
EDA Sports Car Price Dataset
I Made Oka Mahendra Putra



Summary
Exploratory Data Analysis (EDA) adalah proses analisis data awal yang digunakan untuk memahami struktur, karakteristik, dan pola dalam data sebelum melakukan analisis lebih lanjut atau pemodelan. EDA melibatkan berbagai teknik statistik dan visualisasi untuk mengeksplorasi data, mengidentifikasi anomali, memeriksa asumsi, dan menemukan hubungan antara variabel.
Description
Pada portfolio ini menggunakan dataset Sports Car Price yang diperoleh melalui Kaggle (https://www.kaggle.com/datasets/rkiattisak/sports-car-prices-dataset). Dataset ini berisikan kumpulan data ini berisi informasi tentang harga berbagai mobil sport dari berbagai produsen. Kumpulan data tersebut mencakup Car Make, Car Model, Year, Engine Size, Horse Power, Torque, 0-60 MPH Time (seconds), Price. Dari dataset tersebut akan dilakukan pengujian atau Analisa pola/hubungan antara harga mobil sport dengan variable independent lainnya yang ada pada dataset.
Variable independent yang akan digunakan dari 7 variable adalah sebanyak 4 variable yaitu Engine Size, Horse Power, Torque, 0-60 MPH Time (seconds). Langkah-langkah pengujian hubungan antara variable dependent dengan independent melalui excel sebagai berikut:
- Cleansing missing value, lakukan pengecekan missing value yang akan mempengaruhi hasil pengujian ini. Cara untuk mengantisipasinya adalah dengan cara mengubah nilainya dengan menggunakan nilai mean atau median selain itu dapat juga dapat menghapus 1 baris row tetapi dengan catatan tidak dilakukan pada keseluruhan dataset melainkan hanya pada 1 variable saja.
- Normalisasi data, proses ini dilakukan untuk penyesuaian skala nilai-nilai dalam dataset sehingga variable-variable berada dalam rentang yang sama atau memiliki distribusi yang serupa. Normalisasi sangat penting dalam machine learning dan data analysis karena dapat membantu meningkatkan performa algoritma dengan memastikan bahwa setiap fitur memiliki skala yang sama, sehingga tidak ada fitur yang mendominasi yang lain karena skala yang berbeda. Dalam hal ini akan dilakukan normalisasi data dengan menggunakan Simple Feature Scalling yang dikhususkan pada numeric dan jika menemukan kategori berupa text dapat menggunakan Label Encoding.

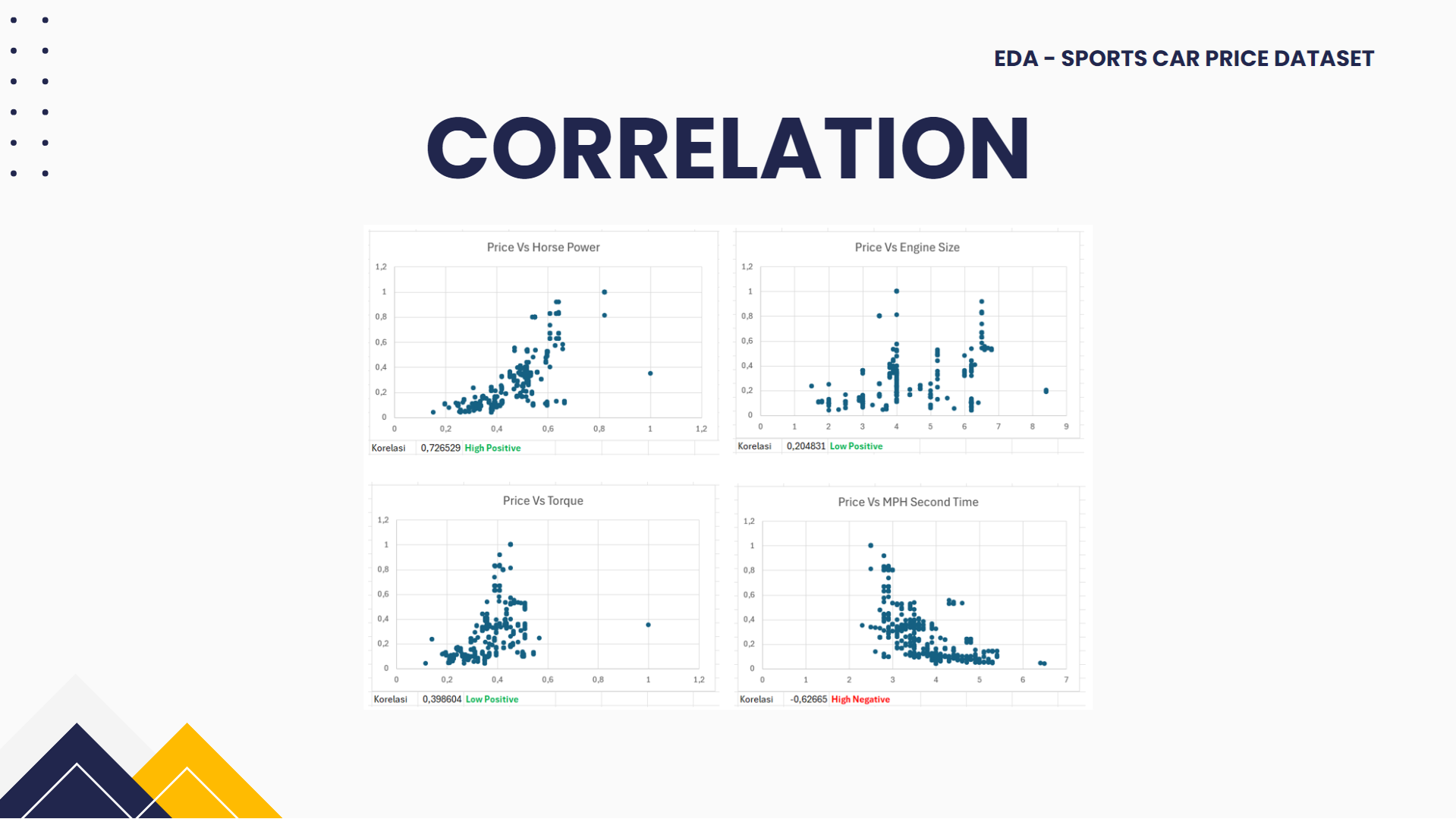
- Visualisasi distibusi data, untuk melihat hubungan antara 2 variable dapat menggunakan scatter plot. Dengan scatter plot, Anda dapat melihat pola, tren, atau hubungan yang mungkin ada antara dua variabel dalam dataset. Ini juga membantu dalam mengidentifikasi outlier, cluster, atau korelasi antara variable.




Dapat dilihat bahwa terdapat outlier pada keempat variable independent yang nantinya dapat mempengaruhi hasil analisa dan model secara signifikan sehingga untuk data outlier dapat dihapus dalam dataset.
- Pembuktian dengan menggunakan pearson correlation. Pearson correlation adalah ukuran statistik yang digunakan untuk menentukan kekuatan dan arah hubungan linear antara dua variabel numerik. Nilai Pearson correlation coefficient berkisar antara -1 hingga 1, dan menggambarkan sejauh mana dua variabel berhubungan secara linear. Dalam excel untuk mendapatkan nilai korelasi dapat menggunakan formula CORREL.
Dapat dilihat pada masing-masing gambar tersebut diperoleh nilai korelasi dari masing-masing variable yaitu Horse Power: 0.726529, Engine Size: 0.204831, MPH Second Time: -0.62665, Torque: 0.398604. Untuk korelasi secara positif yang paling tinggi berada pada variable Horse Power dimana harga dari mobil sport akan semakin tinggi jika Horse Powernya juga semakin tinggi, dan korelasi secara negative adalah MPH Second Time dimana harga dari mobil sport akan semakin turun jika MPH Second Time-nya semakin tinggi.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Persiapan Ujian Sertifikasi Internasional DSBIZ - AIBIZ

