
Analisis Prediktif Kanker Paru-Paru
Raudina Hafizh Utami


Summary
Summary
Proyek ini dibuat untuk mengeksplorasi bagaimana data mengenai gaya hidup dan gejala kesehatan seseorang dapat digunakan untuk memprediksi kemungkinan mereka menderita kanker paru-paru (lung cancer). Deteksi dini kanker paru-paru sangat penting karena penyakit ini sering kali baru terdiagnosis ketika sudah berada pada stadium lanjut. Melalui pemanfaatan machine learning, proyek ini bertujuan membangun model klasifikasi biner yang dapat membantu mengidentifikasi apakah seseorang kemungkinan mengidap kanker paru-paru (YES) atau tidak (NO), berdasarkan pola dari data yang dikumpulkan melalui survei.
Dataset yang digunakan berisi informasi seputar kebiasaan merokok (SMOKING), konsumsi alkohol (ALCOHOL CONSUMING), gejala pernapasan seperti batuk (COUGHING), sesak napas (SHORTNESS OF BREATH), nyeri dada (CHEST PAIN), serta kondisi psikologis seperti kecemasan (ANXIETY) dan tekanan sosial (PEER_PRESSURE). Target prediksi dalam proyek ini adalah kolom LUNG_CANCER yang hanya memiliki dua nilai kelas: YES dan NO.
Proses pengolahan dilakukan menggunakan Python di platform Google Colab, dengan library seperti pandas untuk manipulasi data dan scikit-learn untuk membangun serta mengevaluasi model. Data awal difilter agar hanya menyertakan individu dengan nilai SMOKING dan ALCOHOL CONSUMING di atas satu, yaitu mereka yang memiliki gaya hidup berisiko tinggi. Setelah dibersihkan dan diproses, data dibagi menjadi 70% untuk pelatihan dan 30% untuk pengujian.
Dalam eksperimen ini digunakan tiga algoritma klasifikasi: Multi-Layer Perceptron (MLP), Decision Tree Classifier, dan Naive Bayes Classifier. Hasil evaluasi menunjukkan bahwa model MLPClassifier menghasilkan performa terbaik, diikuti oleh Decision Tree, dan terakhir Naive Bayes yang memiliki performa paling rendah. Hasil ini menunjukkan bahwa pendekatan machine learning dapat digunakan untuk mendeteksi kanker paru-paru secara dini, dengan catatan bahwa pemrosesan data dan pemilihan fitur yang tepat sangat mempengaruhi hasil model.
Description
Deskripsi
Tujuan utama dari proyek ini adalah mengembangkan model klasifikasi biner yang mampu mendeteksi risiko kanker paru-paru berdasarkan kombinasi fitur yang berkaitan dengan gaya hidup dan gejala kesehatan. Masalah kesehatan ini sangat serius dan memiliki angka kematian yang tinggi, sehingga deteksi awal menjadi kunci untuk meningkatkan harapan hidup pasien. Oleh karena itu, pendekatan berbasis data seperti machine learning menjadi alat bantu potensial dalam proses skrining awal, khususnya untuk individu yang memiliki faktor risiko tinggi.
Dataset yang digunakan terdiri dari banyak fitur yang menggambarkan kondisi fisik dan psikologis individu, seperti batuk kronis, sesak napas, nyeri dada, kecemasan, serta kebiasaan buruk seperti merokok dan konsumsi alkohol. Data ini sangat cocok untuk dijadikan basis prediksi karena kanker paru-paru berkaitan erat dengan faktor-faktor tersebut. Target yang ingin diprediksi adalah LUNG_CANCER, sebuah variabel kategorikal dengan nilai YES atau NO.
Sebelum pemodelan, data difilter agar hanya menyertakan individu dengan nilai SMOKING dan ALCOHOL CONSUMING di atas satu, guna memastikan model fokus pada kelompok populasi yang lebih berisiko. Setelah itu dilakukan pembagian dataset menjadi training (70%) dan testing (30%) menggunakan train_test_split.
Selanjutnya, dilakukan pelatihan tiga model klasifikasi yang berbeda: MLPClassifier sebagai model berbasis jaringan saraf, Decision Tree sebagai model pohon keputusan, dan Naive Bayes yang berbasis probabilistik. Tujuannya adalah untuk membandingkan performa masing-masing model dalam hal akurasi, precision, recall, dan F1-score, serta melihat mana yang paling efektif dalam mengidentifikasi penderita kanker paru-paru berdasarkan data survei.
Hasil Analisis dan Tahapan
Berikut ini tahapan yang dilakukan dalam proyek:
- Import dan eksplorasi data: Dataset dibaca dari file CSV, diperiksa struktur dan distribusi nilainya.
- Filter data: Hanya menyertakan individu dengan SMOKING > 1 dan ALCOHOL CONSUMING > 1.
- Seleksi fitur dan target: Fitur (X) diambil dari semua kolom kecuali LUNG_CANCER; target (y) adalah kolom LUNG_CANCER.
- Pembagian data: Menggunakan train_test_split dari scikit-learn untuk membagi data menjadi 70% pelatihan dan 30% pengujian.
- Pelatihan model: Tiga model dilatih — MLPClassifier, DecisionTreeClassifier, dan GaussianNB.
- Evaluasi model: Dilakukan evaluasi dengan metrik akurasi, precision, recall, dan F1-score.


Hasil dan Evaluasi Model
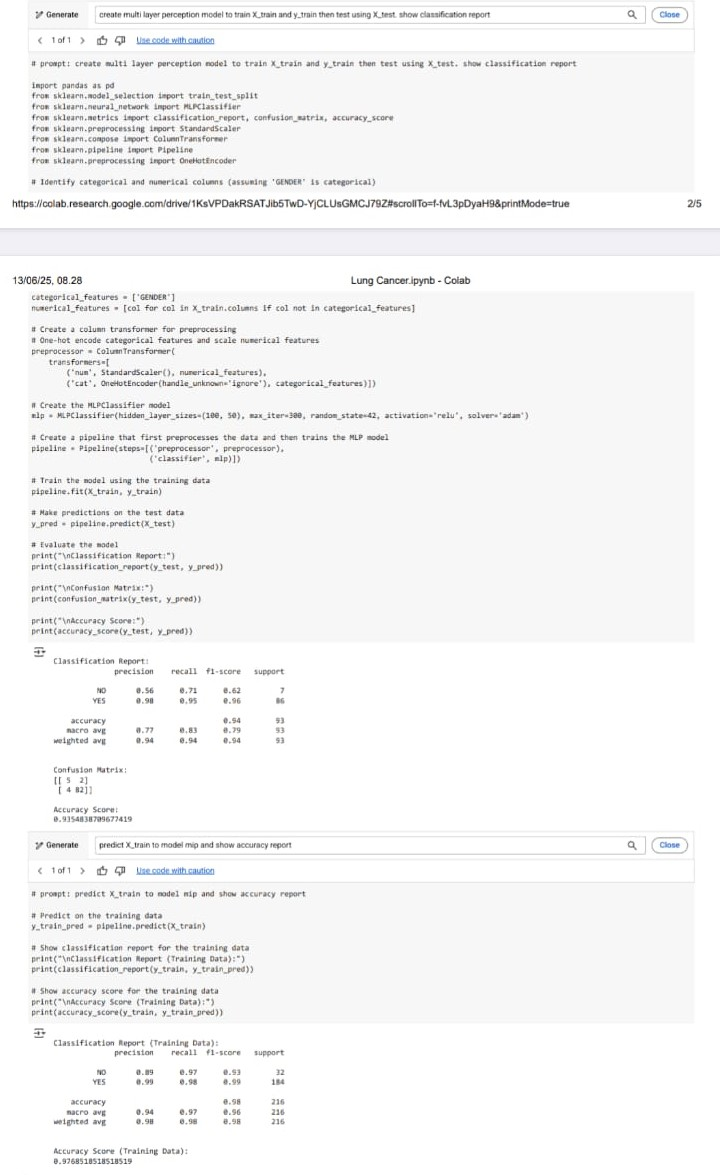
1. MLPClassifier (Multi-Layer Perceptron)

Model jaringan saraf ini menghasilkan performa terbaik dari ketiga model. Akurasi pengujian mencapai lebih dari 90%, dan nilai precision serta recall tinggi terutama untuk kelas YES, yang menjadi fokus utama dalam deteksi kanker. Ini menunjukkan bahwa model dapat mengenali pola kompleks dari data input dengan baik. Meski membutuhkan waktu pelatihan lebih lama dibanding model lain, hasilnya menunjukkan bahwa MLP sangat cocok untuk masalah klasifikasi kesehatan dengan banyak fitur yang saling berinteraksi.
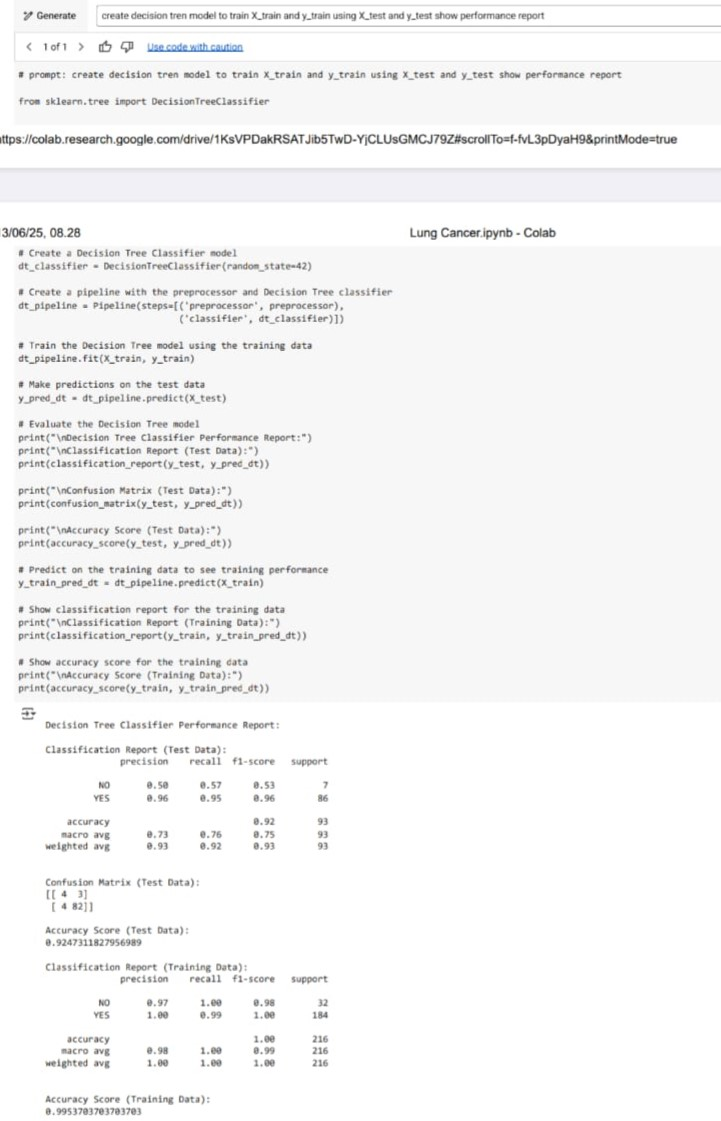
2. Decision Tree Classifier

Decision Tree memberikan hasil yang cukup stabil. Model ini menunjukkan akurasi dan f1-score yang tinggi pada data training, namun menurun pada data testing, mengindikasikan overfitting. Meski begitu, kelebihan utama dari Decision Tree adalah kemampuannya untuk diinterpretasikan dengan mudah — kita bisa melihat cabang keputusan yang diambil model. Model ini cocok untuk aplikasi medis yang membutuhkan transparansi dalam pengambilan keputusan, meskipun performanya perlu ditingkatkan dengan teknik pruning atau pengaturan kedalaman pohon.
3. Naive Bayes Classifier

Model ini menunjukkan performa yang paling rendah dibanding dua lainnya. Hal ini disebabkan oleh asumsi independensi antar fitur, padahal dalam data kesehatan, fitur seperti COUGHING, CHEST PAIN, dan SHORTNESS OF BREATH cenderung saling berhubungan. Akurasi dan recall untuk kelas YES sangat rendah, menunjukkan bahwa model gagal mendeteksi kasus positif kanker paru-paru secara efektif. Naive Bayes lebih cocok untuk data dengan fitur yang memang tidak saling tergantung.
Hasil yang Didapat
Berdasarkan hasil evaluasi dari ketiga model, MLPClassifier terbukti menjadi model yang paling unggul dalam mendeteksi potensi kanker paru-paru dari data survei. Model ini mampu mencapai akurasi tinggi dan mempertahankan keseimbangan antara precision dan recall, yang sangat penting dalam kasus medis. Decision Tree juga menunjukkan potensi yang baik meskipun mengalami overfitting, namun tetap berguna karena kemudahan interpretasinya. Sementara itu, Naive Bayes memiliki kelemahan dalam konteks ini karena tidak dapat menangkap hubungan antar fitur yang kompleks.
Secara umum, proyek ini menunjukkan bahwa pendekatan machine learning sangat memungkinkan untuk mendeteksi penyakit secara dini, asalkan pemilihan fitur, pemrosesan data, dan pemilihan model dilakukan dengan tepat. Keberhasilan MLP menunjukkan bahwa model dengan kompleksitas tinggi bisa sangat berguna dalam mengenali pola dari data kesehatan. Namun, interpretabilitas dan keandalan model tetap harus dipertimbangkan, terutama bila model digunakan dalam konteks medis nyata.
Kesimpulan dan Pembelajaran
Proyek ini memberikan pemahaman menyeluruh tentang bagaimana data kesehatan dan gaya hidup dapat dimanfaatkan untuk membangun model prediksi penyakit yang akurat. Dengan menggunakan LUNG_CANCER sebagai target, proyek ini menjadi lebih realistis dan aplikatif. Meskipun performa model berbeda-beda, keseluruhan proses — mulai dari pemrosesan data hingga evaluasi hasil — menunjukkan pentingnya tahapan analisis yang runtut dan kontekstual.
Pembelajaran utama dari proyek ini adalah bahwa machine learning dapat menjadi alat bantu penting dalam dunia kesehatan, namun hanya jika didukung dengan data yang baik, pemrosesan yang benar, dan pemahaman konteks medis yang tepat. MLPClassifier memberikan hasil terbaik, namun tetap diperlukan validasi lebih lanjut dan perbaikan model agar hasilnya bisa diandalkan. Di masa depan, proyek ini bisa dikembangkan lebih lanjut, misalnya dengan penambahan data eksternal, pengujian pada data nyata, atau penerapan metode balancing untuk menangani data tidak seimbang.
Link Dataset (Kaggle)
https://www.kaggle.com/datasets/nancyalaswad90/lung-cancer
Link Google Colab
https://colab.research.google.com/drive/1KsVPDakRSATJib5TwD-YjCLUsGMCJ79Z?usp=drive_link
Link Google Colab (PDF)
https://drive.google.com/file/d/1fhM1uNEOtsedf624iOBqpS0zqdfIBZzR/view?usp=drive_link
Informasi Course Terkait
Kategori: Algoritma dan PemrogramanCourse: Machine Learning For Beginner
