNORE_PATTERNS` # to determine which files and directories to exclude. # To ignore entire directories, include a trailing slash (/) in the pattern. kagglehub.model_upload(handle, local_model_dir, ignore_patterns=["original/", "*.tmp"])
Load Dataset
Loads a file from a Kaggle Dataset into a python object based on the selected KaggleDatasetAdapter:
- KaggleDatasetAdapter.PANDAS → pandas DataFrame (or multiple given certain files/settings)
- KaggleDatasetAdapter.HUGGING_FACE→ Hugging Face Dataset
- KaggleDatasetAdapter.POLARS → polars LazyFrame or DataFrame (or multiple given certain files/settings)
NOTE: To use these adapters, you must install the optional dependencies (or already have them available in your environment)
- KaggleDatasetAdapter.PANDAS → pip install kagglehub[pandas-datasets]
- KaggleDatasetAdapter.HUGGING_FACE→ pip install kagglehub[hf-datasets]
- KaggleDatasetAdapter.POLARS→ pip install kagglehub[polars-datasets]
KaggleDatasetAdapter.PANDAS
This adapter supports the following file types, which map to a corresponding pandas.read_* method:
| File Extension | pandas Method |
|---|---|
| .csv, .tsv1 | pandas.read_csv |
| .json, .jsonl2 | pandas.read_json |
| .xml | pandas.read_xml |
| .parquet | pandas.read_parquet |
| .feather | pandas.read_feather |
| .sqlite, .sqlite3, .db, .db3, .s3db, .dl33 | pandas.read_sql_query |
| .xls, .xlsx, .xlsm, .xlsb, .odf, .ods, .odt4 | pandas.read_excel |
dataset_load also supports pandas_kwargs which will be passed as keyword arguments to the pandas.read_* method. Some examples include:
import kagglehub from kagglehub import KaggleDatasetAdapter # Load a DataFrame with a specific version of a CSV df = kagglehub.dataset_load( KaggleDatasetAdapter.PANDAS, "unsdsn/world-happiness/versions/1", "2016.csv", ) # Load a DataFrame with specific columns from a parquet file df = kagglehub.dataset_load( KaggleDatasetAdapter.PANDAS, "robikscube/textocr-text-extraction-from-images-dataset", "annot.parquet", pandas_kwargs={"columns": ["image_id", "bbox", "points", "area"]} ) # Load a dictionary of DataFrames from an Excel file where the keys are sheet names # and the values are DataFrames for each sheet's data. NOTE: As written, this requires # installing the default openpyxl engine. df_dict = kagglehub.dataset_load( KaggleDatasetAdapter.PANDAS, "theworldbank/education-statistics", "edstats-excel-zip-72-mb-/EdStatsEXCEL.xlsx", pandas_kwargs={"sheet_name": None}, ) # Load a DataFrame using an XML file (with the natively available etree parser) df = dataset_load( KaggleDatasetAdapter.PANDAS, "parulpandey/covid19-clinical-trials-dataset", "COVID-19 CLinical trials studies/COVID-19 CLinical trials studies/NCT00571389.xml", pandas_kwargs={"parser": "etree"}, ) # Load a DataFrame by executing a SQL query against a SQLite DB df = kagglehub.dataset_load( KaggleDatasetAdapter.PANDAS, "wyattowalsh/basketball", "nba.sqlite", sql_query="SELECT person_id, player_name FROM draft_history", )
KaggleDatasetAdapter.HUGGING_FACE
The Hugging Face Dataset provided by this adapater is built exclusively using Dataset.from_pandas. As a result, all of the file type and pandas_kwargs support is the same as KaggleDatasetAdapter.PANDAS. Some important things to note about this:
- Because Dataset.from_pandas cannot accept a collection of DataFrames, any attempts to load a file with pandas_kwargs that produce a collection of DataFrames will result in a raised exception
- hf_kwargs may be provided, which will be passed as keyword arguments to Dataset.from_pandas
- Because the use of pandas is transparent when pandas_kwargs are not needed, we default to False for preserve_index—this can be overridden using hf_kwargs
Some examples include:
import kagglehub from kagglehub import KaggleDatasetAdapter # Load a Dataset with a specific version of a CSV, then remove a column dataset = kagglehub.dataset_load( KaggleDatasetAdapter.HUGGING_FACE, "unsdsn/world-happiness/versions/1", "2016.csv", ) dataset = dataset.remove_columns('Region') # Load a Dataset with specific columns from a parquet file, then split into test/train splits dataset = kagglehub.dataset_load( KaggleDatasetAdapter.HUGGING_FACE, "robikscube/textocr-text-extraction-from-images-dataset", "annot.parquet", pandas_kwargs={"columns": ["image_id", "bbox", "points", "area"]} ) dataset_with_splits = dataset.train_test_split(test_size=0.8, train_size=0.2) # Load a Dataset by executing a SQL query against a SQLite DB, then rename a column dataset = kagglehub.dataset_load( KaggleDatasetAdapter.HUGGING_FACE, "wyattowalsh/basketball", "nba.sqlite", sql_query="SELECT person_id, player_name FROM draft_history", ) dataset = dataset.rename_column('season', 'year')
KaggleDatasetAdapter.POLARS
This adapter supports the following file types, which map to a corresponding polars.scan_* or polars.read_* method:
| File Extension | polars Method |
|---|---|
| .csv, .tsv1 | polars.scan_csv or polars.read_csv |
| .json | polars.read_json |
| .jsonl | polars.scan_ndjson or polars.read_ndjson |
| .parquet | polars.scan_parquet or polars.read_parquet |
| .feather | polars.scan_ipc or polars.read_ipc |
| .sqlite, .sqlite3, .db, .db3, .s3db, .dl32 | polars.read_database |
| .xls, .xlsx, .xlsm, .xlsb, .odf, .ods, .odt3 | polars.read_excel |
dataset_load also supports polars_kwargs which will be passed as keyword arguments to the polars.scan_* or polars_read_* method.
LazyFrame vs DataFrame
Per polars documentation, LazyFrame "allows for whole-query optimisation in addition to parallelism, and is the preferred (and highest-performance) mode of operation for polars." As such, scan_* methods are used by default whenever possible--and when not possible the result of the read_* method is returned after calling .lazy(). If a DataFrame is preferred, dataset_load supports an optional polars_frame_type and PolarsFrameType.DATA_FRAME may be passed in. This will force a read_* method to be used with no .lazy() call. NOTE: For file types that support scan_*, changing the polars_frame_type may affect which polars_kwargs are acceptable to the underlying method since it will force a read_* method to be used rather than a scan_* method.
Some examples include:
import kagglehub from kagglehub import KaggleDatasetAdapter, PolarsFrameType # Load a LazyFrame with a specific version of a CSV lf = kagglehub.dataset_load( KaggleDatasetAdapter.POLARS, "unsdsn/world-happiness/versions/1", "2016.csv", ) # Load a LazyFramefrom a parquet file, then select specific columns lf = kagglehub.dataset_load( KaggleDatasetAdapter.POLARS, "robikscube/textocr-text-extraction-from-images-dataset", "annot.parquet", ) lf.select(["image_id", "bbox", "points", "area"]).collect() # Load a DataFrame with specific columns from a parquet file df = kagglehub.dataset_load( KaggleDatasetAdapter.POLARS, "robikscube/textocr-text-extraction-from-images-dataset", "annot.parquet", polars_frame_type=PolarsFrameType.DATA_FRAME, polars_kwargs={"columns": ["image_id", "bbox", "points", "area"]} ) # Load a dictionary of LazyFrames from an Excel file where the keys are sheet names # and the values are LazyFrames for each sheet's data. NOTE: As written, this requires # installing the default fastexcel engine. lf_dict = kagglehub.dataset_load( KaggleDatasetAdapter.POLARS, "theworldbank/education-statistics", "edstats-excel-zip-72-mb-/EdStatsEXCEL.xlsx", # sheet_id of 0 returns all sheets polars_kwargs={"sheet_id": 0}, ) # Load a LazyFrame by executing a SQL query against a SQLite DB lf = kagglehub.dataset_load( KaggleDatasetAdapter.POLARS, "wyattowalsh/basketball", "nba.sqlite", sql_query="SELECT person_id, player_name FROM draft_history", )
Download Dataset
The following examples download the Spotify Recommendation Kaggle dataset: https://www.kaggle.com/datasets/bricevergnou/spotify-recommendation
import kagglehub # Download the latest version. kagglehub.dataset_download('bricevergnou/spotify-recommendation') # Download a specific version. kagglehub.dataset_download('bricevergnou/spotify-recommendation/versions/1') # Download a single file. kagglehub.dataset_download('bricevergnou/spotify-recommendation', path='data.csv') # Download a dataset or file, even if previously downloaded to cache. kagglehub.dataset_download('bricevergnou/spotify-recommendation', force_download=True)
Upload Dataset
Uploads a new dataset (or a new version if it already exists).
import kagglehub # For example, to upload a new dataset (or version) at: # - https://www.kaggle.com/datasets/bricevergnou/spotify-recommendation # # You would use the following handle: `bricevergnou/spotify-recommendation` handle = '<KAGGLE_USERNAME>/<DATASET>' local_dataset_dir = 'path/to/local/dataset/dir' # Create a new dataset kagglehub.dataset_upload(handle, local_dataset_dir) # You can then create a new version of this existing dataset and include version notes (optional). kagglehub.dataset_upload(handle, local_dataset_dir, version_notes='improved data') # You can also specify a list of patterns for files/dirs to ignore. # These patterns are combined with `kagglehub.datasets.DEFAULT_IGNORE_PATTERNS` # to determine which files and directories to exclude. # To ignore entire directories, include a trailing slash (/) in the pattern. kagglehub.dataset_upload(handle, local_dataset_dir, ignore_patterns=["original/", "*.tmp"])
Download Competition
The following examples download the Digit Recognizer Kaggle competition: https://www.kaggle.com/competitions/digit-recognizer
import kagglehub # Download the latest version. kagglehub.competition_download('digit-recognizer') # Download a single file. kagglehub.competition_download('digit-recognizer', path='train.csv') # Download a competition or file, even if previously downloaded to cache. kagglehub.competition_download('digit-recognizer', force_download=True)
Download Notebook Outputs
The following examples download the Titanic Tutorial notebook output: https://www.kaggle.com/code/alexisbcook/titanic-tutorial
import kagglehub # Download the latest version. kagglehub.notebook_output_download('alexisbcook/titanic-tutorial') # Download a specific version of the notebook output. kagglehub.notebook_output_download('alexisbcook/titanic-tutorial/versions/1') # Download a single file. kagglehub.notebok_output_download('alexisbcook/titanic-tutorial', path='submission.csv')
Install Utility Script
The following example installs the utility script Physionet Challenge Utility Script Utility Script: https://www.kaggle.com/code/bjoernjostein/physionet-challenge-utility-script. Using this command allows the code from this script to be available in your python environment.
import kagglehub # Install the latest version. kagglehub.utility_script_install('bjoernjostein/physionet-challenge-utility-script')
Options
Change the default cache folder
By default, kagglehub downloads files to your home folder at ~/.cache/kagglehub/.
You can override this path by setting the KAGGLEHUB_CACHE environment variable.
Development
Prequisites
We use hatch to manage this project.
Follow these instructions to install it.
Tests
# Run all tests for current Python version. hatch test # Run all tests for all Python versions. hatch test --all # Run all tests for a specific Python version. hatch test -py 3.11 # Run a single test file hatch test tests/test_<SOME_FILE>.py
Integration Tests
To run integration tests on your local machine, you need to set up your Kaggle API credentials. You can do this in one of these two ways described in the earlier sections of this document. Refer to the sections:
After setting up your credentials by any of these methods, you can run the integration tests as follows:
# Run all tests hatch test integration_tests
Run kagglehub from source
Option 1: Execute a one-liner of code from the command line
# Download a model & print the path hatch run python -c "import kagglehub; print('path: ', kagglehub.model_download('google/bert/tensorFlow2/answer-equivalence-bem'))"
Option 2: Run a saved script from the /tools/scripts directory
# This runs the same code as the one-liner above, but reads it from a # checked in script located at tool/scripts/download_model.py hatch run python tools/scripts/download_model.py
Option 3: Run a temporary script from the root of the repo
Any script created at the root of the repo is gitignore'd, so they're just temporary scripts for testing in development. Placing temporary scripts at the root makes the run command easier to use during local development.
# Test out some new changes hatch run python test_new_feature.py
Lint / Format
# Lint check hatch run lint:style hatch run lint:typing hatch run lint:all # for both # Format hatch run lint:fmt
Coverage report
hatch test --cover
Build
hatch build
Running hatch commands inside Docker
This is useful to run in a consistent environment and easily switch between Python versions.
The following shows how to run hatch run lint:all but this also works for any other hatch commands:
# Use default Python version ./docker-hatch run lint:all # Use specific Python version (Must be a valid tag from: https://hub.docker.com/_/python) ./docker-hatch -v 3.9 run lint:all # Run test in docker with specific Python version ./docker-hatch -v 3.9 test # Run python from specific environment (e.g. one with optional dependencies installed) ./docker-hatch run extra-deps-env:python -c "print('hello world')" # Run commands with other root-level hatch options (everything after -- gets passed to hatch) ./docker-hatch -v 3.9 -- -v env create debug-env-with-verbose-logging
VS Code setup
Prerequisites
Install the recommended extensions.
Instructions
Configure hatch to create virtual env in project folder.
hatch config set dirs.env.virtual .env
After, create all the python environments needed by running hatch test --all.
Finally, configure vscode to use one of the selected environments: cmd + shift + p -> python: Select Interpreter -> Pick one of the folders in ./.env
Support
The kagglehub library has configured automatic logging for console. For file based logging, setting the KAGGLE_LOGGING_ENABLED=1 environment variable will output logs to a directory. The default log destination is resolved via the os.path.expanduser
The table below contains possible locations:
| os | log path |
|---|---|
| osx | /user/$USERNAME/.kaggle/logs/kagglehub.log |
| linux | ~/.kaggle/logs/kagglehub.log |
| windows | C:\Users\%USERNAME%\.kaggle\logs\kagglehub.log |
If needed, the root log directory can be overriden using the following environment variable: KAGGLE_LOGGING_ROOT_DIR
Please include the log to help troubleshoot issues
Informasi Course Terkait
Kategori: Algoritma dan PemrogramanCourse: Statistika dan Probabilitas
