
Menganalisa Dataset Supermarket Sales
Zahwa Syafifa Maulidia

Summary
Dalam upaya memahami pola transaksi penjualan di sektor ritel, khususnya supermarket, proyek ini dikembangkan untuk menganalisis dan memprediksi nilai transaksi menggunakan pendekatan machine learning. Dengan memanfaatkan model regresi linear sederhana, analisis difokuskan pada hubungan antara biaya pokok penjualan (COGS) dan laba kotor (gross income). Dataset diperoleh dari platform Kaggle, dan seluruh proses analisis dilakukan di Google Collab yang terhubung langsung dengan Google Drive sebagai media penyimpanan.
Tools yang Digunakan :
- Python (pandas, matplotlib, scikit-learn)
- Google Colab + Google Drive
- Dataset: Supermarket Sales dari Kaggle
Hasil Utama :
- Model yang digunakan adalah Regresi linear sederhana
- Mean Squared Error (MSE): 2.5555196356288992e-26, menandakan kesalahan prediksi sangat kecil.
- R-squared (R²): 1.00, menunjukkan model mampu menjelaskan 100% variasi data.
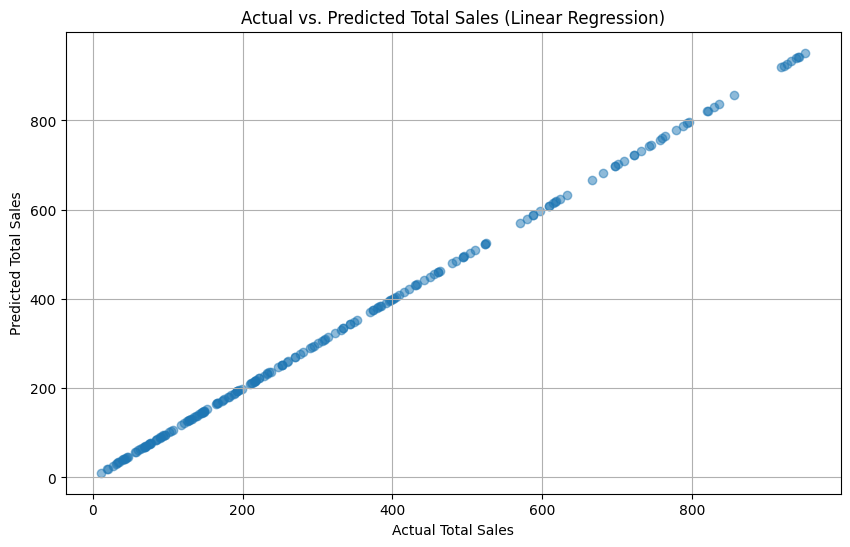
- Visualisasi: Scatter plot menunjukkan prediksi hampir identik dengan data aktual, membentuk garis diagonal sempurna.
Insight :
Hubungan linier sempurna antara input dan output menunjukkan bahwa sistem penjualan retail dalam dataset sangat efisien dan dapat diprediksi dengan baik. Model ini sangat cocok untuk diterapkan pada analisis operasional retail sejenis, karena dapat secara akurat memprediksi total penjualan berdasarkan variabel-variabel dasar seperti COGS atau gross income.
Description
Dalam proyek analisis data ini, saya memanfaatkan metode machine learning untuk memahami pola penjualan yang terjadi di lingkungan sehari-hari, khususnya pada aktivitas transaksi di supermarket. Dengan menggunakan dataset Supermarket Sales yang berisi informasi lengkap mengenai produk, harga, jumlah pembelian, metode pembayaran, dan total transaksi, saya melakukan serangkaian analisis guna mengeksplorasi data serta membangun model prediktif yang dapat memperkirakan total penjualan berdasarkan variabel-variabel yang relevan.
Tools yang Digunakan
- Kaggle : Sebagai sumber data — Dataset Supermarket Sales diunduh dari Kaggle dalam format CSV.
- Google Collab : Digunakan sebagai platform cloud untuk melakukan analisis data dan pemrograman Python. Dan memungkinkan koneksi langsung ke Google Drive.
- Google Drive : digunakan sebagai media penyimpanan dataset agar dapat dengan mudah diakses dari Google Collab.
- Python : Bahasa pemrograman utama yang digunakan dalam proyek ini, didukung oleh berbagai pustaka penting (pandas : untuk manipulasi dan analisis data), (matplotlib : untuk visualisasi data) dan (scikit-learn : untuk pembuatan model machine learning, seperti regresi linear, serta evaluasi model)
Langkah-Langkah Analisis
Langkah pertama dalam proses analisis ini dimulai dengan mencari dan mengunduh dataset "Supermarket Sales Dataset" melalui situs web Kaggle di alamat https://www.kaggle.com, di mana perlu memiliki akun dan login terlebih dahulu untuk dapat mengakses dan mengunduh dataset tersebut. Setelah dataset berhasil diunduh dalam bentuk file ZIP, langkah selanjutnya adalah melakukan ekstraksi file menggunakan fitur Extract All, kemudian menyimpan folder hasil ekstrak ke dalam akun Google Drive agar dapat diakses langsung melalui Google Collab.
Setelah dataset tersedia di Google Drive, langkah berikutnya adalah menghubungkan Google Collab ke Google Drive dengan menggunakan perintah create code to connect to google drive diikuti dengan read dataset from google drive. sehingga Google Collab memiliki akses terhadap file yang tersimpan di Drive kita. Dengan koneksi tersebut, dataset yang telah diunggah dapat diimpor dan dibaca menggunakan library pandas dengan perintah import pandas as pd, lalu data dibaca dengan fungsi pd.read_csv('/content/drive/My Drive/Sales/Sales.csv').
Setelah data berhasil dimuat, tahap selanjutnya adalah melakukan pembersihan (cleaning) dan eksplorasi data untuk memahami struktur dataset, seperti mengidentifikasi kolom mana saja yang bertipe numerik dan non-numerik, serta menangani nilai kosong, duplikat, atau data yang tidak konsisten. Pembersihan ini sangat penting agar analisis yang dilakukan tidak bias dan hasil model menjadi lebih akurat. Setelah itu, data dibagi menjadi dua bagian, yaitu data pelatihan (X_train, y_train) dan data pengujian (X_test, y_test), menggunakan scikit-learn, yang memungkinkan kita untuk melatih model pada sebagian data dan menguji performanya pada data yang belum pernah dilihat sebelumnya.
Langkah berikutnya adalah membangun model regresi linear menggunakan library scikit-learn, di mana kita akan melatih model untuk memprediksi variabel target (Total penjualan) berdasarkan satu atau lebih variabel input seperti cogs atau gross income. Setelah model dilatih, kita mengevaluasi performanya dengan menghitung Mean Squared Error (MSE) untuk mengetahui seberapa besar rata-rata kesalahan prediksi model, serta nilai R-squared (R²) yang mengukur seberapa baik model menjelaskan variasi dari data target.
Terakhir, untuk memberikan gambaran visual mengenai performa model, dibuatlah scatter plot menggunakan library matplotlib, di mana sumbu-x mewakili nilai aktual dari data pengujian dan sumbu-y mewakili nilai prediksi dari model regresi linear. Jika model bekerja dengan baik, titik-titik pada scatter plot akan mendekati garis lurus diagonal yang menunjukkan prediksi sempurna.
Hasil Analisis pada Dataset Supermarket Sales
| Model Yang digunakan | Regresi linear sederhana, dengan satu fitur input yang digunakan untuk memprediksi nilai Total Sales sebagai output. |
| Hasil Evaluasi Model |
Nilai ini hampir nol, menunjukkan bahwa model memiliki tingkat kesalahan yang sangat rendah dan hampir semua prediksi mendekati nilai aktual.
Nilai R² sempurna ini menunjukkan bahwa model mampu menjelaskan 100% variasi dalam data Total Sales. Artinya, tidak ada variabel lain di luar model yang dibutuhkan untuk menjelaskan perubahan nilai Total Sales pada data ini. |
| Insight dari Visualisasi |
|
Kesimpulan
Dari proyek ini, saya belajar bahwa analisis data bukan hanya tentang membangun model, tetapi juga memahami konteks di balik data. Meskipun model regresi linear yang digunakan sangat sederhana, hasilnya menunjukkan potensi besar dari data yang terstruktur dengan baik. Proyek ini membuka peluang untuk eksplorasi lebih lanjut, seperti menambahkan fitur lain, mencoba model yang lebih kompleks, atau menerapkan teknik visualisasi dan evaluasi yang lebih mendalam.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Machine Learning For Beginner
