
Model CNN pada Spectogram dalam Sistem Backend
Joannita Putri Maharani



Summary
Proyek ini bertujuan untuk mengembangkan dan menerapkan model NLP berbasis spektogram yang mampu mengenali dan memproses pola suara. Dengan memanfaatkan data spektogram sebagai input utama, sistem ini dapat mengenali kata, emosi, atau informasi penting lain yang terdapat dalam sinyal suara. Implementasi dilakukan di sisi backend dengan memanfaatkan teknik inferensi model, sehingga dapat berfungsi secara efisien pada aplikasi yang membutuhkan respons cepat dan real-time.
Description
Model Natural Language Processing (NLP) berbasis spektrum suara, seperti spektogram, biasanya diterapkan pada sistem backend dengan memanfaatkan teknik inferensi untuk melakukan prediksi atau klasifikasi terhadap data suara yang diinputkan. Spektogram adalah representasi visual dari frekuensi suara dalam domain waktu. Hasilnya adalah sebuah gambar 2D yang menunjukkan intensitas frekuensi suara dalam rentang waktu tertentu.
- PENGEMBANGAN MODEL DAN PELATIHAN
Menghubungkan Google Drive ke Google Colab

Dengan perintah ini, Google Drive akan muncul sebagai direktori pada Colab, memungkinkan untuk mengakses, membaca, dan menulis file di dalamnya.
Mengimport Library

Kode di atas mengimpor berbagai pustaka dan modul yang diperlukan untuk memproses data, membangun model, dan mengevaluasi performanya dalam proyek berbasis visi komputer atau pengenalan pola. Berikut adalah penjelasan tiap bagian dari kode:
- import os: Modul ini digunakan untuk berinteraksi dengan sistem operasi, seperti untuk manipulasi file dan folder.
- import glob: Modul glob berguna untuk menemukan semua file atau folder yang cocok dengan pola tertentu, misalnya mencari semua file gambar dengan ekstensi .png dalam suatu direktori.
- import cv2: Ini mengimpor pustaka OpenCV, yang populer untuk manipulasi gambar, pemrosesan video, dan visi komputer. Fungsi dalam OpenCV dapat digunakan untuk memuat, memproses, dan menyimpan gambar.
- import numpy as np: numpy adalah pustaka fundamental untuk operasi komputasi ilmiah di Python, terutama untuk bekerja dengan array multidimensi dan berbagai operasi matematis.
- import matplotlib.pyplot as plt: matplotlib menyediakan fungsi untuk membuat visualisasi data seperti grafik dan plot. Dalam konteks ini, biasanya digunakan untuk menampilkan gambar atau grafik pelatihan model.
- from sklearn.model_selection import train_test_split: Fungsi ini membagi dataset menjadi dua bagian: data pelatihan dan data uji, yang penting untuk melatih model pada satu subset data dan menguji kinerjanya pada subset lain.
- from tensorflow.keras.utils import to_categorical: to_categorical mengonversi label numerik menjadi format one-hot encoding, yang biasa digunakan dalam klasifikasi untuk menyandikan label kelas menjadi vektor biner.
- from tensorflow.keras.optimizers import SGD: SGD adalah singkatan dari Stochastic Gradient Descent, salah satu algoritme optimasi yang digunakan dalam pelatihan model neural network.
- from sklearn.metrics import classification_report, confusion_matrix: Modul ini menyediakan metrik evaluasi seperti laporan klasifikasi dan matriks kebingungan (confusion matrix) untuk mengevaluasi performa model klasifikasi.
- from keras.models import Sequential: Sequential adalah tipe model dalam Keras yang memungkinkan kita membuat model lapisan demi lapisan secara berurutan, cocok untuk jaringan neural yang lapisannya linear.
- from keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense: Ini mengimpor lapisan-lapisan umum yang digunakan dalam membangun CNN (Convolutional Neural Network), yaitu: Conv2D: Lapisan konvolusi untuk ekstraksi fitur dari gambar, MaxPooling2D: Lapisan pooling untuk mengurangi dimensi spasial dari data fitur, Dropout: Teknik regulasi untuk mencegah overfitting dengan menghilangkan sebagian neuron selama pelatihan, Flatten: Meratakan data dari bentuk 2D menjadi 1D untuk lapisan penuh, dan Dense: Lapisan penuh yang umum digunakan dalam lapisan akhir klasifikasi.
- import pickle: pickle adalah modul yang digunakan untuk serialisasi data, memungkinkan kita untuk menyimpan dan memuat model, data, atau objek lainnya.
- import h5py: h5py adalah pustaka yang memungkinkan penyimpanan dan pemrosesan dataset berukuran besar dalam format HDF5, yang sering digunakan untuk menyimpan model atau data pelatihan yang besar.
Memproses Dataset Gambar Spektogram

Kode ini melakukan pengambilan gambar dari folder dataset spektogram, mengubah ukuran gambar menjadi 70x70 piksel, dan menyimpan data gambar beserta labelnya ke dalam array NumPy. Data ini kemudian siap digunakan untuk pelatihan model, yang membutuhkan input berupa gambar.
Menghitung Jumlah Array X

Menghitung dan mengembalikan jumlah elemen dalam list atau array X. X adalah list yang berisi gambar-gambar spektogram yang telah diproses dan diubah ukurannya menjadi array NumPy.
Menampilkan Salah Satu Gambar

Kode ini bertujuan untuk memverifikasi bahwa gambar yang dimuat dari dataset telah diproses dengan benar.
Pre-Processing

Tujuan dari Preprocessing
- Pembagian Dataset: Memastikan bahwa model dilatih dan diuji pada data yang berbeda untuk menghindari overfitting.
- Normalisasi: Memastikan bahwa data input berada dalam rentang yang sesuai untuk pemrosesan lebih lanjut dan pelatihan model.
- Konversi Label: Memudahkan model dalam menginterpretasi label selama pelatihan, terutama dalam kasus klasifikasi multikelas.
Arsitektur Model

Kode ini mendefinisikan arsitektur CNN yang sederhana namun efektif untuk pengenalan pola dalam gambar, khususnya untuk tugas klasifikasi. Model ini siap untuk dilatih dengan data yang telah diproses sebelumnya.
Kompile Model

Kode ini menyusun model CNN untuk pelatihan dengan mengatur parameter penting seperti jumlah epoch, laju pembelajaran, dan memilih fungsi kehilangan yang sesuai. Dengan menggunakan optimizer SGD, model akan dilatih untuk mengenali pola dalam gambar spektogram dan mengklasifikasikannya ke dalam salah satu dari tiga kelas yang telah ditentukan. Ringkasan model yang ditampilkan memberikan gambaran yang jelas tentang arsitektur model dan parameter yang digunakan.
Training


Kode ini menyelesaikan proses pelatihan model CNN dengan menggunakan data pelatihan dan memvalidasinya dengan data pengujian. Setelah pelatihan selesai, model dievaluasi, dan akurasinya dicetak untuk memberikan gambaran tentang seberapa baik model dalam mengklasifikasikan gambar spektogram ke dalam tiga kelas yang telah ditentukan.
Prediksi

Untuk menerapkan model yang telah dilatih pada data pengujian, menghasilkan prediksi, dan menyiapkan langkah-langkah untuk menganalisis dan mengevaluasi kinerja model tersebut.
Iterasi X_test

Bertujuan untuk mengonversi hasil prediksi probabilitas dan label asli dari format probabilitas kategorikal menjadi format yang lebih sederhana dan mudah dipahami yaitu indeks kelas.
Klasifikasi

Bertujuan untuk memberikan analisis mendalam tentang kinerja model klasifikasi dengan cara yang terstruktur.
Menyimpan Model

Digunakan untuk menyimpan model yang telah dilatih ke dalam file dengan format HDF5 (.h5).
- INTEGRASI KE BACKEND
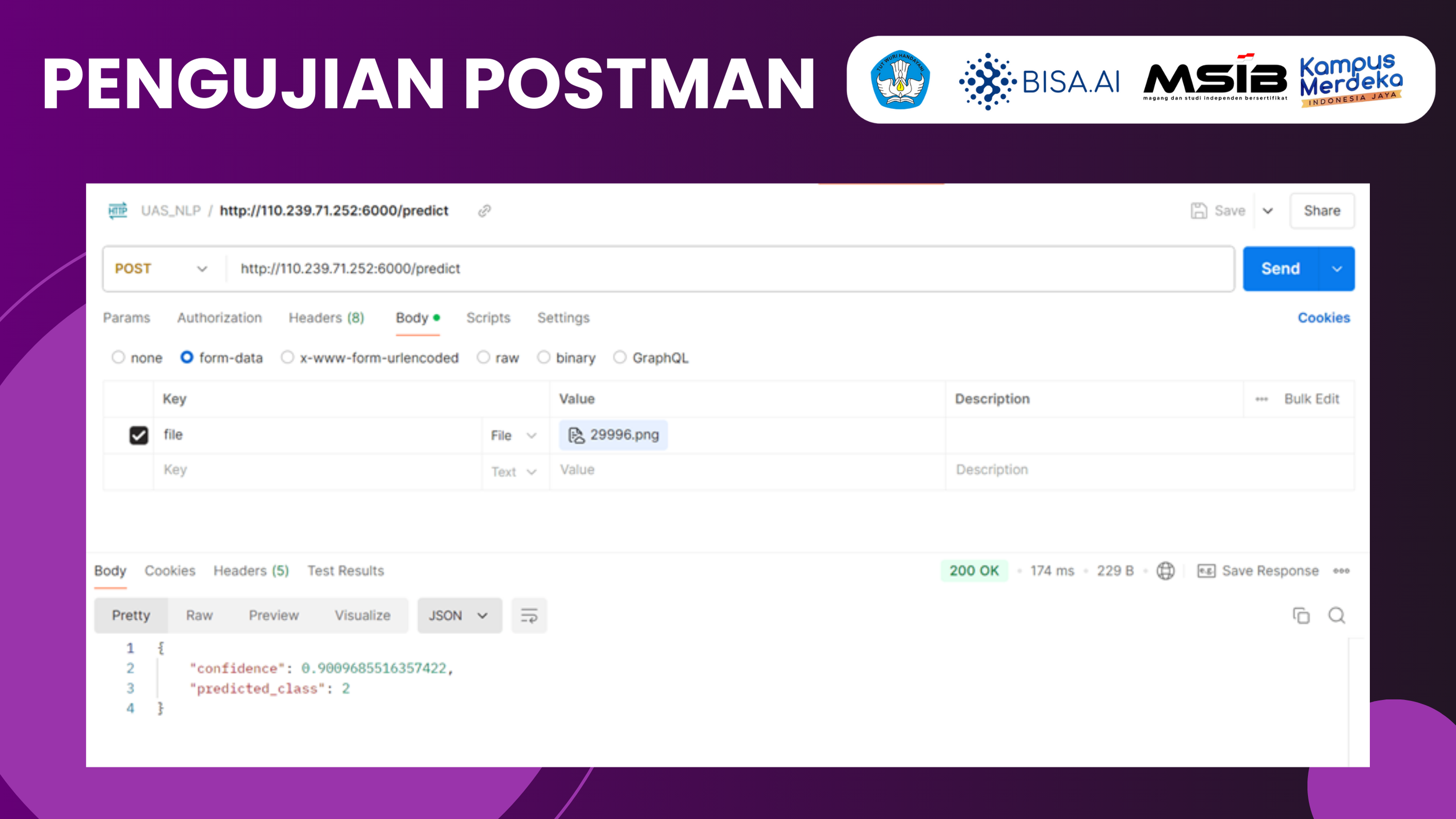
Aplikasi Flask yang digunakan untuk melakukan inferensi model deep learning pada gambar. Model deep learning yang digunakan adalah model klasifikasi gambar yang dimuat dari file model.h5. Aplikasi ini menyediakan endpoint /predict yang menerima file gambar melalui metode POST. Setelah menerima gambar, aplikasi melakukan preprocessing dengan mengubah gambar ke mode RGB, mengatur ukurannya menjadi 70x70 pixel (sesuai dengan input model), dan melakukan normalisasi. Setelah itu, gambar yang telah diproses diberikan ke model untuk menghasilkan prediksi. Respons yang dihasilkan mengandung kelas hasil prediksi (predicted_class) dan tingkat kepercayaan (confidence). Aplikasi ini berjalan di port 6000 dengan pengaturan debug aktif.


- PENGUJIAN POSTMAN

Informasi Course Terkait
Kategori: Natural Language ProcessingCourse: Image Processing with OpenCV



