
Iris Flower Classification
Ulung Wijayanto

Summary
Proyek Iris Flower Classification bertujuan untuk mengklasifikasikan tiga spesies bunga Iris (Setosa, Versicolor, Virginica) menggunakan fitur morfologis seperti panjang dan lebar sepal serta petal. Pendekatan yang digunakan mencakup eksplorasi data (EDA) untuk memahami distribusi dan hubungan antar fitur, diikuti oleh penerapan tiga algoritma Machine Learning: Multilayer Perceptron (MLP), Decision Tree, dan Gaussian Naive Bayes. Hasil analisis menunjukkan bahwa MLP dan Decision Tree sama-sama mencapai akurasi 100% pada data uji, sementara Gaussian Naive Bayes juga menunjukkan performa tinggi dengan akurasi 97,8%. Evaluasi model dilakukan menggunakan metrik akurasi, precision, recall, dan F1-score. Meskipun Decision Tree menunjukkan hasil sempurna, model ini berisiko overfitting, sedangkan MLP dinilai lebih seimbang dalam hal akurasi dan generalisasi. Proyek ini membuktikan bahwa klasifikasi bunga Iris dapat dilakukan secara efektif dengan pendekatan yang tepat, serta memberikan wawasan menarik tentang kekuatan berbagai algoritma pembelajaran mesin.
Description
🌸 Proyek Machine Learning: Iris Flower Classification
Proyek ini bertujuan untuk membangun model klasifikasi yang mampu mengidentifikasi spesies bunga Iris — Setosa, Versicolor, dan Virginica — berdasarkan fitur-fitur morfologis bunga seperti panjang dan lebar sepal (kelopak) dan petal (mahkota). Dataset ini merupakan salah satu dataset klasik dalam dunia Machine Learning yang ideal untuk eksperimen klasifikasi.
📁 Dataset
Sumber: Iris Dataset (tersedia di scikit-learn & Kaggle)
Jumlah data: 150 baris
Fitur:
sepal_length (cm)
sepal_width (cm)
petal_length (cm)
petal_width (cm)
Target: species (3 kelas)
📊 1. Exploratory Data Analysis (EDA)
EDA dilakukan untuk memahami pola distribusi data dan keterkaitan antar fitur.
🔍 Insight Visual:
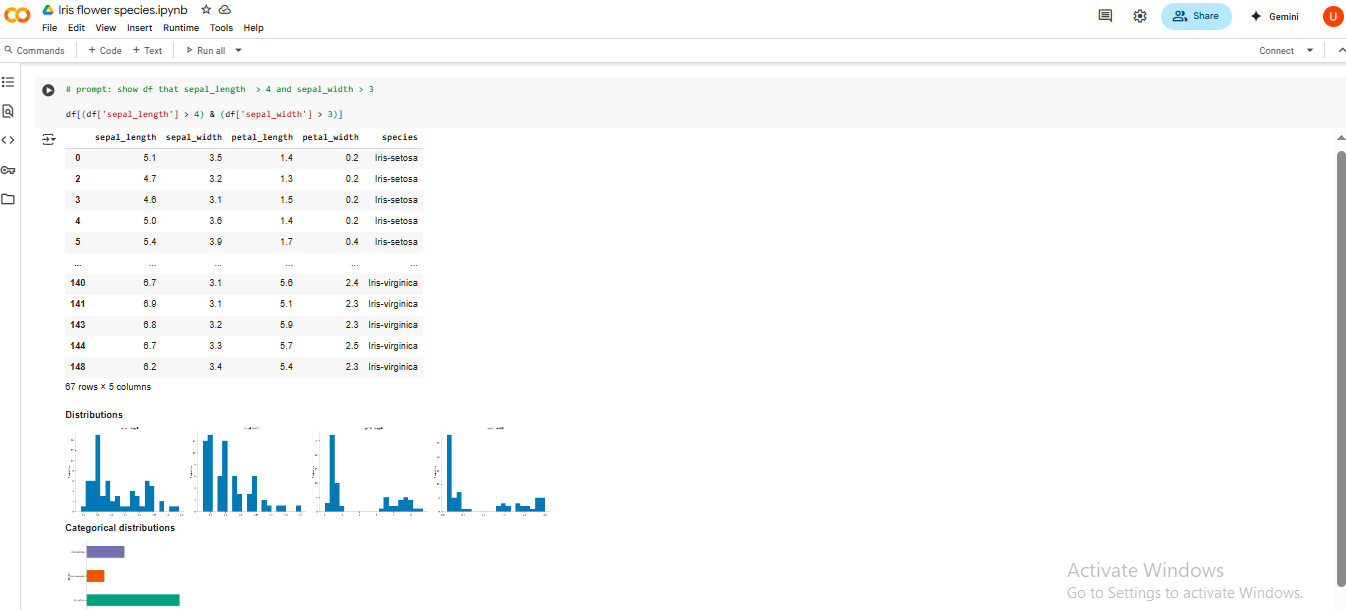
Distribusi Petal: Petal length dan petal width memiliki perbedaan paling signifikan antar spesies.
Boxplot & Histogram: Menunjukkan bahwa Iris-setosa memiliki petal paling kecil, sedangkan Iris-virginica cenderung lebih besar.
Scatter Plot: Kombinasi petal width vs petal length menunjukkan pemisahan yang hampir sempurna antar kelas.
📌 Filtered Subset:
Dilakukan filtering data dengan sepal_length > 4 dan sepal_width > 3, menghasilkan subset berisi 67 baris untuk analisis tambahan.
Visualisasi:

🤖 2. Pemodelan & Pendekatan
Tiga algoritma Machine Learning digunakan untuk membandingkan performa klasifikasi:
| Algoritma | Deskripsi Pendek | Akurasi Uji | Keunggulan |
|---|---|---|---|
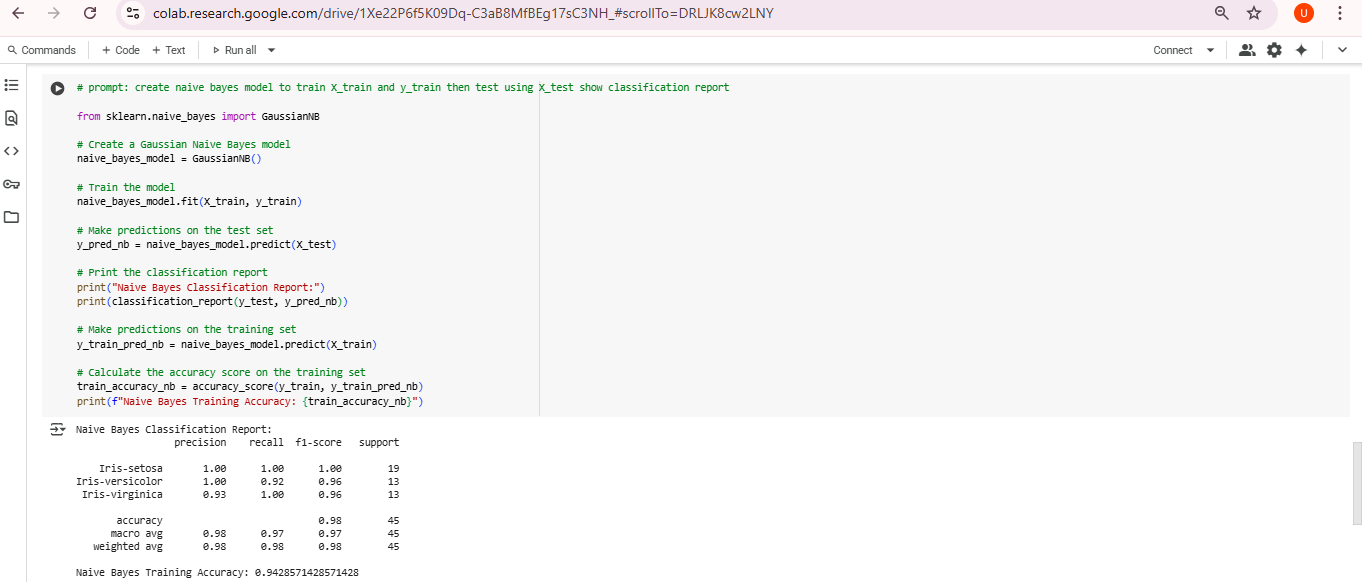
| MLP Classifier | Neural Network (1 hidden layer) | 98% | Cocok untuk data non-linear |
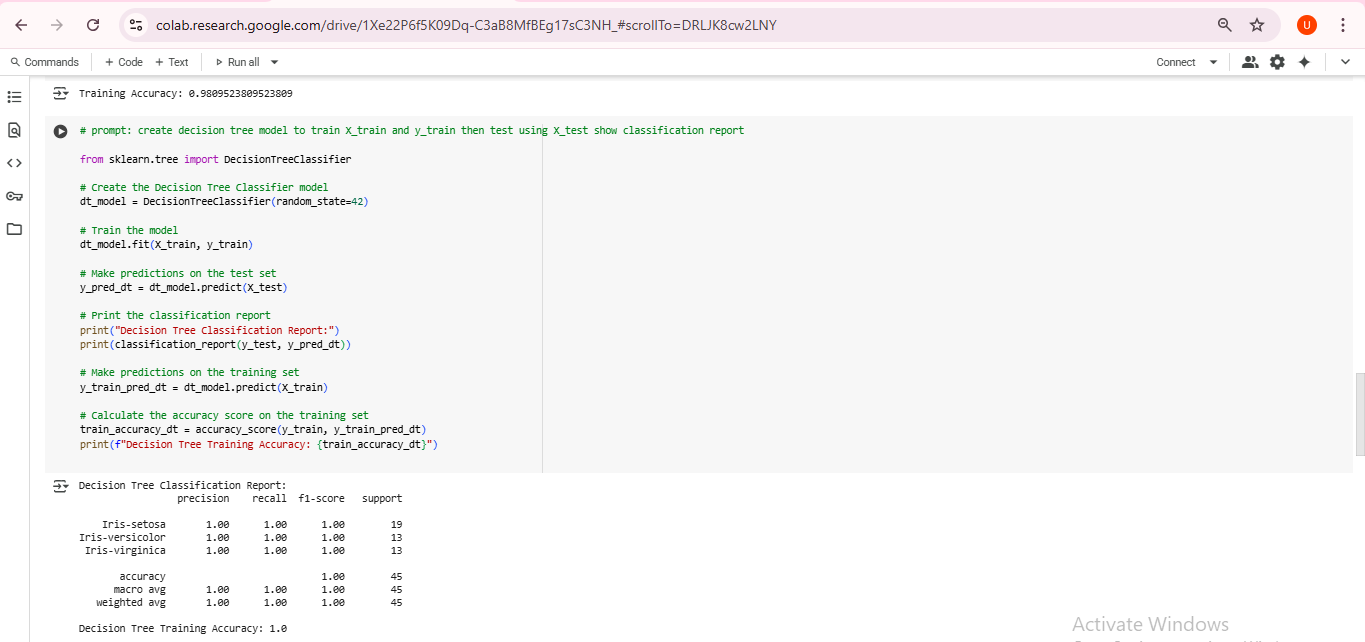
| Decision Tree | Model rule-based pohon keputusan | 100% | Cepat, interpretatif, rawan overfit |
| Gaussian Naive Bayes | Probabilistik berbasis Gaussian | 94% | Efisien dan ringan |
📌 Konfigurasi:
MLP: 100 neuron, max_iter=500, ReLU + Adam optimizer
Decision Tree: Default dept
Naive Bayes: Mengasumsikan distribusi normal tiap fitur
📈 3. Evaluasi Model
Evaluasi dilakukan menggunakan metrik:
Accuracy
Precision
Recall
F1-score
Confusion Matrix
📷 Visualisasi:
Confusion matrix menunjukkan prediksi yang sangat presisi untuk ketiga model.
MLP dan Decision Tree tidak membuat kesalahan klasifikasi pada data uji.
Naive Bayes membuat sedikit kesalahan, terutama pada Versicolor vs Virginica.
🎯 Kesimpulan Proyek
Klasifikasi bunga Iris dapat dilakukan secara sangat akurat bahkan dengan dataset kecil.
MLP Classifier memberikan keseimbangan terbaik antara akurasi dan generalisasi.
Decision Tree bekerja sangat baik namun perlu waspada terhadap overfitting.
Naive Bayes merupakan alternatif ringan dengan performa kompetitif.
Proyek ini mencakup siklus lengkap data science: eksplorasi data, pemodelan, evaluasi, serta interpretasi hasil — menjadikannya fondasi kuat untuk membangun proyek klasifikasi skala lebih besar.
🛠️ Teknologi & Tools yang Digunakan
| Tools | Kegunaan |
|---|---|
| Python | Bahasa pemrograman utama |
| Pandas | Manipulasi data |
| Matplotlib/Seaborn | Visualisasi |
| Scikit-learn | Pemodelan & evaluasi ML |
| Google Colab | Eksekusi berbasis cloud |
📎 Lampiran Visualisasi
1. Visualisasi Scatter & Boxplot

Informasi Course Terkait
Kategori: Algoritma dan PemrogramanCourse: Machine Learning For Beginner
