
Exploratory Data Analysis In Marketing
Dinda Meimana



Summary
Pada project ini merupakan hasil dari proses belajar beberapa course bisa ai yang berkaitan dengan pengolahan data. Project ini akan menggunakan dataset yang diperoleh dari website kaggle.com untuk dilakukan Exploratory Data Analysis menggunakan tools google colabs dan dataset ini merupakan data marketing dari suatu perusahaan yang berisikan Customer profiles, Product preferences, Campaign successes/failures dan Channel performance. Dengan melakukan Exploratory Data Analysis menggunakan dataset ini akan diperoleh informasi yang bermanfaat dan insight- insight menarik.
Description
Project ini menggunakan data publik di bidang marketing suatu perusahaan yang diperoleh melalui website kaggle.com dan dataset ini terdiri dari beberapa variabel diantaranya yaitu :
- ID: Pengenal Unik Pelanggan
- Year_Birth: Tahun Lahir Pelanggan
- Education: ingkat pendidikan pelanggan
- Marital_Status: Status pernikahan pelanggan
- Income: Pendapatan rumah tangga tahunan pelanggan
- Kidhome: Jumlah anak dalam rumah tangga pelanggan
- Teenhome: Jumlah remaja dalam rumah tangga pelanggan
- Dt_Customer: Tanggal pendaftaran pelanggan dengan perusahaan
- Recency: Jumlah hari sejak pembelian terakhir pelanggan
- MntWines:Jumlah yang dihabiskan untuk wine dalam 2 tahun terakhir
- MntFruits: Jumlah yang dihabiskan untuk buah-buahan dalam 2 tahun terakhir
- MntMeatProducts: Jumlah yang dihabiskan untuk daging dalam 2 tahun terakhir
- MntFishProducts: Jumlah yang dihabiskan untuk membeli ikan dalam 2 tahun terakhir
- MntSweetProducts: Jumlah yang dihabiskan untuk permen dalam 2 tahun terakhir
- MntGoldProds: Jumlah yang dihabiskan untuk emas dalam 2 tahun terakhir
- NumDealsPurchases: Jumlah pembelian yang dilakukan dengan diskon
- NumWebPurchases:Jumlah pembelian yang dilakukan melalui situs web perusahaan
- NumCatalogPurchases: Jumlah pembelian yang dilakukan menggunakan katalog
- NumStorePurchases: Jumlah pembelian yang dilakukan langsung di toko
- NumWebVisitsMonth: Jumlah kunjungan ke situs web perusahaan dalam sebulan terakhir
- AcceptedCmp1: 1 jika pelanggan menerima penawaran di kampanye pertama, 0 sebaliknya (Variabel target)
- AcceptedCmp2: 1 jika pelanggan menerima penawaran di kampanye ke-2, 0 sebaliknya (Variabel target)
- AcceptedCmp3: 1 jika pelanggan menerima penawaran di kampanye ke-3, 0 sebaliknya (Variabel target)
- AcceptedCmp4: 1 jika pelanggan menerima penawaran di kampanye ke-4, 0 sebaliknya (Variabel target)
- AcceptedCmp5: 1 jika pelanggan menerima penawaran dalam kampanye ke-5, 0 sebaliknya (Variabel target)
- Response: 1 jika pelanggan menerima penawaran di kampanye terakhir, 0 sebaliknya (Variabel target)
- Complain: 1 jika pelanggan mengeluh dalam 2 tahun terakhir, 0 sebaliknya
- Country: Lokasi pelanggan
Dataset yang diperoleh kemudian dibaca menggunakan google colab dan menggali informasi terkait jumlah data yang terduplikat, missing value dan jenis-jenis tipe data.


column_name "Income" memiliki spasi sebelum namanya yang mungkin akan menimbulkan masalah dalam analisis lebih lanjut. ada sedikit masalah dengan tipe data di 2 kolom. Kita perlu mengubah tipe data kolom "income" menjadi int64 agar dapat digunakan untuk perhitungan lebih lanjut, dan mengubah tipe data "Dt_Customer" menjadi datetime. dataset ini memiliki data 2240 Pelanggan unik dan Tidak ada ID pelanggan yang terulang dalam dataset. Namun untuk melakukan analisis kolom id akan dihapus karena tidak diperlukan.

berdasarkan data diatas dataset ini hanya memiliki 24 nilai yang hilang di kolom "income". Jadi, pertama-tama periksa kemiringan kolom. Jika data simetris, maka menggunakan mean untuk menghitung nilai yang hilang, jika tidak, akan menggunakan median. Untuk memeriksa skewness, digunakan plot boxplot dan histogram.

berdasarkan grafik diatas dapat dilihat bahwa distribusinya miring dengan benar. Ini memiliki banyak outlier ke kanan dan karenanya, mean tidak akan menjadi metode imputasi yang baik karena mean sensitif terhadap outlier.












berdasarkan grafik boxplot diatas Tidak perlu menghapus sebanyak yang dapat ditingkatkan ke level apa pun, namun untuk variabel year_birth harus menghapus data yang kurang dari 1900 karena tidak mungkin pelanggan memiliki tahun lahir kurang dari 1900.

Dalam dataset memiliki beragam Pelanggan di toko yang berisi Orang-orang dengan pendapatan setinggi 700 ribu pendapatan tahunan dan beberapa pelanggan dengan pendapatan tahunan kurang dari 100 ribu juga.
Namun, mayoritas pelanggan dengan pendapatan tahunan rendah dan hanya ada beberapa yang memiliki pendapatan lebih dari $100k. Ini berarti bahwa toko tersebut melayani sebagian besar pelanggan kelompok berpenghasilan rendah dan tidak melayani pelanggan kaya/mewah.
Jadi, akan dihapus outlier ini jika tidak maka akan menimbulkan masalah dalam analisis lebih lanjut. untuk itu digunakan teknik transformasi log.

berdasarkan grafik heatmap diatas diperoleh inofrmasi bahwa income/pendapatan memiliki korelasi positif yang tinggi dengan kolom "NumPurchases" dan kolom "Mnt". Ini mewakili klaster Pendapatan Tinggi dan menunjukkan orang-orang dengan pendapatan tinggi menghabiskan lebih banyak dan lebih sering membeli. Pendapatan memiliki korelasi negatif yang tinggi dengan "NumWebVisitsMonth" yang menunjukkan bahwa pelanggan dengan pendapatan tinggi tidak terlalu sering mengunjungi web.
"Amount Spent on Wines" memiliki korelasi positif yang tinggi dengan "NumCatalogPurchases" dan "NumStorePurchases", dan demikian pula, "Amount Spent on Meat products" memiliki korelasi positif yang sangat tinggi dengan "NumCatalogPurchases", menunjukkan bahwa Orang umumnya membeli produk Anggur dan Daging melalui Katalog.
"NumWebVisitsMonth" tidak menunjukkan korelasi dengan "NumWebPurchases". Sebaliknya, ini menunjukkan korelasi ringan dengan "NumDealsPurchases" yang menunjukkan bahwa penawaran adalah cara yang efektif untuk merangsang pembelian di situs web.

berdasarkan grafik diatas, Siklus kedua sesuai dengan studi tingkat pascasarjana atau master. Siklus ketiga sesuai dengan studi tingkat doktor atau PhD. Jenis sistem pendidikan ini biasanya diterima di negara-negara Eropa. Jadi insight yang dapat diperoleh yaitu pelanggan terbanyak telah menyelesaikan Wisuda mereka, dan hanya sedikit dari mereka yang melanjutkan studi setelah Wisuda.

Ini adalah barplot dengan sumbu x sebagai "education" dan sumbu y sebagai "income". Pelanggan dengan gelar PhD memiliki pendapatan rata-rata tertinggi dibandingkan dengan pelanggan lain.

Jumlah pelanggan yang sudah menikah adalah yang paling banyak untuk toko pada dataset. Dengan bantuan klien, dapat memiliki pemahaman yang lebih baik tentang data dan membersihkan jenis data ini. Seperti dapat menggabungkan kategori YOLO, Alone dan Single bersama-sama.

Berdasarkan grafik histogram diatas diperoleh informasi
- Spanyol/spain memiliki pelanggan terbanyak.
- Rata-rata tahun kelahiran untuk semua negara kira-kira sama.
- Pendapatan rata-rata pelanggan dari semua negara kira-kira sama.

berdasarkan grafik diatas jelas menunjukkan Jumlah Maksimum yang dihabiskan untuk wines, jadi ini adalah produk paling favorit dari semua pelanggan. Produk favorit selanjutnya adalah Produk Daging

berdasarkan grafik diatas menunjukkan bahwa pembelian terbanyak telah dilakukan melalui kunjungan toko dan selanjutnya melalui website.

Sangat sedikit keluhan yang dibuat oleh pelanggan. Mayoritas orang tidak memiliki keluhan. Jadi perusahaan dapat fokus pada orang-orang yang telah mengajukan keluhan dan menyelesaikannya untuk tidak memiliki catatan keluhan.

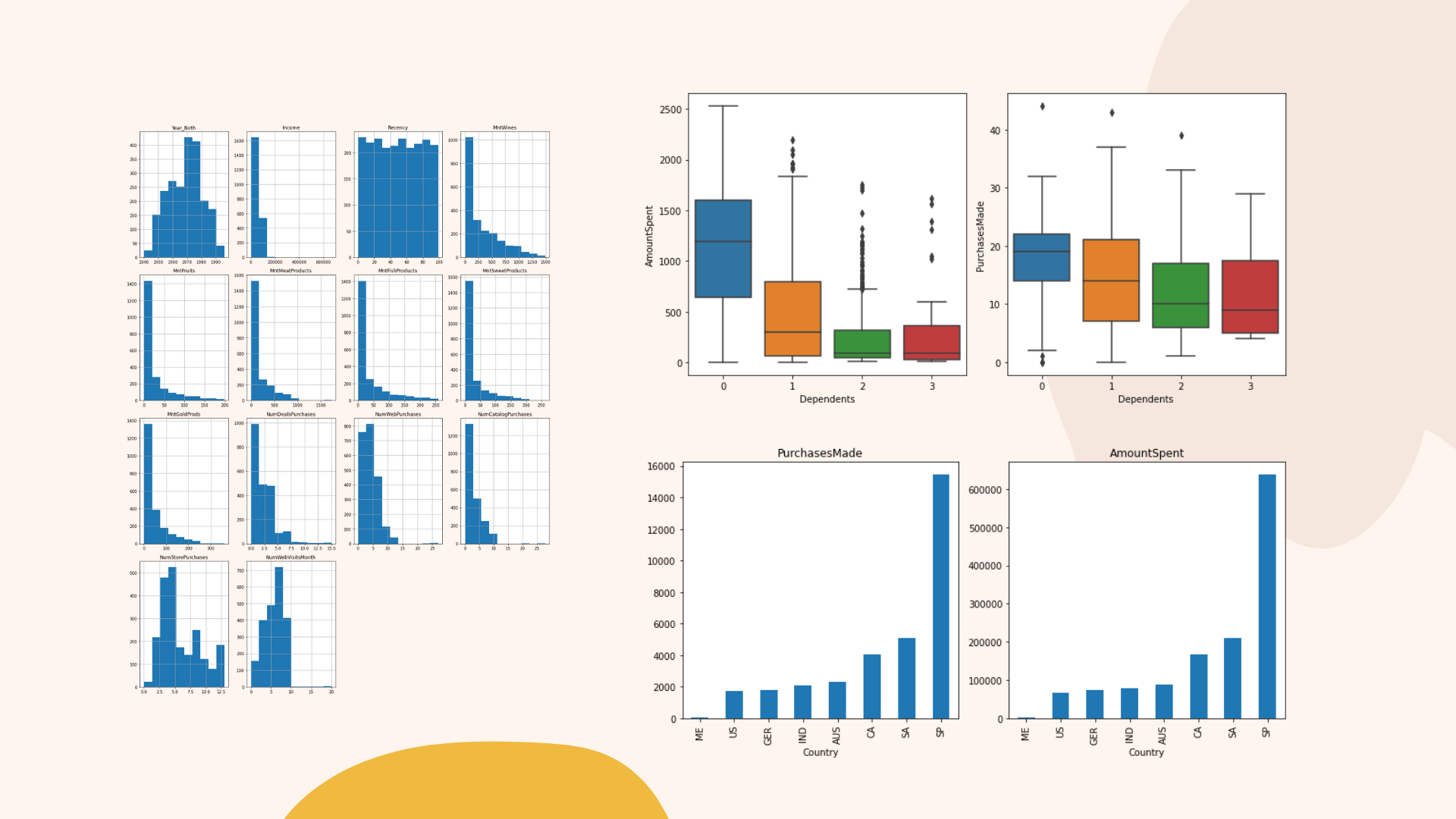
berdasarkan grafik boxplot diatas menunjukkan bahwa pelanggan dengan lebih banyak tanggungan menghabiskan lebih sedikit, dibandingkan dengan pelanggan dengan lebih sedikit tanggungan. Juga, pelanggan dengan lebih banyak tanggungan melakukan lebih sedikit pembelian di toko.

Seperti yang kita lihat dari data diaats, jumlah pembelian di toko sangat berkorelasi dengan jumlah wine yang dibeli. Jadi kita dapat menyimpulkan bahwa mungkin wine dibeli lebih banyak dari toko
NumStorePurchases berkurang dengan meningkatnya NumWebVisitsMonth. Juga, NumStorePurchases meningkat dengan mAmount yang dihabiskan untuk wine dan NumCatalogPurchases.

berdasarkan visualisasi data diatas bahwa Spanyol/spain adalah yang terbaik dalam hal Total Jumlah yang Dibelanjakan dan Total Pembelian yang dilakukan di toko.
Kesimpulan
- Kunjungan toko lebih banyak mendatangkan pelanggan dibanding kunjungan website.
- Kampanye cmp4 memberikan kinerja terbaik dan kampanye cmp2 memberikan kinerja terburuk.
- Pelanggan terbanyak yang membeli berasal dari kelompok warga lanjut usia
- Pelanggan terbanyak berasal dari negara spanyol Negara spanyol namun jika hanya fokus pada pemasaran di wilayah Spanyol tidak dapat mendatangkan pelanggan.
- Produk wines paling banyak terjual di semua kampanye pemasaran yang telah dilakukan perusahaan
- Orang-orang yang tanpa tanggungan merupakan pelanggan yang paling banyak membeli produk di perusahaan tersebut.
Informasi lebih lengkap :
https://colab.research.google.com/drive/1BIx62H8MbzthSqOL4Z17aw9pbYjCIOL4?usp=sharing
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Python Data Science untuk Pemula
