
Simple Classification using IRIS dataset
Andi Reza Fathurrizky



Summary
Judul ini merujuk pada penggunaan teknik pembelajaran mesin yang paling dasar untuk membedakan jenis bunga iris berdasarkan karakteristik fisiknya. Dataset iris adalah kumpulan data yang sering digunakan sebagai contoh awal dalam pembelajaran mesin karena sifatnya yang sederhana namun efektif untuk menjelaskan konsep dasar klasifikasi.
Description
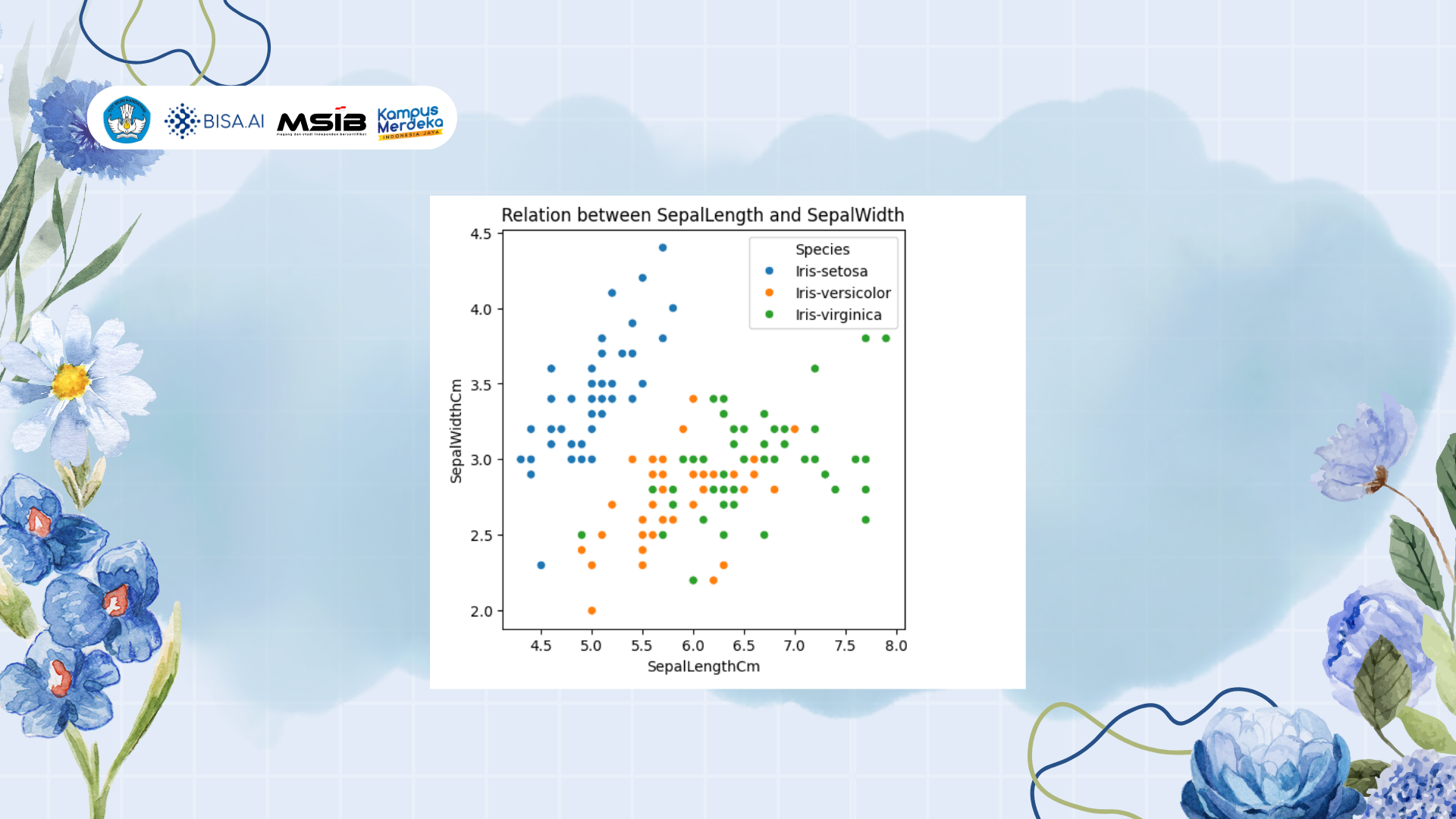
Dataset Iris adalah Kumpulan data yang berisi informasi tentang berbagai jenis bunga iris, seperti panjang kelopak, lebar kelopak, panjang mahkota, dan lebar mahkota, output yang diinginkan adalah kita dapat mengelompokkan / mengklasifikasikan apakah data tersebut termasuk Iris-setosa, Iris-versicolor, atau Iris-virginica.
1. Import Libraries
- Langkah pertama adalah mengimport semua library yang dibutuhkan untuk melatih dataset.

2. Load Dataset
- kemudian meload dataset untuk melihat karakteristik dari data dataset yang akan dilatih.

3. Exploratory Data Analysis
- Selanjutnya lakukan tahapan Exploratory Data Analysis atau analisis data. Hal tersebut untuk memberikan pemahaman terkait dataset yang dipunya mulai dari tipe datanya, panjang baris atau kolom didalamnya, serta bagaimana penyebaran atau distribusi data tersebut guna memastikan adanya outlier atau tidak.


4. Preprocessing Data
- Setelah itu lakukan tahap preprocessing guna menyiapkan dataset tersebut sebelum nantinya dilakukan pembuatan model. Hal tersebut meliputi langkah-langkah yang meliputi: pengecekan data atau baris yang mengandung nilai null, serta penghapusan baris atau kolom yang tidak dibutuhkan nantinya saat pembuatan model tersebut.

5. Train-Test Split
- Setelah data tersebut sudah dipastikan dapat digunakan untuk modelling, nantinya akan dilakukan train-test split guna membagi data training dan data testing. Dalam Train-Test split yang saya lakukan 70% dari total data akan saya jadikan data training dan sedangkan 30% lainnya saya jadikan data testing.

6. Model Building
- Setelah itu dilakukan tahap pembuatan model menggunakan algoritma dari Machine Learning. Untuk melakukan pemilihan algoritma tentunya diutamakan algoritma yang biasanya dipakai untuk kasus klasifikasi, yang dimana pada kasus ini saya menggunakan algoritma naive bayes.

7. Model Evaluation
- dan yang terakhir adalah evaluasi model, untuk melihat apakah model tersebut sudah menunjukkan hasil yang baik atau belum memenuhi kriteria yang diinginkan, pada kasus ini saya menggunakan metrik berupa accuracy score, serta precison, recall dan f1 score yang memang dikhususkan untuk model klasifikasi.

Kesimpulannya, algoritma Naive Bayes merupakan pilihan yang baik untuk memulai pemodelan klasifikasi. Namun, penting untuk diingat bahwa pemilihan algoritma yang tepat sangat bergantung pada karakteristik data dan tujuan analisis.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Machine Learning For Beginner
