
Review IMDB Visualisasi BerTopic
Muhammad Nugi Ramadhan



Summary
Proyek ini berfokus pada analisis ulasan film dari platform IMDb menggunakan model topic modeling BerTopic. Tujuan utama dari proyek ini adalah untuk mengidentifikasi dan memvisualisasikan tema atau topik utama yang sering muncul dalam ulasan film. Proyek ini tidak hanya menampilkan kemampuan dalam pengolahan data teks dan pemodelan topik, tetapi juga keterampilan visualisasi data untuk menyampaikan informasi secara efektif dan menarik.
Description
Langkah-langkah pengerjaan:
A. Memilih Dataset

Hal pertama yang kita lakukan adalah memilih dataset yang akan dianalisis. Untuk proyek ini, kita menggunakan dataset "IMDB Review" dari Kaggle, yang berisi ulasan film beserta sentimen positif atau negatifnya. Setelah itu kita menggunakan model BERTopic untuk mengidentifikasi dan memvisualisasikan topik utama yang muncul dari kumpulan ulasan tersebut.
B. Memuat Dataset

Pada tahap Memuat Dataset, kita menghubungkan Google Colab dengan Google Drive agar dataset "IMDB Dataset.csv" dapat diakses. Setelah Drive berhasil terhubung, kita memuat dataset dan melakukan pengecekan data awal untuk memastikan bahwa data terbaca dengan benar. Pada dataset ini, kolom "review" berisi teks ulasan film, sementara kolom "sentiment" berisi label sentimen dari ulasan tersebut, yaitu positif atau negatif.
C. EDA
Langkah Exploratory Data Analysis (EDA) bertujuan untuk mendapatkan pemahaman awal tentang dataset. Pada tahap ini, kita menganalisis frekuensi sentimen (positif atau negatif) untuk memahami pola dalam data. Visualisasi grafik batang dan grafik histogram yang digunakan untuk memperjelas distribusi data dan membantu menemukan pola yang relevan dalam ulasan film.

Program diatas menunjukkan distribusi panjang ulasan (review length) dalam dataset IMDb. Grafik berupa histogram dengan kurva kernel density estimate (KDE) yang memberikan gambaran frekuensi panjang ulasan dalam satuan karakter. Sebagian besar ulasan memiliki panjang di bawah 2000 karakter, dengan puncak distribusi berada pada rentang yang lebih pendek, menandakan bahwa ulasan cenderung ringkas. Grafik ini membantu mengidentifikasi pola umum panjang ulasan yang dapat digunakan dalam analisis lebih lanjut, seperti pemrosesan teks atau model pembelajaran mesin.

Program diatas menunjukkan distribusi sentimen ulasan dalam dataset IMDb menggunakan diagram batang. Terdapat dua kategori sentimen, yaitu positive dan negative, dengan jumlah yang hampir seimbang. Masing-masing kategori memiliki jumlah ulasan sekitar 25.000. Visualisasi ini memberikan gambaran umum tentang proporsi data sentimen, yang penting untuk analisis lebih lanjut seperti pelatihan model sentiment analysis. Hal ini juga menunjukkan bahwa dataset cukup seimbang, sehingga dapat mendukung model pembelajaran mesin secara lebih akurat tanpa risiko bias yang signifikan terhadap salah satu kategori.
D. Preprocessing

Pada tahap Preprocessing, kita membersihkan teks dalam dataset "IMDB Dataset.csv" agar siap untuk analisis lebih lanjut. Proses ini mencakup beberapa langkah penting: mengonversi semua teks ulasan menjadi huruf kecil, menghapus tanda baca serta karakter khusus, dan membersihkan teks dari variasi tag `<br>` yang sering muncul. Dengan langkah-langkah ini, kita memastikan bahwa teks ulasan dalam kolom “new_review”.
E. Model Building

Pada tahap Model Building, kita menggunakan model BERTopic untuk mengidentifikasi topik yang muncul dari ulasan dalam dataset "IMDB Dataset.csv". Pertama, kita membuat objek model BERTopic, yang kemudian diterapkan pada teks ulasan yang sudah dibersihkan di kolom "new_review". Model ini mengekstrak topik utama dari kumpulan data dan menghitung probabilitas tiap ulasan untuk masing-masing topik. Dengan pendekatan ini, kita dapat memahami tema-tema utama yang mendominasi ulasan film serta melihat distribusi topik dalam data.
F. Model Evaluation

Tahap Evaluasi Model berfokus pada penilaian kualitas topik yang dihasilkan dari ulasan film dalam dataset "IMDB Dataset.csv". Pada tahap ini, kita menganalisis topik-topik utama yang ditemukan oleh model BERTopic dan menilai seberapa relevan topik tersebut terhadap konten ulasan. Visualisasi model digunakan untuk memberikan pandangan yang lebih mudah tentang distribusi topik serta hubungan antar topik yang dihasilkan, sehingga kita dapat memahami pola dan tema yang mendominasi dalam kumpulan ulasan ini.
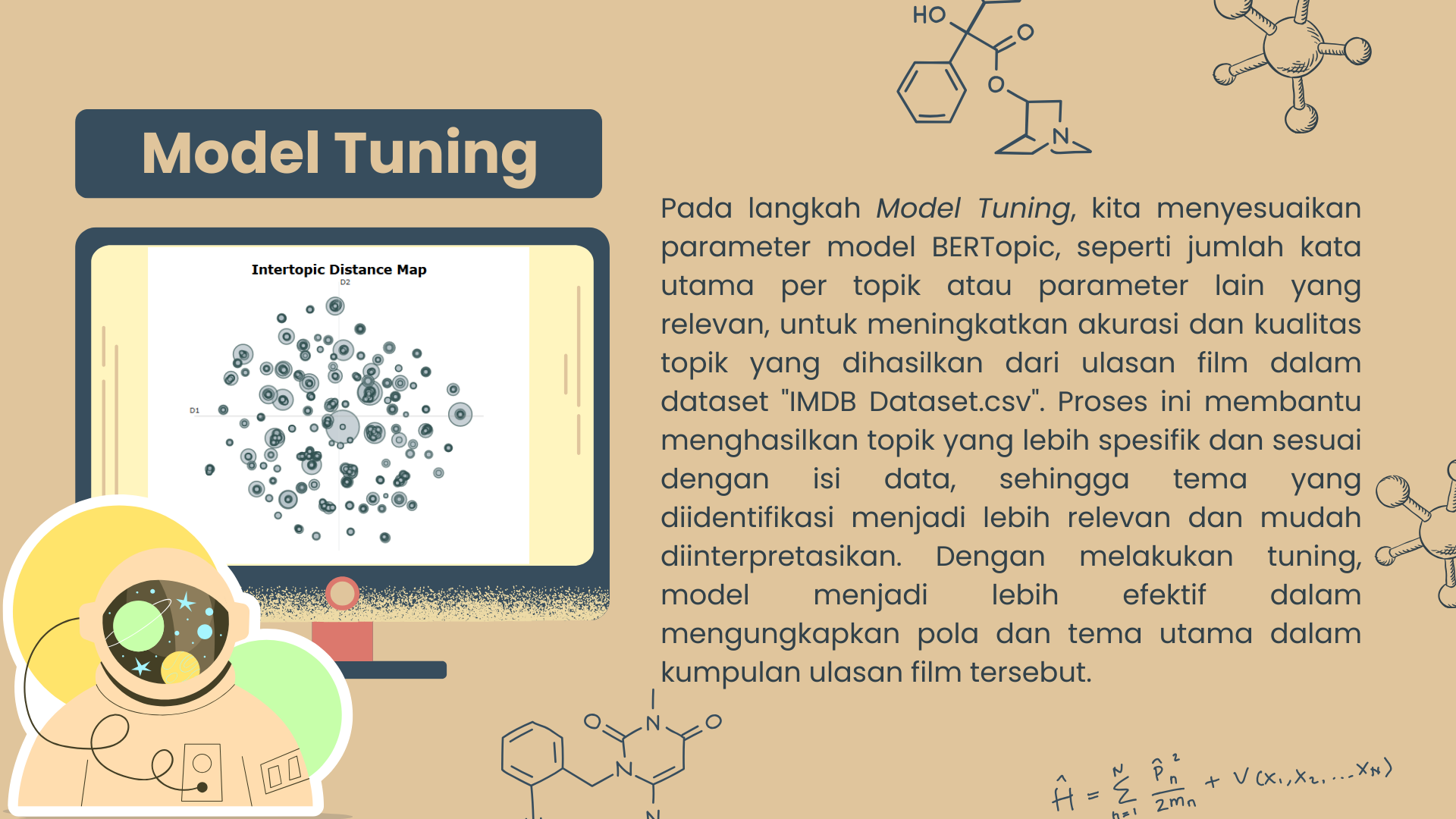
G. Model Tuning

Pada langkah Model Tuning, kita menyesuaikan parameter model BERTopic, seperti jumlah kata utama per topik atau parameter lain yang relevan, untuk meningkatkan akurasi dan kualitas topik yang dihasilkan dari ulasan film dalam dataset "IMDB Dataset.csv". Proses ini membantu menghasilkan topik yang lebih spesifik dan sesuai dengan isi data, sehingga tema yang diidentifikasi menjadi lebih relevan dan mudah diinterpretasikan. Dengan melakukan tuning, model menjadi lebih efektif dalam mengungkapkan pola dan tema utama dalam kumpulan ulasan film tersebut.
H. Interpretasi Hasil

Langkah terakhir adalah Interpretasi Hasil, di mana kita meninjau kata-kata utama (representations) dan contoh ulasan (representative documents) untuk setiap topik yang dihasilkan oleh model dari dataset "IMDB Dataset.csv". Interpretasi ini memungkinkan kita untuk memahami tema dan konteks dari setiap topik, serta menghubungkannya dengan isi ulasan asli dalam data. Langkah ini memberikan wawasan yang lebih mendalam mengenai topik yang muncul dari ulasan film, sehingga siap digunakan dalam laporan atau analisis lebih lanjut.
Link Program Colab: https://colab.research.google.com/drive/1Wwo_znRnYgBZEXpc75_K-uD5hpxE3xU3?usp=sharing
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Data Science



