
Air Quality Classification using Random Forest
Ardoni Yeriko Rifana Gultom


Summary
Proyek ini bertujuan untuk memprediksi kategori kualitas udara (BAIK, SEDANG, TIDAK SEHAT) menggunakan model Random Forest. Dengan memanfaatkan data polutan seperti PM10, SO2, CO, O3, NO2, dan PM25, proyek ini menerapkan teknik eksplorasi data (EDA), penanganan outlier, serta penyamaan kelas menggunakan SMOTE untuk menangani ketidakseimbangan data. Hasil model akan dilakukan evaluasi untuk memastikan apakah model tersebut sudah bekerja dengan baik.
Description
Business Understanding
Proyek ini bertujuan untuk mengklasifikasikan kualitas udara di DKI Jakarta berdasarkan data polutan udara. Klasifikasi ini penting karena kualitas udara yang buruk dapat menyebabkan masalah kesehatan yang signifikan. Saya ingin menggunakan data yang tersedia untuk memprediksi kualitas udara dan memberikan informasi yang bermanfaat bagi pengambil kebijakan untuk mengurangi polusi.
Data Understanding
Dataset ini terdiri dari 1825 entri dengan 11 kolom yang mencakup informasi tentang tanggal pengukuran, stasiun pemantauan, nilai polutan (PM10, SO2, CO, O3, NO2, PM25), max, critical serta kategori kualitas udara ('BAIK', 'SEDANG', 'TIDAK SEHAT'). Dataset ini berisi data Indeks Standar Pencemar Udara (ISPU) yang diukur dari 5 Stasiun Pemantauan Kualitas Udara (SPKU) di DKI Jakarta pada tahun 2021. Data ini diambil dari Open Data Jakarta dimana sumber datanya berasal dari Dinas Lingkungan Hidup Provinsi DKI Jakarta.
Import Modul

Exploratory Data Analysis (EDA)
EDA adalah langkah awal yang sangat penting untuk memahami karakteristik data secara mendalam sebelum melanjutkan ke tahap Data Preparation dan Modeling.
Load Dataset
Dataset dapat diakses melalui link berikut: https://docs.google.com/spreadsheets/d/1mx6q5ipX6vPzRBhS0TdRFwztmcLPH4bs2Lt12KyZ6qU/export?format=csv

Memahami Struktur Data
Mengidentifikasi tipe data, jumlah data yang hilang, distribusi statistik numerik, dan memeriksa apakah ada kolom yang tidak relevan.


Memeriksa Struktur Data: Dataset ini terdiri dari 1825 entri dan 11 kolom. Kolom utama yang relevan untuk analisis ini adalah stasiun, pm10, so2, co, o3, no2, pm25, critical, dan categori.
Memeriksa Missing Values
Menilai apakah ada missing values di dataset dan mempertimbangkan cara penanganannya

Missing Values: Beberapa kolom memiliki nilai yang hilang, seperti pm10, so2, co, o3, no2, pm25, dan critical. Nilai-nilai yang hilang akan diisi dengan median masing-masing kolom numerik dan modus untuk kolom kategorik untuk menghindari kehilangan data.
Memeriksa Distribusi Kelas (Target)
Melakukan visualisasi pada distribusi kelas target (categori) untuk mengecek apakah ada masalah ketidakseimbangan kelas (class imbalance). Tujuannya untuk memahami sebaran kelas target. Jika ada ketidakseimbangan kelas, maka perlu menggunakan teknik seperti SMOTE atau undersampling/oversampling untuk menanganinya.

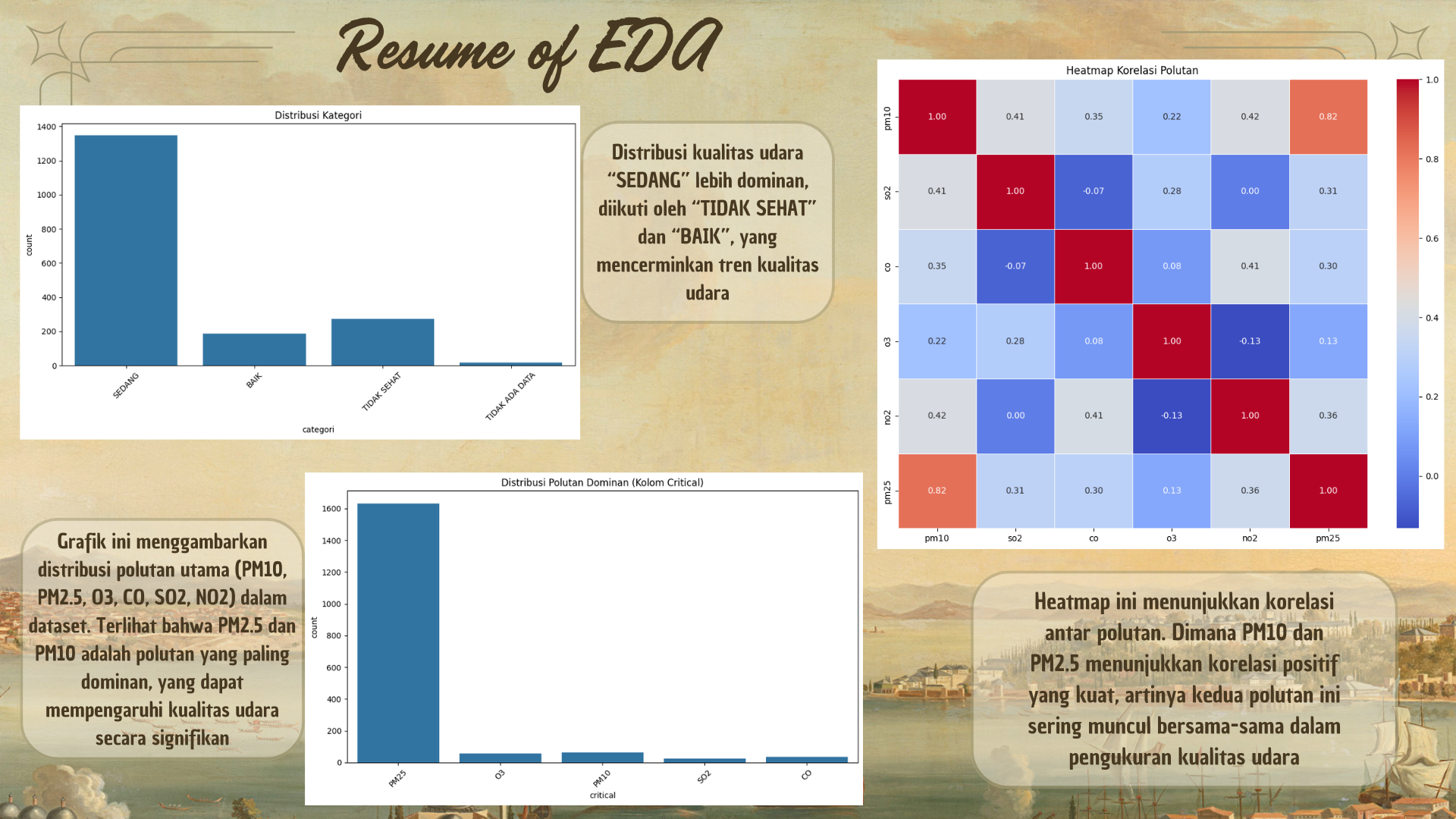
Distribusi Kategori: Berdasarkan analisis distribusi target categori, terlihat bahwa kelas 'SEDANG' lebih dominan dibandingkan dengan kelas lainnya. Ini menunjukkan adanya ketidakseimbangan kelas yang perlu ditangani.
Memeriksa Outlier
Memvisualisasikan data menggunakan boxplot untuk mendeteksi outliers di kolom polutan.

Outliers: Boxplot menunjukkan bahwa beberapa fitur, seperti pm10, o3, dan lainnya memiliki nilai outlier yang sangat tinggi. Untuk pemodelan, saya memilih untuk mengganti outlier tersebut dengan median untuk memastikan model tidak terpengaruh oleh nilai ekstrem.
Memeriksa Korelasi Antar Fitur
Memvisualisasikan correlation matrix menggunakan heatmap untuk melihat apakah ada fitur yang saling berkorelasi. Ini dapat membantu dalam memilih fitur yang relevan.


Korelasi Fitur: Dari correlation heatmap, kita melihat bahwa beberapa polutan, seperti pm10 dan pm25, memiliki korelasi tinggi.
Distribusi Data Numerik


Distribusi Polutan: Distribusi polutan menunjukkan adanya nilai yang sangat terdistorsi, seperti yang terlihat pada histogram. Beberapa transformasi mungkin diperlukan untuk mempersiapkan data untuk pemodelan.
Visualisasi Kolom critical untuk Mengetahui Polutan Dominan

Polutan Dominan: Berdasarkan distribusi polutan menunjukkan bahwasanya polutan pm25 merupakan polutan yang paling dominan dari polutan lainnya
Data Preparation
Pada tahap ini, data yang telah dianalisis dan dipahami melalui EDA (Exploratory Data Analysis) akan diproses lebih lanjut, diubah, dan dipersiapkan untuk digunakan dalam model machine learning. Data yang tidak terorganisir atau tidak sesuai formatnya akan dapat mempengaruhi kualitas model yang dihasilkan.
Data Cleaning
Pada tahap ini, memastikan bahwa data yang digunakan bebas dari masalah-masalah umum yang bisa mengganggu analisis dan pemodelan, seperti missing values, duplikasi data, atau format yang tidak konsisten.
Menangani Missing Values
Mengisi missing values dengan nilai median untuk kolom numerik dan modus untuk kolom kategorik



Memperbaiki Format Data (Konversi Tipe Data)
Beberapa kolom perlu diubah tipe datanya, seperti mengubah kolom tanggal menjadi format datetime. Kemudian kolom kategorik harus bertipe category.


Menangani Outlier
Outlier merupakan nilai yang sangat berbeda dengan sebagian besar data lainnya. Outlier dapat memengaruhi analisis dan model secara signifikan.
Identifikasi Outlier: IQR (Inter-Quartile Range) untuk mendeteksi outlier


Penanganan Outlier: Mengganti outlier dengan nilai median


Transformasi Data
Data dalam dataset mungkin tidak berada dalam format yang tepat untuk digunakan dalam model. Transformasi melibatkan perubahan format, tipe data, atau nilai dalam kolom agar sesuai dengan model yang akan digunakan.
Menangani Data Kategorikal
Beberapa model membutuhkan data numerik, sehingga kolom kategorikal perlu diubah menjadi format numerik menggunakan Label Encoding.



Standarisasi
Standarisasi mengubah data sehingga memiliki rata-rata 0 dan standar deviasi 1, yaitu menjadikan data terdistribusi normal (meskipun data asli tidak harus normal).

Feature Selection
Setelah melakukan transformasi, perlu memilih fitur mana yang akan digunakan dalam model. Fitur yang tidak relevan atau terlalu banyak fitur yang saling berkorelasi dapat menyebabkan overfitting atau meningkatkan kompleksitas model tanpa memberikan kontribusi yang signifikan.

Menangani Class Imbalance
Data yang digunakan memiliki distribusi kelas yang tidak seimbang (lebih banyak data di kelas SEDANG (1) daripada kelas lainnya), sehingga akan diterapkan teknik SMOTE untuk mengatasinya. SMOTE (Synthetic Minority Over-sampling Technique) untuk menambah jumlah sampel pada kelas minoritas.

Splitting Data
Sebelum membangun model, dataset biasanya dibagi menjadi dua bagian: data latih (training) dan data uji (testing). Ini penting untuk menghindari overfitting (model terlalu menyesuaikan dengan data pelatihan) dan untuk memastikan model dapat diuji dengan data yang tidak terlihat sebelumnya.

Modelling
Model yang akan digunakan ialah model Random Forest Classifier karena model ini mampu menangani data dengan banyak fitur dan dapat mengatasi masalah non-linearitas dengan baik. Selain itu, Random Forest memiliki kemampuan untuk mengatasi overfitting dan memberikan hasil yang sangat baik dalam tugas klasifikasi.
Pelatihan Model Random Forest
Setelah data terbagi, selanjutnya memilih model yang sesuai dengan tujuan analisis. Karena tujuannya ingin melakukan klasifikasi, maka Random Forest adalah pilihan yang baik karena robust terhadap overfitting dan dapat menangani data yang tidak terstruktur dengan baik.

Evaluation
Setelah model dilatih, kita perlu mengevaluasi performa model di data uji untuk memastikan bahwa model bekerja dengan baik. Ini dilakukan dengan mengukur akurasi model dan menggunakan beberapa metrik evaluasi lainnya, seperti classification report dan confusion matrix.
Prediksi Data Uji

Akurasi
Akurasi adalah metrik evaluasi yang umum digunakan dalam masalah klasifikasi. Akurasi menunjukkan berapa persentase prediksi yang benar dibandingkan dengan jumlah total data.

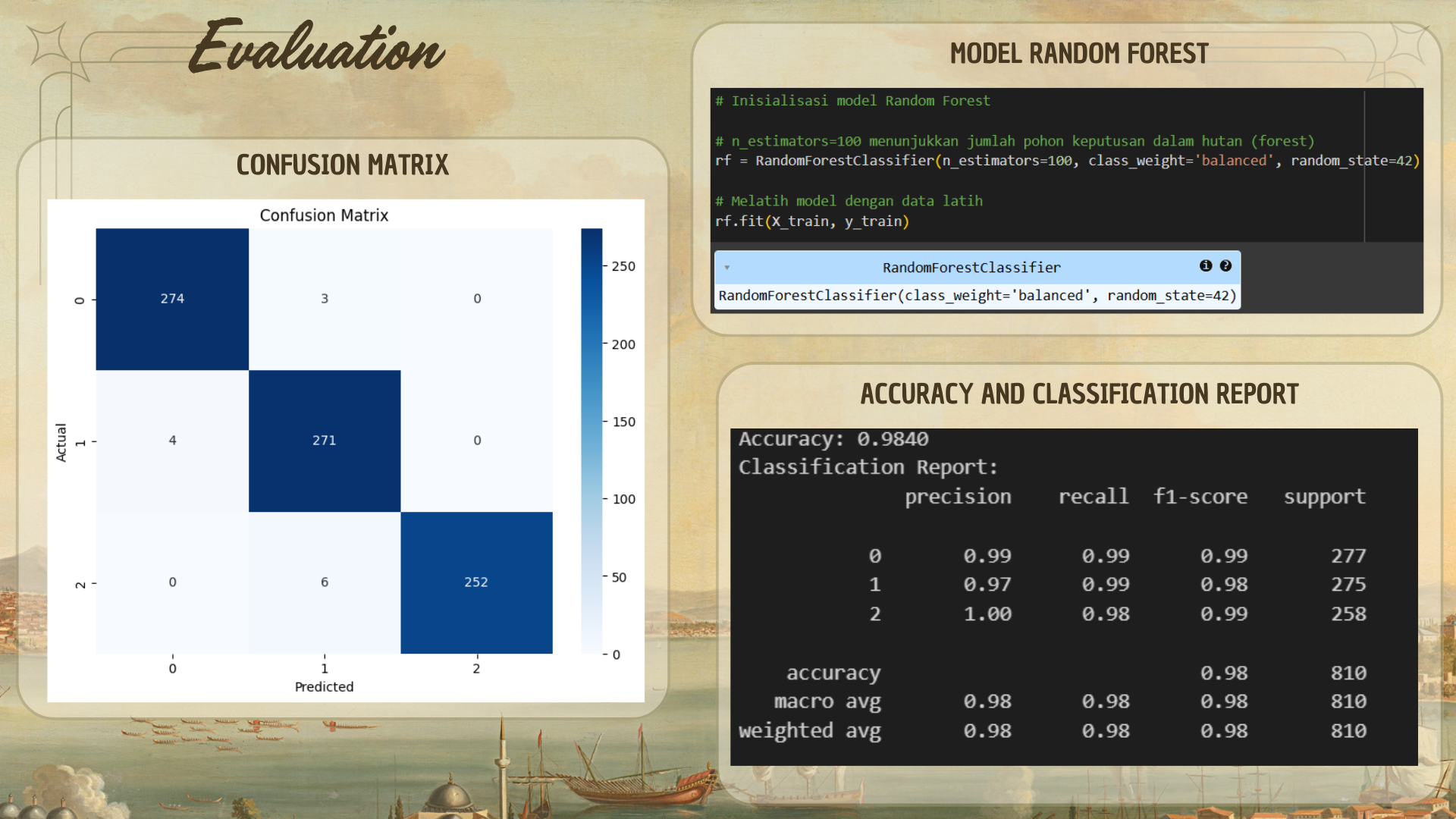
Akurasi = 98.40% (0.9840) menunjukkan bahwa sekitar 98.4% prediksi yang dilakukan oleh model adalah benar. Hal ini membuktikan bahwa model yang dibangun dapat memprediksi dengan sangat baik.
Classification Report
Classification Report memberikan lebih banyak detail daripada sekadar akurasi dan confusion matrix, dengan menampilkan metrik seperti Precision, Recall, dan F1-Score. Ini sangat berguna untuk mengukur kinerja model dalam klasifikasi multikelas.
- Precision mengukur berapa banyak prediksi positif yang benar-benar positif.
- Recall mengukur berapa banyak nilai positif yang dapat diprediksi dengan benar oleh model.
- F1-Score adalah rata-rata harmonik dari precision dan recall.

Hasil Classification Report:
1. Kelas 0 ("BAIK")
- Precision = 0.99: Dari semua prediksi yang dibuat model untuk kelas 0, 99% di antaranya benar. Ini menunjukkan bahwa model sangat akurat dalam mengidentifikasi "BAIK".
- Recall = 0.99: Dari semua data aktual yang benar-benar berada dalam kelas 0, 99% berhasil terdeteksi oleh model. Ini menunjukkan bahwa model hampir tidak melewatkan data kelas "BAIK".
- F1-Score = 0.99: Nilai F1-Score 0.99 menunjukkan keseimbangan yang baik antara precision dan recall.
2. Kelas 1 ("SEDANG")
- Precision = 0.97: Dari semua prediksi yang dibuat model untuk kelas 1, 97% di antaranya benar. Model cukup akurat dalam mengidentifikasi "SEDANG".
- Recall = 0.99: Dari semua data aktual yang benar-benar berada dalam kelas 1, 99% berhasil terdeteksi oleh model. Ini menunjukkan model tidak banyak melewatkan kelas "SEDANG".
- F1-Score = 0.98: F1-Score 0.98 menunjukkan keseimbangan yang sangat baik antara precision dan recall untuk kelas 1.
3. Kelas 2 ("TIDAK SEHAT")
- Precision = 1.00: Dari semua prediksi yang dibuat model untuk kelas 2, 100% di antaranya benar. Ini menunjukkan bahwa model sangat akurat dalam mengidentifikasi "TIDAK SEHAT".
- Recall = 0.98: Dari semua data aktual yang benar-benar berada dalam kelas 2, 98% berhasil terdeteksi oleh model. Ini menunjukkan bahwa model hampir tidak melewatkan data kelas "TIDAK SEHAT", meskipun ada sedikit kesalahan.
- F1-Score = 0.99: F1-Score 0.99 menunjukkan keseimbangan yang sangat baik untuk kelas "TIDAK SEHAT".
Confusion Matrix
Confusion Matrix adalah matriks yang digunakan untuk mengevaluasi kinerja klasifikasi, khususnya dalam hal pengelompokan data yang benar dan salah berdasarkan kategori prediksi dan yang sebenarnya. Dengan confusion matrix, kita bisa melihat True Positives (TP), True Negatives (TN), False Positives (FP), dan False Negatives (FN).


Analisis dari Confusion Matrix:
- Kelas 0 ("BAIK"): Model hampir sempurna dalam memprediksi kelas "BAIK", dengan hanya 3 kesalahan yang terdeteksi sebagai kelas "SEDANG".
- Kelas 1 ("SEDANG"): Model juga sangat baik dalam memprediksi kelas "SEDANG", dengan hanya 4 kesalahan yang terdeteksi sebagai kelas "BAIK".
- Kelas 2 ("TIDAK SEHAT"): Model sedikit lebih sering membuat kesalahan pada kelas ini, dengan 6 kesalahan yang terdeteksi sebagai kelas "SEDANG". Meskipun demikian, 252 data lainnya diprediksi dengan benar.
Deployment
Tahap deployment adalah langkah terakhir setelah proses modeling dan evaluasi untuk menerapkan model yang telah dibuat ke dalam dunia nyata, agar model dapat digunakan untuk memprediksi data baru secara otomatis. Pada tahap ini, model yang sudah dilatih dan diuji akan dipindahkan ke dalam lingkungan produksi atau sistem yang siap digunakan oleh pengguna atau aplikasi.
Menyimpan Model
Model yang telah dilatih akan disimpan ke dalam file, sehingga bisa digunakan kembali tanpa harus melatih model dari awal.

Melakukan Prediksi dan Export Hasil

Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Master Class On Job Training : Data Science

