
Fantasy Premier League (FPL) Data Analysis
I Dewa Gede Natih Bernan


Summary
In this analysis we will dive down into the players database in the Fantasy Premier League (FPL) game, especially from season 2024/25.
For those of you who are not familiar, FPL is a football fantasy game where you score points based on the real-life player you selected who plays in the English Premier League. If you're into football and data analytics, this is the game for you! Go check it out: https://fantasy.premierleague.com/
We will do some **exploratory data analysis** to find some interesting facts that can help us win the game! Also, we will also try to create a model that can **predict the total points** from a player based on his stats.
Description
Import Dataset
We will use a comprehensive dataset of players in FPL from season 2024/25, provided by [Paolo Mazza](https://www.kaggle.com/meraxes10) on Kaggle.
Here is the link to download the dataset: https://www.kaggle.com/datasets/meraxes10/fantasy-premier-league-dataset-2024-2025 (last update: 29 Oct 2024)

Data Preprocessing
First, we will look at the types of the features provided in the dataset

We have **80** features in the dataset, which have various types such as integer, float, and object.
Now we will check for any missing values in the dataset.

We can see that 8 out of 80 of our features have quite a lot of missing values. For example, 'penalties_order' is the rank of a player based on the number of penalties he has taken, so if he never took a penalty then the value will be missing. Same goes for 'direct_freekicks_order' and 'corners_and_indirect_freekicks_order'. We can just ignore these features.
Next, for 'news', 'chance_of_playing_this_round', 'chance_of_playing_next_round', 'news_added', and 'region' columns will be filled if there is a news for the player, for example the player is injured, moved to another club outside of the Premier League, etc. We can also ignore these features.

We now have only 72 features left with no more missing values. Now let's get to the interesting part!
Exploratory Data Analysis
Let's start with the most basic question: how many players are there in the Premier League?

Now let's check the descriptive statistics of our data.

Next, we would like to know how many players are there from each position (GKP, DEF, MID, FWD). We will use a simple pie chart for this.


Almost half of the players are Midfielders (MID)! There are so many to choose from! This makes sense because in the game we must pick 5 midfielders for our team out of 15 players total
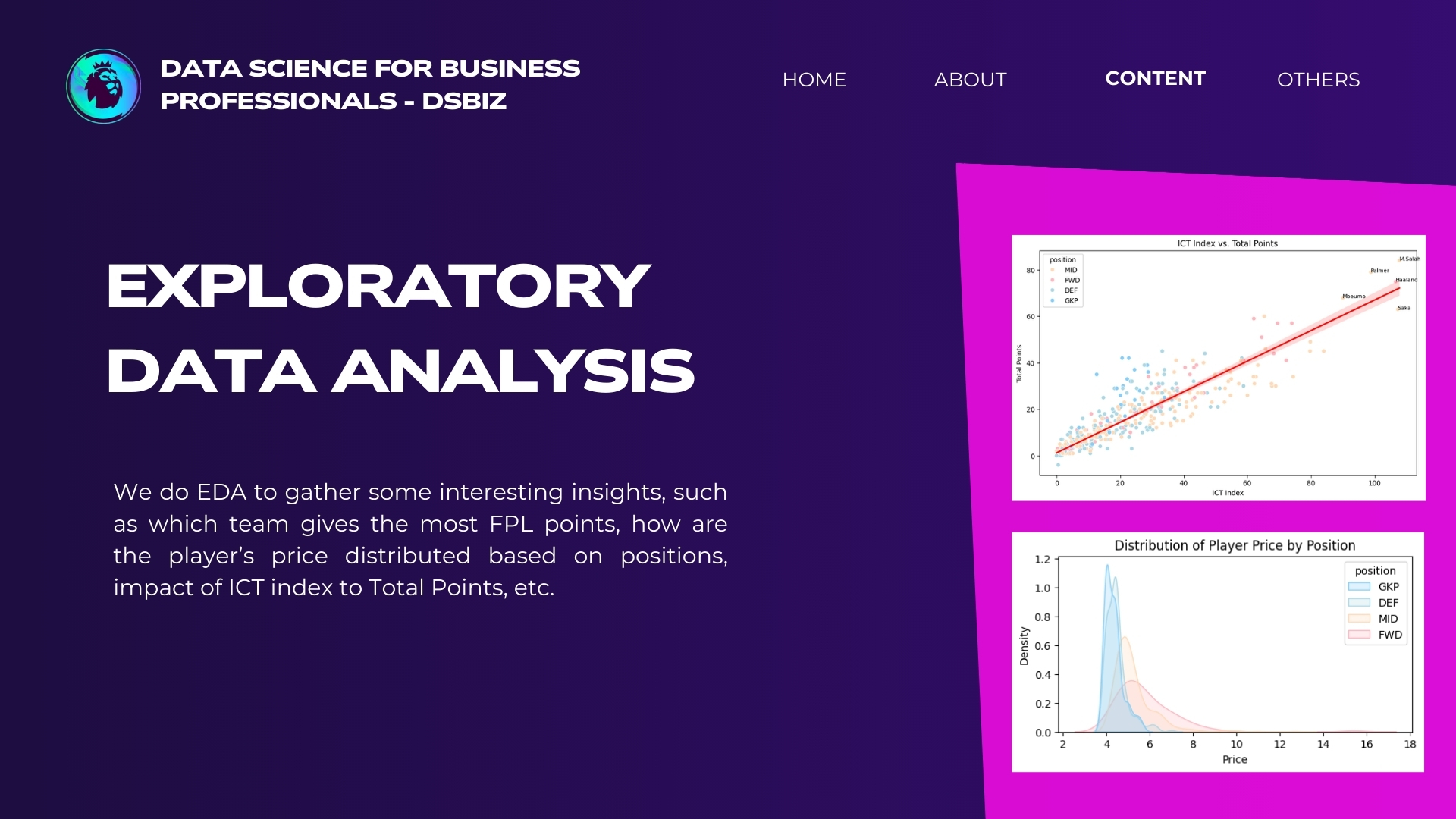
Let's try another thing. Suppose we would like to know how FPL price their players based on position. Is any particular position tends to be more expensive than the others?


We can see that the Goalkeepers (GKP) and Defenders (DEF) are very similarly priced with average between 4.0 - 4.5. The KDE plots for GKP and DEF are very narrow compared to other positions, means that they have the least variance of price. Meanwhile, prices for Forwards (FWD) are the most widely spread.
Now, let's see which Premier League team has the most FPL points from their players


Turns out that Southampton gives us the lowest total points from their players. This actually makes sense because they sit at the very bottom of the Premier League table up until the cut-off time. We can also see that the top 3 teams are almost identical with the real Premier League table.
Next, let's see who are our top points scorers individually


The list is dominated by Midfielders, with Salah and Palmer leading the table. Meanwhile, there are just a few of Goalkeepers and Defenders on the list.
In FPL, there is a metric called Influence, Creativity, and Threat (ICT) index, which shows how much a certain player influence the game, which also usually translates to FPL points. Let's create a scatter plot to map the ICT index and FPL points, to show if this really is the case.


Looks like there is a strong positive correlation between ICT Index and Total Points, where players like Salah, Palmer, Haaland, Mbeumo, and Saka who have great ICT Index also returns a lot of FPL points
Next up, let's create a correlation heatmap between all of our numerical variables


Now let's focus only on the main variable that we are trying to analyze, which is 'total_points'


Let's remove variables that have weak correlation with 'total_points' (-0.50 < correlation < 0.50)
Now we have narrowed down our numerical variables from 64 to 47.
Next, we will combine the list with the categorical variables.



To be able to do Regression Analysis, we will do one-hot encoding on the categorical columns.


Now we are ready to do the regression analysis.
Regression Analysis
Regression analysis is a type of supervised learning to predict a value of a numerical variable. In this case, we want to predict the 'total_points' of a certain player based on their stats.
We will use 4 different regression models, which are:
* Linear Regression
* Decision Tree
* Random Forest
* Support Vector Machines
Before creating the model, we have to split our dataset into training and testing. Here we use 80% of the dataset as traning set and the rest 20% as testing set.

Linear Regression



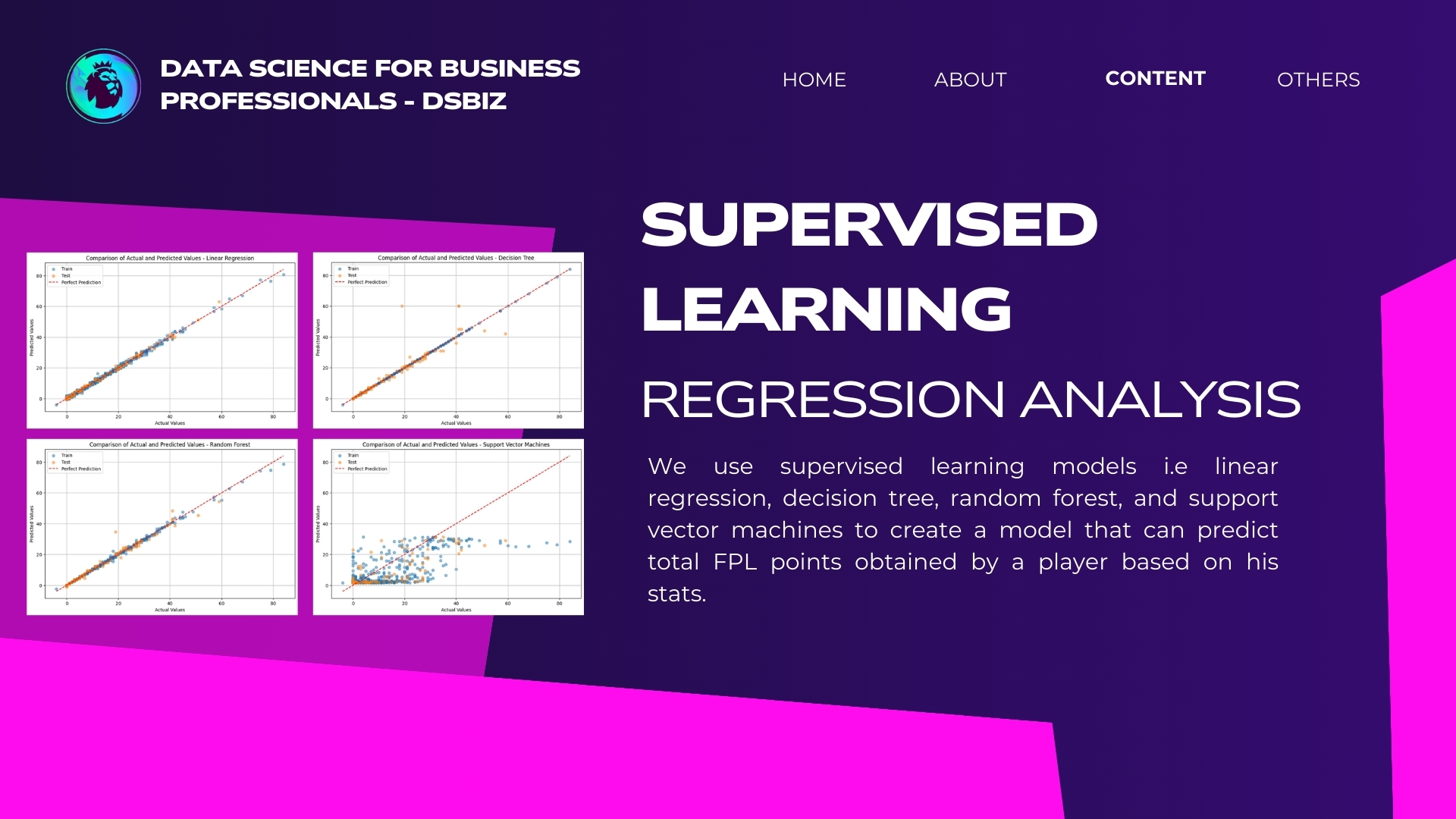
We can see that the Linear Regression model gives a very high R-squared which means the model can predict a player's 'total_points' very well. This also confirmed by the scatter plot above, where the predicted and actual values have a very high correlation.
Decision Tree



Turns out Decision Tree model also gives a good prediction, although the R-squared is not as high as Linear Regression model.
Random Forest



Random Forest model gives a better R-squared value than Decision Tree, but still not quite as good as Linear Regression.
Support Vector Machines



Looks like SVM is not the best model to use in this case, based on the R-squared value and the comparison plot.

Based on this comparison, we can conclude that **Linear Regression is the best model to predict 'total_points'**
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Persiapan Ujian Sertifikasi Internasional DSBIZ - AIBIZ



