
Komparasi Algoritma Regresi untuk harga Alpukat
Ahmad Sholihin


Summary
Komparasi Algoritma Regresi adalah sebuah program dari bahasa pemrograman python yang digunakan untuk menentukan harga dari buah alpukat. Algoritma yang akan di komparasi adalah algoritma Random Forest, KNN, SVM, Deep Neural Network, Decision Tree, dan Linear Regression.
Description
Latar Belakang
Alpukat (Persea americana) adalah buah tropis atau subtropis yang berasal dari Amerika Selatan. Buah ini disebut-sebut sebagai satu dari beragam buah paling bergizi. Alpukat tidak hanya punya tekstur yang unik dan rasa yang enak, tetapi juga memiliki kandungan gizi yang luar biasa. Ada karbohidrat, protein, lemak, vitamin, hingga mineral yang memperkaya kandungan buah ini. Alpukat juga kaya antioksidan, seperti lutein. Hal ini terbukti karena di dalam 100 g alpukat, terdapat 271 mcg atau sekitar 0,271 mg lutein.
Kandungan gizi yang terkandung di dalam buah alpukat dapat membantu Anda memenuhi kebutuhan gizi harian. Buah ini juga memiliki banyak manfaat untuk kesehatan tubuh. Beragam manfaat atau khasiat buah alpukat di antaranya yakni:
- Menjaga kesehatan jantung
- Melancarkan sistem pencernaan
- Menjaga kesehatan kulit
- Menjaga kesehatan mata
- Dan masih banyak lagi manfaat dari buah alpukat
Dataset dan Library
Dataset yang digunakan dalam proyek ini diperolah dari Kaggle open dataset dan library yang digunakan yaitu Pandas, Numpy, Matplotlib, Seaborn, Scikit-Learn dan Tensorflow. Serta Algoritma yang akan digunakan adalah Random Forest, KNN, SVM, Deep Neural Network, Decision Tree, Linear Regression.
Pengenalan Algoritma
Algoritma Random Forest disebut sebagai salah satu algoritma machine learning terbaik, sama seperti Naïve Bayes dan Neural Network. Random Forest adalah kumpulan dari decision tree atau pohon keputusan. Algoritma ini merupakan kombinasi masing-masing tree dari decision tree yang kemudian digabungkan menjadi satu model. Biasanya, Random Forest dipakai untuk masalah regresi dan klasifikasi dengan kumpulan data yang berukuran besar
K-nearest neighbor adalah salah satu algoritma machine learning dengan pendekatan supervised learning yang bekerja dengan mengkelaskan data baru menggunakan kemiripan antara data baru dengan sejumlah data (k) pada lokasi yang terdekat yang telah tersedia. Algoritma ini menerapkan lazy learning” atau “instant based learning” dan merupakan algoritma non parametrik. Algoritma KNN digunakan untuk klasifikasi dan regresi.
Algoritma Support Vector Machine merupakan salah satu algoritma yang termasuk dalam kategori Supervised Learning, yang artinya data yang digunakan untuk belajar oleh mesin merupakan data yang telah memiliki label sebelumnya. Sehingga dalam proses penentuan keputusan, mesin akan dikategorikan data testing ke dalam label yang sesuai dengan karakteristik yang dimiliki nya.
Algoritma DNN (Deep Neural Networks) adalah salah satu algoritma berbasis jaringan saraf yang dapat digunakan untuk pengambilan keputusan. Algoritma ini merupakan pengembangan dari Algoritma JST (Jaringan Saraf Tiruan). Pengertian Deep Neural Networks yang paling umum adalah jaringan saraf tiruan yang memiliki lebih dari 1 lapisan saraf tersembunyi. Menurut teori jurnal penelitian, algoritma ini dapat menyelesaikan beberapa kasus yang tidak bisa diselesaikan dengan algoritma JST. Sebagai alternatif, algoritma ini dapat menggantikan algoritma JST yang menggunakan banyak sekali saraf pada lapisan tersembunyi.
Decision tree merupakan suatu struktur yang digunakan untuk membantu proses pengambilan keputusan. Disebut sebagai “tree” karena struktur ini menyerupai sebuah pohon lengkap dengan akar, batang, dan percabangannya. Dalam data science, struktur decision tree dapat membantu ambil keputusan efektif dan tetap memperhatikan kemungkinan hasil serta konsekuensinya.
Regresi linier atau linear regression merupakan jenis algoritma supervised learning yang digunakan untuk mengidentifikasi hubungan antara variabel dependen/terikat dan satu atau lebih variabel independen/bebas dan biasanya digunakan untuk membuat prediksi di masa depan.
Langkah Pembuatan Program
Data Understanding memberikan gambaran awal tentang :
- Kekuatan data
- Kekurangan dan Batasan pengguna data
- Tingkat kesesuaian data dengan masalah bisnis yang akan dipecahkan
- Ketersediaan data (terbuka/tertutup biaya akses ,dsb
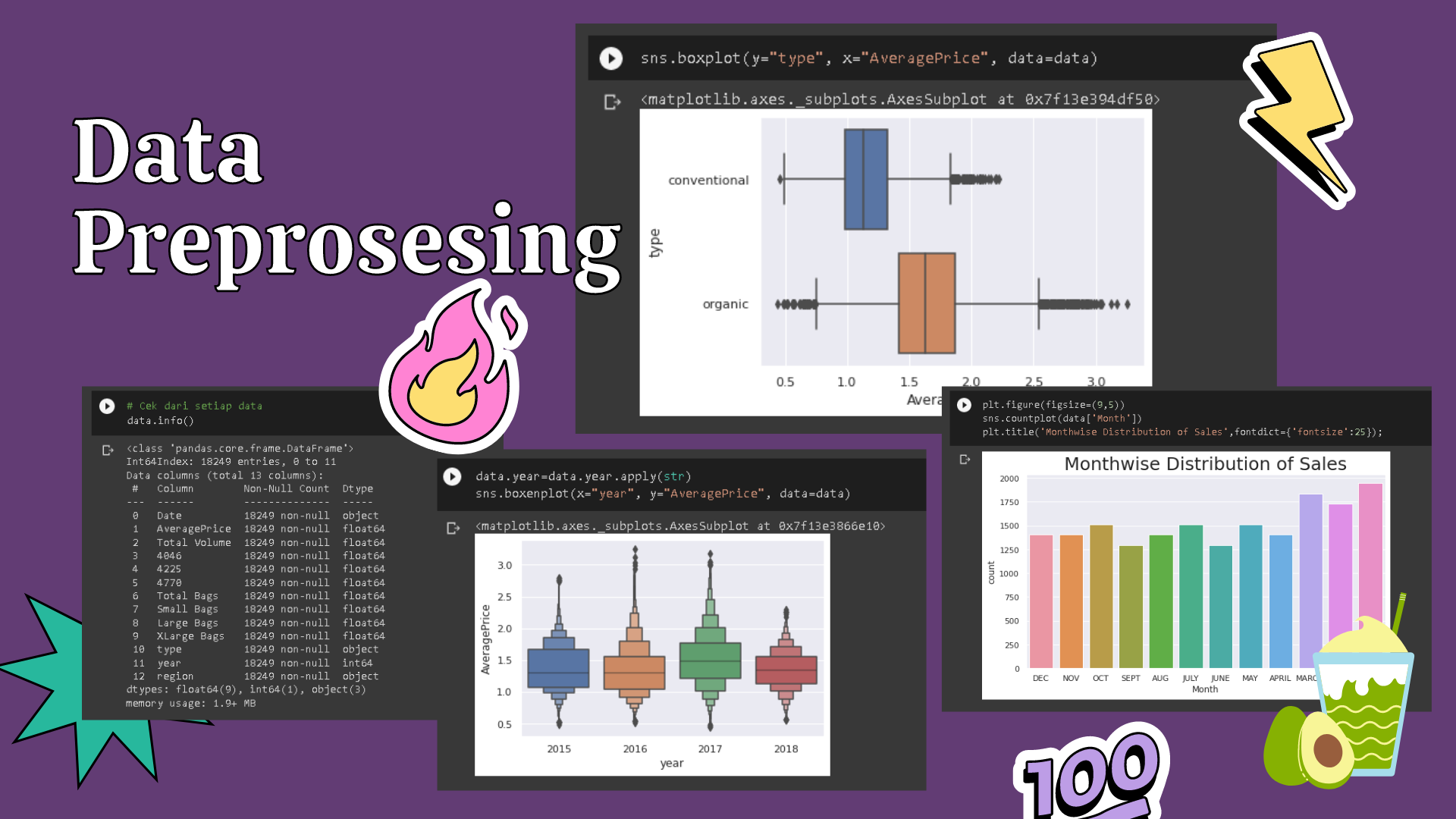
Data preprocessing adalah proses yang mengubah data mentah ke dalam bentuk yang lebih mudah dipahami. Proses ini penting dilakukan karena data mentah sering kali tidak memiliki format yang teratur. Selain itu, data mining juga tidak dapat memproses data mentah, sehingga proses ini sangat penting dilakukan untuk mempermudah proses berikutnya, yakni analisis data.

Machine learning model adalah hasil dari fase latih (training phase) dalam pemelajaran mesin. Training phase ini gunanya untuk menemukan pola-pola di dalam data yang hendak dijadikan dasar pengetahuan sistem yang dibangun. Pola-pola tersebut yang disebut sebagai model. Bisa juga dari pengertian Machine learning model adalah algoritma machine learning yang sebelumnya telah dilakukan proses pelatihan/training dengan data latih tertentu sehingga dia siap digunakan untuk melakukan prediksi terhadap data baru.

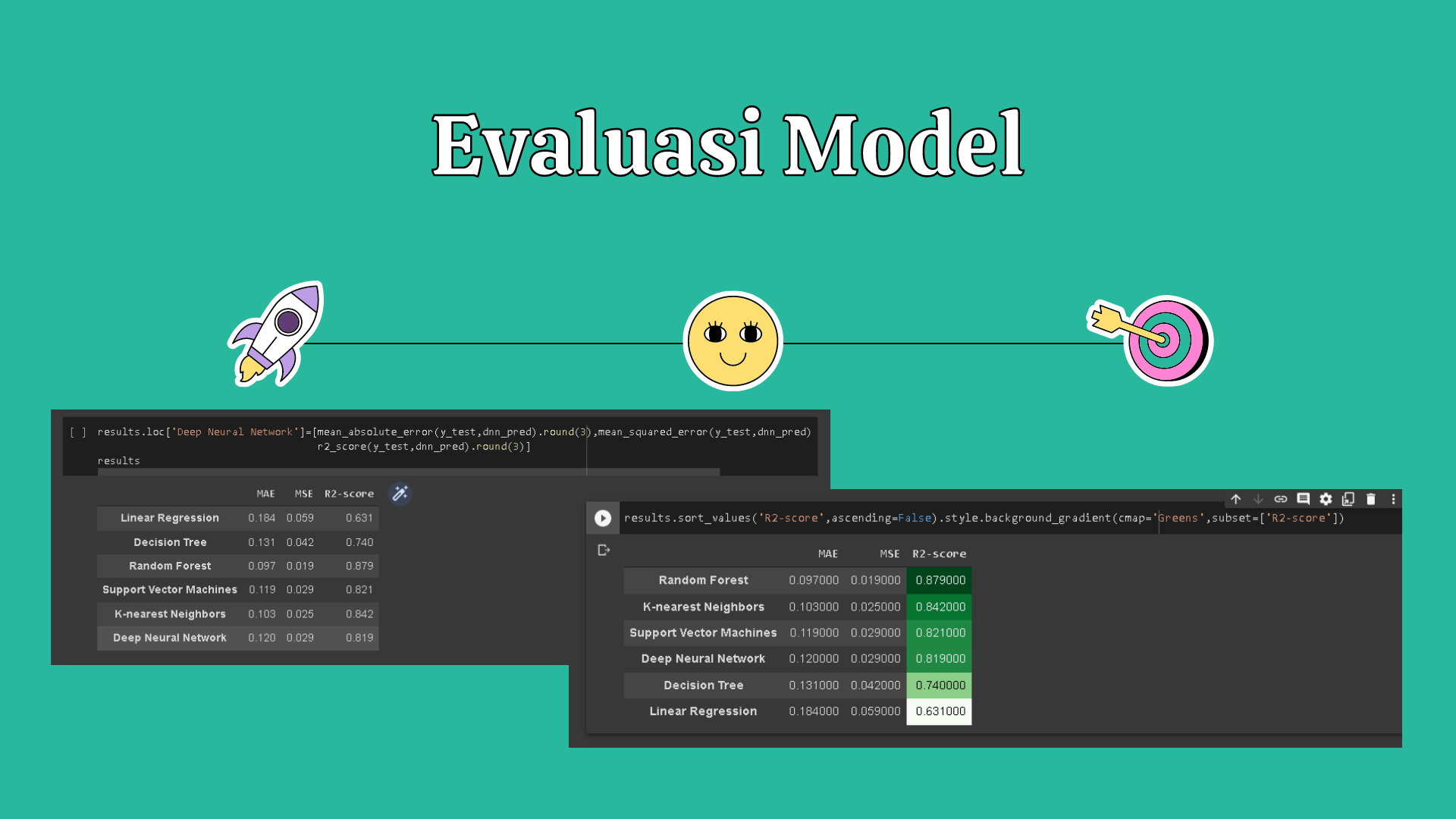
Metode evaluasi Model yang digunakan adalah
- MAE atau Mean Absolute Error menunjukkan nilai kesalahan rata-rata yang error dari nilai sebenarnya dengan nilai prediksi. MAE sendiri secara umum digunakan untuk pengukuran prediksi error pada analisis time series.
- Untuk menghitung nilai MSE sama halnya dengan RMSE. Hanya saja tidak menggunakan proses akar. Pada tahap ini, jika nilai error nya semakin besar maka semakin besar nilai MSE yang dihasilkan.
- R squared merupakan angka yang berkisar antara 0 sampai 1 yang mengindikasikan besarnya kombinasi variabel independen secara bersama – sama mempengaruhi nilai variabel dependen. Semakin mendekati angka satu, model yang dikeluarkan oleh regresi tersebut akan semakin baik.
Berikut hasil dari evaluasi yang telah dilakukan

Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Machine Learning For Beginner

