
LAYANAN KESEJAHTERAAN MENTAL BERBASIS CHATBOT
Chaerudin Saputra


Summary
Stigma terhadap gangguan mental dan keterbatasan akses layanan kesehatan mental memperparah situasi ini. Banyak korban enggan mencari bantuan karena takut dinilai negatif, sementara dukungan profesional sering sulit dijangkau, terutama di pedesaan. Dampak jangka panjangnya mencakup terganggunya pendidikan, hubungan sosial, dan karier korban. Kemajuan teknologi membuka peluang layanan kesehatan mental online, tetapi kebanyakan belum ramah untuk remaja dan dewasa muda. Oleh karena itu, HERADA hadir sebagai solusi untuk memberikan dukungan psikologis yang aman, nyaman, dan mudah diakses
Description
BAB III
METODE PELAKSANAAN
3.1 Tahapan Pelaksanaan
Kami melakukan serangkaian proses untuk mengembangkan produk HERADA, berikut merupakan flowchart tahap pelaksanaan.

Gambar 3.1
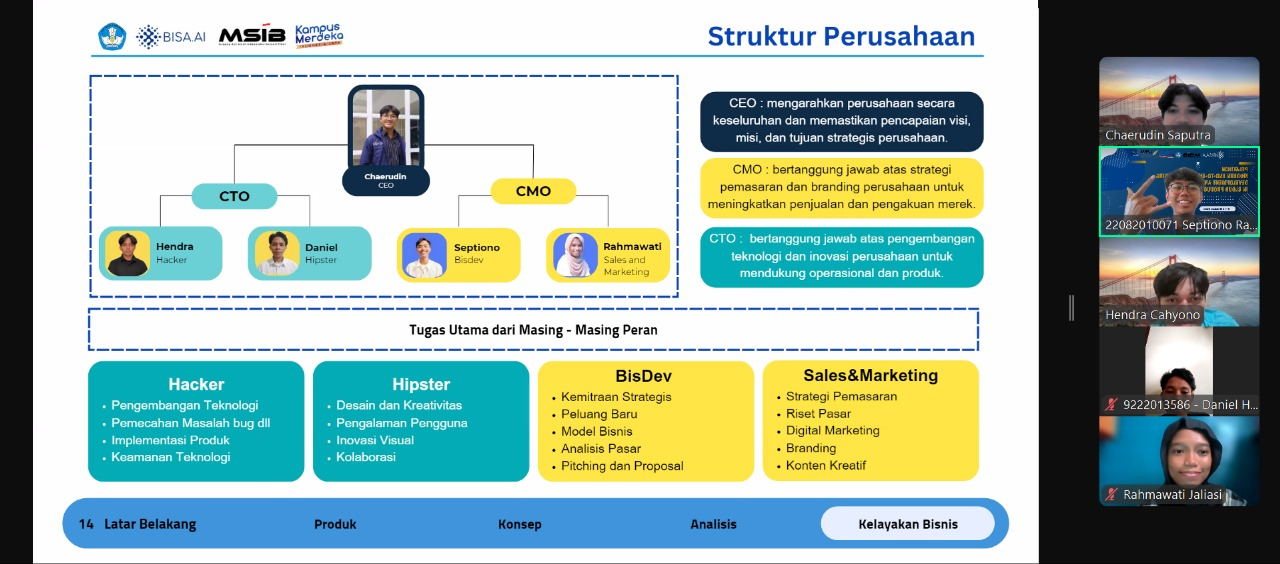
Tahap pertama yang kami lakukan adalah persiapan project, kami melakukan penetapan anggota tim berdasarkan kemampuan yang mencangkup CEO, Hipster, Hacker, BisDev, Sales dan Marketing. Setelah itu, kami membagi tim menjadi dua bagian yakni, tim a yang terdiri atas hipster dan hacker bertanggung jawab untuk membuat sistem, tim b yang terdiri atas bisnis development dan sales marketing bertanggung jawab membuat proposal dan pitch deck. Sedangkan CEO bertanggung jawab dalam keduanya.
Tahap selanjutnya merupakan penentuan ide, kami menentukan platform yang akan dikembangkan, yakni HERADA yang mana merupakan platform untuk kesehatan mental dengan tujuan memberikan pelayanan kepada pengguna yang mengalami gangguan mental supaya dapat bercerita tanpa takut dihakimi.
Pada tahap ketiga, tim segera dipecah dan menjalankan tugas masing - masing. Tim a melakukan riset pasar dan tim b melakukan pengembangan produk. Pada tahap ketiga, tim a melakukan analisis pesaing dan mengidentifikasi pasar mulai hingga menemukan target market dan unique value product. Sedangkan tim b, mencari data set dan model pelatihan hingga menentukan algoritma dan framework yang akan digunakan untuk proses development.
Pada tahap ke empat, masing - masing tim akan mengumpulkan progresnya. Tim a melakukan persiapan untuk membuat proposal, sedangkan tim b melakukan development hingga testing aplikasi sampai aplikasi dapat digunakan oleh pengguna.
Pada tahap terakhir, bila semua pengerjaan selesai maka tim a membuat proposal dan pitch deck untuk menuntaskan tugas.
3.2 Metodologi dan Algoritma
Metodologi yang digunakan adalah kualitatif dengan jenis penelitian deskriptif. Pemilihan metode ini didasarkan pada tujuan penelitian untuk memberikan gambaran yang sistematis, faktual, dan akurat mengenai fakta, karakteristik, serta hubungan antar fenomena (Sugiono, 2011), khususnya terkait penggunaan chatbot HERADA dalam mengatasi masalah kesehatan mental remaja. Teknik pengumpulan data meliputi studi literatur dan observasi. Data yang diperoleh dianalisis menggunakan metode analisis teks kualitatif. Analisis konten kualitatif digunakan untuk memahami makna dan simbol yang terkandung dalam dokumen, baik dalam bentuk cetak maupun audiovisual (Eriyanto, 2011).
Adapula, algoritma yang digunakan yaitu algoritma yaitu Convolutional Neural Network (K-Neighbors Classifier (KNN)). Algoritma K-Neighbors Classifier (KNN) merupakan salah satu algoritma dari deep learning yang mampu melakukan pengenalan dan klasifikasi teks dan suara sehingga sesuai dengan proyek kami yang memanfaatkan suara dan teks untuk mendeteksi permasalahan lebih lanjut (Jihar Al Gifari, 2021) . Selain itu, proyek ini diterapkan dalam sebuah website dengan framework Flask yang ringan dan fleksibel (P. Singh, 2020) sehingga mudah mengintegrasikan Algoritma K-Neighbors Classifier (KNN) ke dalam website. Berdasarkan penelitian yang sudah dilakukan oleh (Andre R, 2021) Metode penelitian dengan menggunakan Algoritma K-Neighbors Classifier (KNN) untuk mengklasifikasikan tumor otak dengan menggunakan deep learning dengan hasil akurasi dari pengujian mencapai 99.7% serta mendapatkan nilai F1-Score tertinggi mencapai 99.6% sehingga pada proyek HERADA dalam melatih dataset kami juga akan meggunakan Algoritma K-Neighbors Classifier (KNN).
3.2.1 Chat Bot
Pada sub-bab ini, akan dijelaskan pengembangan dan algoritma inti dari chatbot HERADA, yang dirancang untuk membantu pengguna dalam mencari dukungan psikologis secara responsif dan empatik. HERADA memanfaatkan teknologi Generative AI dari Google Gemini untuk memberikan respons yang relevan dan berbasis bahasa alami sesuai dengan input pengguna. Berikut adalah implementasi dan penjelasannya.
Deskripsi Sistem Chatbot
Chatbot HERADA adalah sebuah sistem interaktif yang dirancang untuk memberikan pengalaman komunikasi yang mendekati dialog manusia. Fungsinya mencakup memberikan dukungan psikologis, mengidentifikasi kebutuhan pengguna, dan memberikan rekomendasi berbasis algoritma prediktif.
Fitur utama chatbot ini meliputi:
Deteksi Bahasa Otomatis: Sistem mampu mengenali bahasa pengguna secara otomatis menggunakan pustaka langdetect. Bahasa yang didukung termasuk Bahasa Indonesia dan Bahasa Inggris.
Respons Empatik dan Berbasis Konteks: Sistem menggunakan API Google Gemini untuk menghasilkan respons yang empatik dan relevan sesuai konteks percakapan.
Interaksi yang Mudah: Pengguna cukup memasukkan teks percakapan untuk menerima respons. Chatbot mendukung komunikasi dalam situasi santai dan serius.
Algoritma Chatbot
Kode berikut menjelaskan implementasi chatbot menggunakan Python:
import google.generativeai as genai
import os
import langdetect
# Mengatur API Key
my_api_key_gemini = 'YOUR API' # Ganti dengan API key yang valid
genai.configure(api_key=my_api_key_gemini)
def generate_response(prompt, language):
# Menentukan prompt berdasarkan bahasa
if language == 'id':
prompt = f"Sebagai psikolog, berikan respons empatik dalam bahasa Indonesia untuk: {prompt}"
else:
prompt = f"As a psychologist, respond with empathy and support to the following: {prompt}"
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content(prompt)
return response.text if response.text else "Maaf, saya tidak bisa merespons saat ini. Silakan coba lagi nanti."
def main():
print("Selamat datang di HAREDA Chat Assistant, di sini untuk mendukung Anda!")
while True:
user_input = input("Anda: ")
if user_input.lower() in ['exit', 'quit']:
print("HAREDA: Terima kasih telah berbagi. Jika Anda butuh lagi, HAREDA siap mendengarkan. Sampai jumpa!")
break
# Mendeteksi bahasa input
language = langdetect.detect(user_input)
response = generate_response(user_input, language)
print("HAREDA:", response)
if __name__ == '__main__':
main()
- Penjelasan Kode
Konfigurasi API Google Gemini:
API Google Gemini digunakan untuk menghasilkan respons berbasis teknologi Generative AI.
Penggunaan API ini memungkinkan respons yang lebih personal dan berbasis empati.
Fungsi generate_response:
Fungsi ini menerima prompt dari pengguna dan mendeteksi bahasa menggunakan pustaka langdetect.
Bahasa yang dikenali menentukan template respons yang akan digunakan.
Interaksi Utama:
Program menyediakan antarmuka terminal sederhana di mana pengguna dapat mengetik pesan.
Sistem mengenali input pengguna dan menghasilkan respons menggunakan model gemini-pro.
Empati dan Ketersediaan Respons:
Jika respons tidak dapat dihasilkan, sistem memberikan pesan kegagalan dengan sopan.
Keluar dari Sistem:
Pengguna dapat menghentikan percakapan dengan memasukkan kata kunci seperti exit atau quit.
Chatbot HERADA mengintegrasikan AI Generatif untuk memberikan solusi dukungan psikologis berbasis teknologi. Dengan pendekatan ini, sistem dapat membantu pengguna yang mengalami tekanan emosional tanpa harus menunggu waktu konsultasi langsung dengan psikolog. Selain itu, chatbot ini juga dirancang sebagai alat bantu diagnosis awal yang dapat memberikan wawasan kepada tenaga profesional untuk tindak lanjut lebih lanjut.
3.2.1 Prediksi menggunakan K-Neighbors Classifier (KNN)
Import Library yang Dibutuhkan
Di bagian awal kode, library yang relevan untuk eksplorasi data, visualisasi, dan pembelajaran mesin diimpor, seperti numpy, pandas, seaborn, matplotlib, dan library dari sklearn. Tujuannya adalah untuk mendukung pemrosesan data, analisis, serta pembuatan dan evaluasi model
Load Dataset
Dataset diambil dari Google Drive menggunakan path tertentu (/content/drive/My Drive/DATASET_MSIB/Project/Stress_sleep/SaYoPillow.csv). Data ini berisi beberapa fitur seperti:
snoring_rate: Tingkat mendengkur.
respiration_rate: Tingkat pernapasan.
body_temperature: Suhu tubuh.
limb_movement: Gerakan anggota tubuh.
blood_oxygen: Kadar oksigen dalam darah.
eye_movement: Pergerakan mata.
sleeping_hours: Jumlah jam tidur.
heart_rate: Detak jantung.
stress_level: Tingkat stres (label klasifikasi: 0–4, dari rendah hingga tinggi).
Eksplorasi Data
Sebelum membangun model KNN, dilakukan analisis data, termasuk:
Dataset ini berisi 630 baris dan 9 kolom, dengan masing-masing kolom merepresentasikan atribut tertentu yang relevan untuk analisis data. Berikut adalah deskripsi untuk setiap kolom:
sr: Mewakili skor tertentu (mungkin tingkat atau nilai tertentu). Nilainya berupa angka desimal.
rr: Mewakili rasio tertentu yang berkaitan dengan atribut lain. Nilainya berupa angka desimal.
t: Mungkin menunjukkan nilai target atau output yang dicapai.
lm: Mewakili nilai numerik yang terkait dengan parameter atau batas tertentu.
bo: Mengacu pada nilai batas lainnya, sering kali terkait dengan kondisi tertentu.
rem: Menunjukkan jumlah yang tersisa, mungkin dalam konteks sisa proses, sumber daya, atau nilai.
sr.1: Variabel lain yang mirip dengan sr, tetapi mungkin mewakili nilai tambahan atau turunan.
hr: Mengindikasikan rasio atau parameter tertentu yang memengaruhi nilai sebelumnya.
sl: Variabel kategori yang mungkin berfungsi sebagai label kelas untuk klasifikasi. Misalnya:
0: Kategori pertama ( low/normal)
1: Kategori kedua (medium low)
2: Kategori ketiga ( Medium )
3: Kategori keempat (Medium High)
4: Kategori kelima (High)
Dataset ini dapat digunakan untuk analisis statistik, klasifikasi, atau regresi tergantung pada hubungan antar kolom. Analisis awal ini menunjukkan bahwa dataset memiliki campuran kolom numerik dan kategoris, yang memungkinkan eksplorasi lebih lanjut seperti korelasi antar variabel atau membangun model prediksi menggunakan kolom sl sebagai target.
2. Heatmap Korelasi: Membantu mengidentifikasi hubungan antarvariabel.

3. Pemeriksaan Outlier: Menggunakan boxplot untuk tiap kolom.

Tujuannya adalah memahami pola dalam data, mengidentifikasi hubungan antarvariabel, dan mengatasi potensi masalah seperti outlier.
Split Data untuk Pelatihan dan Pengujian
Dataset dibagi menjadi dua bagian:
Fitur (X): Semua kolom kecuali stress_level.
Label (y): Kolom stress_level.
Data dibagi menjadi 80% untuk pelatihan dan 20% untuk pengujian menggunakan train_test_split dari sklearn.
Membuat Model K-Neighbors Classifier
Model K-Neighbors Classifier (KNN) dibuat menggunakan parameter default dari library sklearn. Proses pelatihan dan prediksi meliputi:
Pelatihan Model:
model.fit(X_train, y_train)
Prediksi:
y_pred = model.predict(X_test)
Evaluasi Model
Model KNN dievaluasi menggunakan beberapa metrik utama:
Accuracy: Tingkat keakuratan model dalam mengklasifikasikan data uji.
Precision, Recall, dan F1-score: Mengukur kinerja model pada tiap kelas.
Classification Report: Memberikan ringkasan metrik di atas untuk setiap kelas dalam data.

Confusion Matrix: Menunjukkan distribusi prediksi model dibandingkan label sebenarnya.

Hasil evaluasi menunjukkan bahwa model memiliki akurasi 100%, yang berarti model mampu memprediksi semua data uji dengan benar.
Menyimpan dan Memuat Model
Model KNN disimpan dan dimuat kembali untuk prediksi lebih lanjut. Proses ini melibatkan:

Menyimpan Model dalam Format .h5: Model yang telah dilatih disimpan sehingga dapat digunakan kembali tanpa perlu melatih ulang.
Memuat Model: Model disimpan menggunakan joblib atau framework lain, kemudian dimuat kembali untuk prediksi. Evaluasi model setelah dimuat menunjukkan hasil yang sama dengan sebelum disimpan.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Data Science
