
Building Sentiment Model Google Playstore Dataset
Ferrent Georgina Rini Tacoh



Summary
A little introduction, this is my first portofolio in Bisa AI Academy for Natural Language Processing task. In this project, I build sentiment model for Google Play Store user review datasets. Google Play Store is a digital Android market to sell Google Play product, that developed by Google. In Google Play Store, there is a review and sentiment of user for each apps. In this project I using several model such as using Logistic Regression, Decision Tree, Random Forest, and Neural Network. The datasets could be accessed on Kaggle: https://www.kaggle.com/datasets/lava18/google-play-store-apps?select=googleplaystore_user_reviews.csv
Description
Natural Language Processing
Natural Language Processing (NLP) adalah cabang dari Artificial Intelligence (AI) atau kecerdasan buatan yang berhubungan dengan interaksi antara komputer dan manusia menggunakan bahasa alami (natural language), salah satu penerapannya adalah Analisis Sentimen. Analisis sentimen merupakan salah satu bidang dari Natural Language Processing (NLP) yang membangun sebuah sistem untuk mengenali dan mengekstrak opini dalam bentuk teks. Informasi dalam bentuk teks saat ini banyak tersedia di internet dalam format forum, blog, media sosial, dan situs yang berisi ulasan. Tujuannya adalah untuk mendapatkan opini dari pengguna di platform.
Datasets
Datasets bisa dengan melakukan akses dari kaggle. Adapun tautan tercantum sebagai berikut: https://www.kaggle.com/datasets/lava18/google-play-store-apps?select=googleplaystore_user_reviews.csv
Text Preprocessing
- Lowercase & Removing:
- Lowercase untuk mengubah kata menjadi huruf kecil
- Removing adalah untuk menghapus special characters
- Tokenisasi & Stopwords:
- Tokenisasi untuk memecah teks mentah menjadi kata-kata, kalimat yang disebut token. Token ini membantu dalam memahami konteks atau mengembangkan model untuk Natural Language processing.
- Stopwords digunakan untuk menghilangkan kata-kata yang tidak penting, yang memungkinkan aplikasi untuk fokus pada kata-kata penting sebagai gantinya. Misalnya: dalam bahasa Inggris, “the”, “is” dan “and”, akan dengan mudah memenuhi syarat sebagai stop words
- Lemmatization:
- Lemmatization biasanya mengacu pada melakukan sesuatu dengan benar dengan penggunaan kosakata dan analisis morfologis kata. Lemma (jamak lemmas atau lemmata) adalah bentuk kanonik, bentuk kamus, atau bentuk kutipan dari sekumpulan kata. Misalnya, runs, running, ran adalah semua bentuk kata run, oleh karena itu run adalah lemma dari semua kata ini.
- Vectorization
- Vektorisasi adalah proses mengubah teks menjadi representasi numerik. Untuk kasus ini digunakan Bag of Word
Experiment
Jumlah Data
Setelah beberapa penerapan proses eksperimen yang dikerjakan, data yang digunakan sangat banyak dan memiliki banyak missing value. Maka dari itu ada sejumlah pengurangan data yang semula 64295 baris dan 5 kolom yang berupa ‘App’, ‘Translated_Review’, ‘Sentiment’, ‘Sentiment_Polarity’, dan ‘Sentiment_Subjectivity', dikurangi menjadi 37427 baris 2 kolom setelah menghilangkan missing value, dan menggunakan kolom yang ditetapkan sebagai target yaitu kolom 'Sentiment' dan sebagai feature yaitu 'Translated_Review'. Karena sebanyak 37427 data pun terlalu banyak jika di fit transform vektorisasi, sehingga diputuskan untuk mengurangi banyaknya data yang digunakan. Dipangkaslah beberapa data, sehingga total data yang digunakan 13427 baris dan 2 kolom
Target & Feature
- Target
Variabel target dari data yang digunakan adalah pada kolom Sentiment yang mempunyai label kelas diantaranya: Positive, Negative dan Netral. Berikut visualisasi label kelas Sentiment terhadap data:

Banyaknya jumlahnya kelas pada sentiment dituliskan sebagai berikut:

- Feature
Feature yang digunakan adalah kolom 'Translated_Review', yang mana akan melewati sejumlah tahapan text preprocessing, mulai dari di lowercase, menghilangkan special characters, tokenisasi dan stopwords dengan library nltk (karena datanya berbahasa inggris, lemmatization, hingga vektorisasi fit_transform().toarray() dan bag of words
Wordcloud

Wordcloud atau Tag cloud adalah sebuah kata yang berisi banyak kata dalam berbagai ukuran, yang mewakili frekuensi atau pentingnya setiap kata. Wordcloud yang digunakan bisa di adjust, namun untuk eksperimen ini dengan background putih, cmap = ‘hsv’, dan random_state=42.
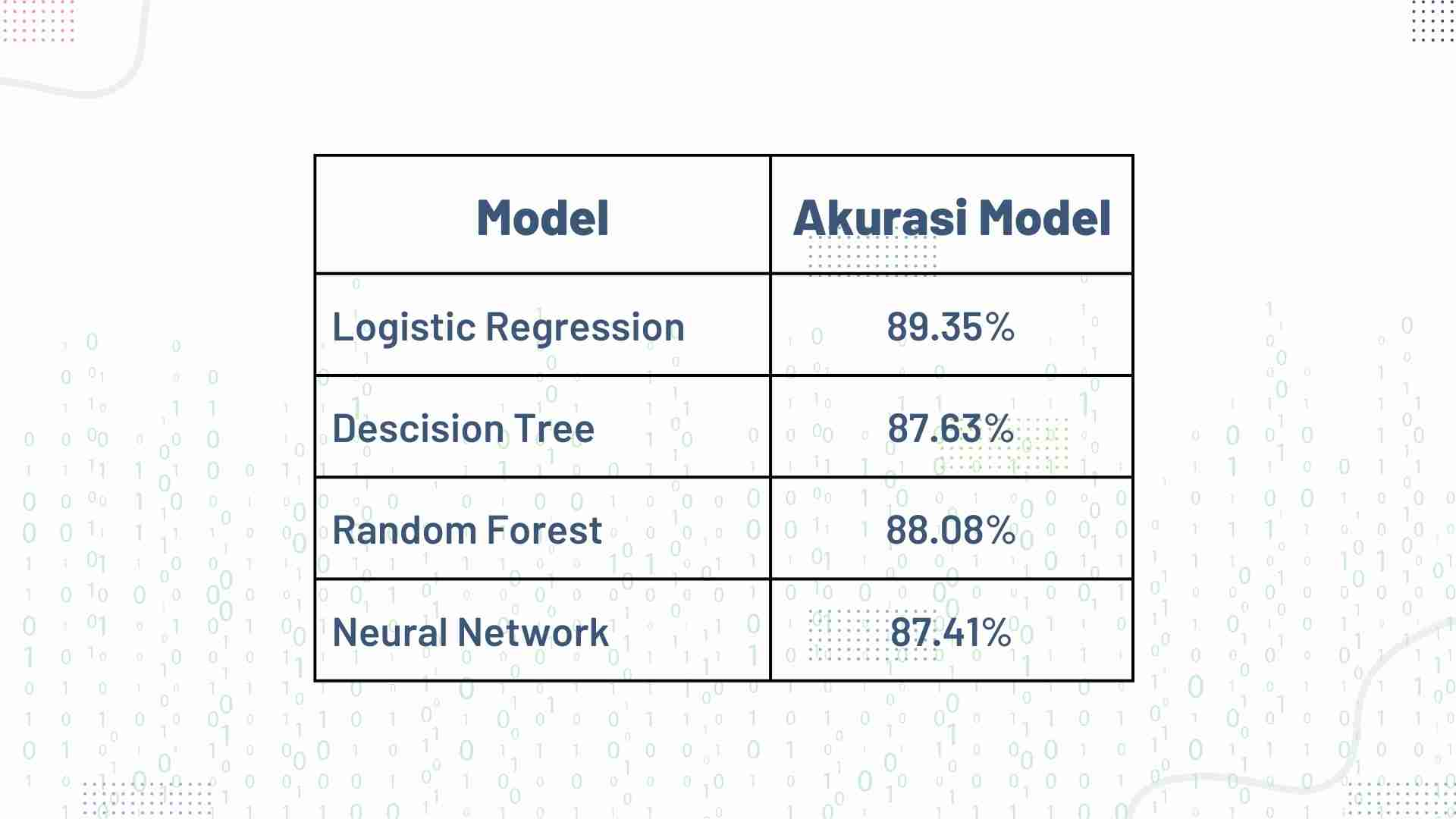
Modeling & Conclusion
Modeling yang digunakan menggunakan Logistic Regression, Decision Tree, Random Forest, and Neural Network, dengan hasil masing-masing sebagai berikut:

Eksperimen ini juga di upload di repositori github saya, yang bisa diakses
https://github.com/ferrenttacoh/googleplaystoremodeling
Sekian dari saya, terima kasih banyak.
~Ferrent
Informasi Course Terkait
Kategori: Natural Language ProcessingCourse: Natural Languange Processing (NLP) dengan Deep Learning
