
Classification Data Using Naive Bayes Algorithm
Masayu Anandita Prameswari


Summary
Classification dalam data science berarti proses memprediksi kelas atau kategori data dengan memanfaatkan nilai yang ada pada data. Algoritma machine learning sendiri dibagi menjadi dua, yaitu supervised dan unsupervised learning. Portofolio ini menggunakan Algoritma Naive bayes untuk memprediksi apakah pelanggan tertarik untuk membeli kendaraan baru atau tidak berdasarkan data pelanggan pada dealer.
Description
Klasifikasi ini untuk memprediksi apakah pelanggan tertarik untuk membeli kendaraan baru atau tidak berdasarkan data pelanggan yang ada.
A. Eksplorasi dan Persiapan Data
- Library Yang digunakan

- Membaca dataset dan tipe data
Dataset kendaraan memiliki beberapa atribut diantaranya adalah id, Jenis_Kelamin, Umur, SIM, Kode_Daerah, Sudah_Asuransi, Umur_Kendaraan, Kendaraan_Rusak, Premi, Kanal_Penjualan, Lama_Berlangganan, Tertarik.


- Drop useless atribut dan mengganti categorical kolom
Menghapus colom “id” karena tidak dibutuhkan

Kemudian mengganti colom kategorikal menjadi numerical

Kolom yang telah dirubah menjadi seperti ini

- Mising value handling
Selanjutnya adalah memastikan bahwa tidak ada data kosong/NaN pada setiap feature

Berikut data yang sudah tidak memiliki NaN value

- Pembagian Feature
Membagi data menjadi all_feature_data, cetgorical_data dan continues_data untuk dilakukan perbandingan

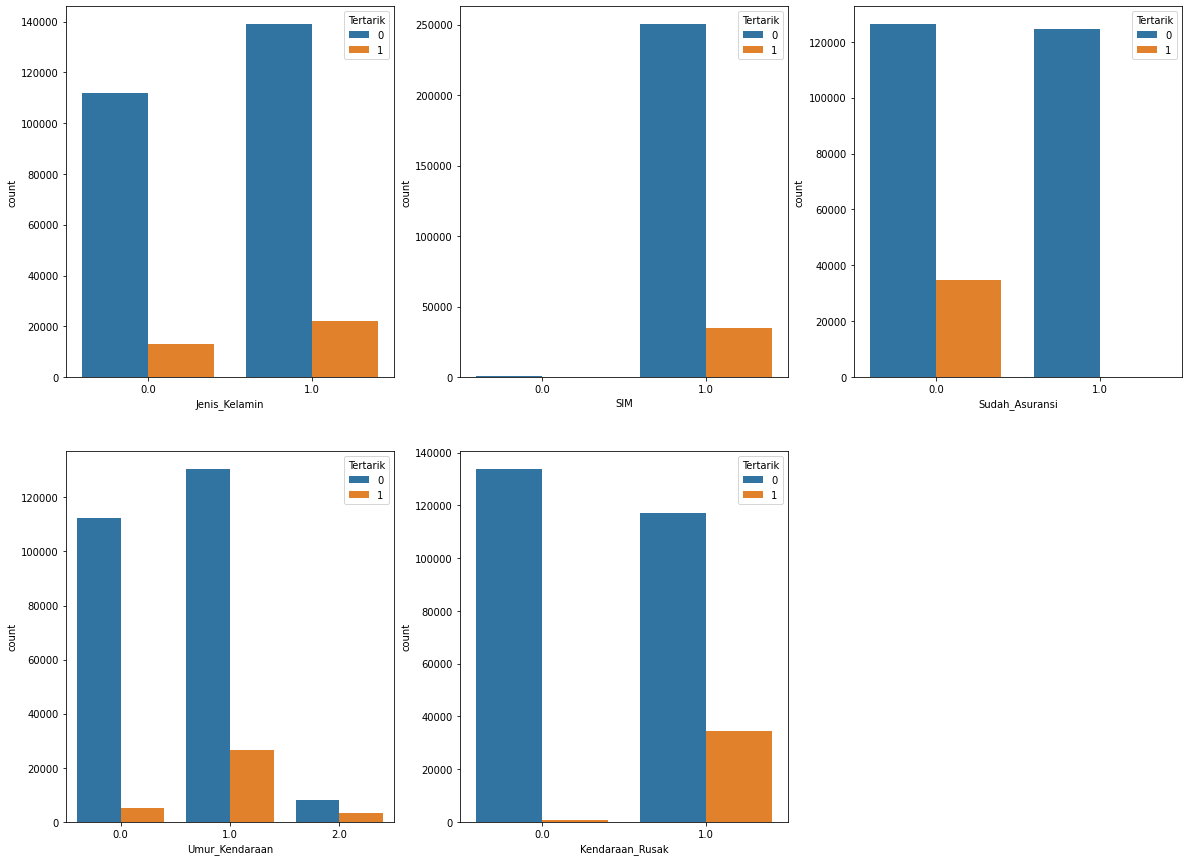
- Visualisasi data categorical
Berikut merupakan visualisasi dari data categorical

- Visualisasi data numerical
Berikut visualisasi dari data numerical

- Mempersiapkan data train dan data test
Disini saya membedakan data continu saja dengan all_feature data untuk perbandingan akurasi yang didapat dari model naive bayes.

- Data Scaling
Scalling bertujuan untuk menyamaratakan nilai dari feature feature yang ada. Saya menggunakan standardscaler. Disini saya melakukan scalling 2 data set sekaligus yaitu data kendaraan_train dan data kendaraan_test sehingga tidak memerlukan split data train dan data test.

B. Pemodelan
Pada pemodelan saya menggunakan metode naive bayes, cara kerja dari metode Naïve Bayes Classifier sendiri adalah menghitung peluang dari satu class dari masing-masing kelompok atribut yang ada dan menentukan kelas mana yang paling optimal.

C. Hasil
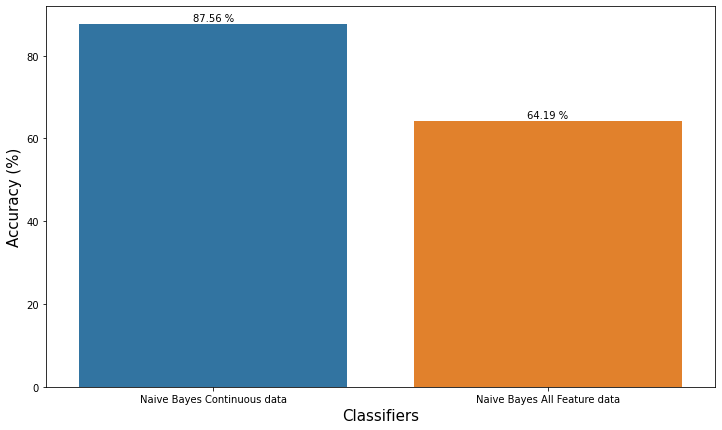
Didapatkan bahwa, terdapat perbedaan hasil akurasi dari model naive bayes yang menggunakan continu data dengan all feature data karena terdapat perbedaan saat menggunakan data continu dan saat menggunakan keseluruhan feature yang ada


Terlihat plot bahwa untuk hasil akurasi menggunakan data continu memiliki nilai akurasi yang tinggi, sedangkan untuk all feature lebih rendah

Didapatkan hasil bahwa model Naive Bayes yang menggunakan continu data memiliki nilai akurasi yang lebih tinggi yaitu 87.56% dibandingkan dengan menggunakan all feature yaitu 64.19%. Dapat disimpulkan bahwa Naive bayes bekerja lebih baik dengan menggunakan data bersifat continue.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Data Science
