
Speech Sentiment Analysis using SVM Classifier
Riko Okananta
Summary
Speech Sentiment Analysis Using SVM adalah metode yang menggunakan Support Vector Machine (SVM) untuk mengklasifikasikan sentimen dalam data suara tanpa melalui konversi ke teks. Proses ini melibatkan ekstraksi langsung fitur numerik dari sinyal audio, seperti intonasi, pitch, tempo, dan energi. Fitur-fitur prosodik ini kemudian digunakan oleh model SVM untuk mendeteksi dan mengklasifikasikan sentimen sebagai positif, negatif, atau netral, memungkinkan analisis sentimen yang akurat berdasarkan karakteristik audio saja.
Description
SPEECH SENTIMENT ANALYSIS MENGGUNKAN SUPPORT VECTOR MACHINE CLASSIFIER
Deskripsi Proyek
Dalam kasus kali ini saya mencoba mengolah data audio yang termasuk kategori speech recognition untuk mengklasifikasikan sentiment dari sebuah ucapan seseorang, apakah dalam kategori negatif, positif, atau netral. Sedangkan untuk permodelan klasifikasinya saya menggunakan algoritma machine learning yang cukup populer baik untuk klasifikasi binary class ataupun multiclass, yaitu Support Vector Machine Classifier (SVM Classifier) dan menggunakan metode Gridsearch untuk Hyperparameter tuningnya. Kemudian untuk tahap ekstraksi fitur dari data file Audio menjadi data numerik, saya menggunakan empat metode yang saya kombinasikan yaitu :
- RMSE (Root Mean Squared Energy)
- Mel-Frequency Cepstral Coefficients (MFCCS)
- Spectral Centroid
- Zero Crossing Rate
Tidak hanya itu, dari hasil ekstraksi setiap metode akan di ukur menggunakan beberapa ukuran statistik Central dan ukuran persebaran untuk mendapatkan karakteristik dari data dengan lebih baik, diantaranya sebagai berikut :
- Mean (Rata - Rata)
- Median (Nilai Tengah)
- Standar Deviasi
- Range
- Nilai Minimum
- Nilai Maksimum
Dengan demikian setiap data akan direpresentasikan dalam 24 fitur berbeda. Sejauh penelitian tentang Speech Sentiment analysis pada project ini, menghasilkan performa yang sudah cukup bisa diandalkan dengan angka 84%.
Tools Proyek
- Bahasa Pemrograman Python
- Google Colaboratory
- Pandas, Numpy, Matplotlib, Seaborn
- Librosa, IPython
- Scikit Learn
Link Google Colab : https://colab.research.google.com/drive/1p2nNlBgeMZ6HpZgOfmu2uCtXglW8ajP9#scrollTo=O_TnyA4S_pFy
Dataset Proyek
Dalam Proyek Speech Sentiment Analysis menggunakan SVM ini, saya menggunakan dataset publik yang tersedia di website Kaggle, dan dapat diakses dengan link berikut ini : https://www.kaggle.com/datasets/imsparsh/audio-speech-sentiment
Dalam dataset tersebut terdapat beberapa file dan folder, sebagai berikut :

Dimana terlihat yang pertama ada folder TEST yang berisi file audio berfromat .wav sejumlah 110 file audio, kemudian Folder TRAIN berisi file audio berformat .wav juga sejumlah 250 file. Folder sample_data beridi tentang metadata dan readme dari dataset tersebut, ada juga test_image dan train_images yang berisi gambar visualisasi dari spectrogram setiap file audio dari train dan test. Kemdian yang terakhir ada TRAIN.csv yang berisi nama file audio untuk training beserta labelnya dalam bentuk file CSV.
Langkah - Langkah Penyelesaian Proyek
Download Dataset dari website Kaggle dan Unzip file.
Dalam kasus ini, saya mendownload dataset dengan menggunakan Kaggle API Command, sehingga dataset tidak perlu lewat komputer dan penyimpanan lokal, artinya langsung ke lembar kerja saya di Google Colab. Dengan begini akan sangat efektif jika data yang digunakan berukuran cukup besar dan sumber daya lokal terbatas. Berikut dokumentasi praktik saya.

Gambar 2 : Download and Unzip Dataset
Dengan perintah tersebut pada gambar saya dapat mengimport semua file dan folder yang ada dalam dataset tersebut dan menggunakannya untuk proses training atau kebutuhan lainnya.
Import Library dan modul
Modul dan library merupakan sebuah sumber daya yang sangat penting untuk membantu proses development apapun yang berkaitan dengan bahasa pemrograman. Di python sendiri ada banyak libraryi yang tersedia untuk berbagai development machine learning, deep learning, Data Science, Back End, dll. Kali ini saya akan mengimport beberapa library di python yang dapat membantu saya mengolah data speech/audio dan pembangunan model machine learning, berikut dokumentasi terkait library yang saya import.

Gambar 3 : Importing Necessary Library
Load Audio Datset

Gambar 4 : Load Datset with Librosa and IPython
Dalam tahap ini saya melakukan Load Dataset dengan library Librosa dengan fungsi load(). Variabel audio_data adalah kumpulan list nama file .wav yang ada di directory /content/TRAIN, kemudian load dataset menghasilkan output `y` merupakan representasi numerik dari file audio dalam bentuk numpy array, dan `sr` merupakan sample rate. Dengan library IPython juga saya dapat mendengarkan audio secara jelas di dalam lingkungan Google Colab.


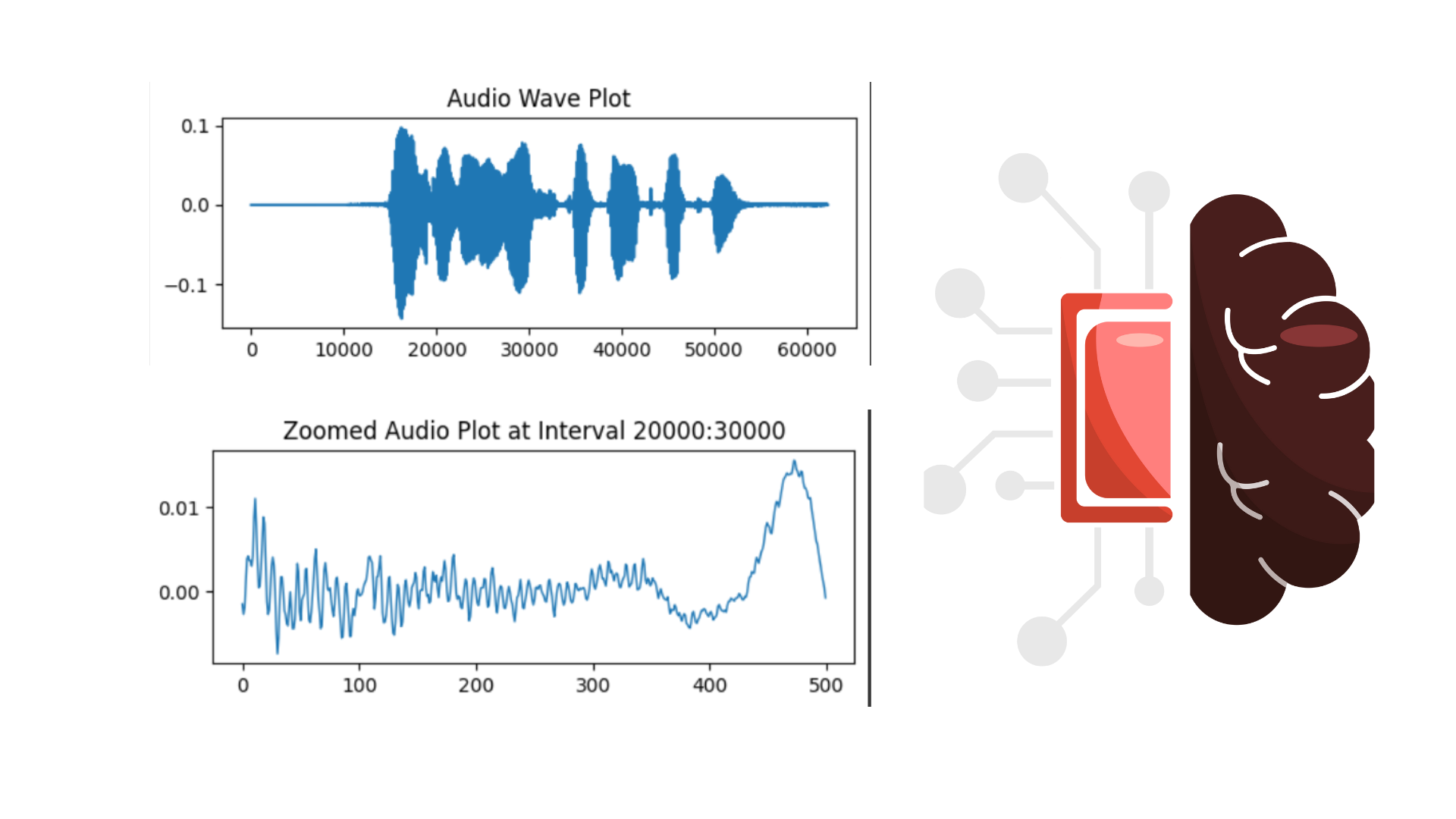
Saya juga merepresentasikan atau melakukan visualisasi sederhana dengan waveplot terhadap output y yang dihasilkan dari proses load dataset dengan librosa tadi, interval asli berada diantara 0 - 60000 dan saya juga mencoba melakukan trimed data dan menampilkan lebih detail pada interval tertentu, dalam hal ini saya menampilkan interval 20000 - 20500.
Feature Extraction step
Feature Extraction menjadi langkah yang sangat penting untuk tahap penelitian proyek ini, dikarenakan data yang digunakan bukan data numerik langsung yakni data suara (audio), sedangkan Machine Learning hanya dapat memproses data dalam bentuk data numerik, maka kita perlu melakukan ekstraksi fitur dari data audio ke bentuk numerik yang dapat diolah dan dikenali oleh Machine Learning. Metode ekstraksi fitur dalam data audio pun bermacam macam tergantung tipe data suara apa dan tujuan analisisnya seperti apa.
Pada proyek ini, saya menggunakan empat metode fitur extraction pada data audio untuk mengambil informasi dari data audio dan di representasikan dalam vektor numerik, yaitu metode RMS Energy, Mel - Frequency Cepstral Coefficients (MFCCS), Spectral Sentroid, dan Zero Crossing Rate. Seperti penjelasan pada deskripsi diatas, setiap hasil ekstraksi dari satu fitur untuk setiap data, akan dihitung metrics statistic untuk mean, median, standar deviasi, range, nilai min, dan nilai max sehingga dalam satu data audio akan direpresentasikan oleh 26 fitur berbeda. Berikut proses ekstraksi fitur dari setiap metode.
RMSE (Root Mean Suquared Energy) merupakan salah satu metode ekstraksi fitur yang mengukur kekuatan frekuensi suara dan intensitas gelombang suara yang dihasilkan. hal ini membuat metode ini cocok untuk analisis suara yang mempertimbangkan aspek emosi dan sentiment dari ucapan tersebut. Berikut implementasi saya dalam Google colab Python.

Gambar 5 : Feature extraction using RMS Energy
MFCCs (Mel - Frequency Cepstral Coefficients) MFCC (Mel-Frequency Cepstral Coefficients) adalah serangkaian koefisien yang mewakili spektrum amplitudo suara dalam skala Mel, yang dirancang untuk mencerminkan cara manusia merasakan suara. Metode ekstraksi fitur ini sangat cocok untuk data ucapan dan sangat umum digunakan untuk ekstraksi fitur speech pada spech processing. Berikut Implementasi yang saya terapkan di proyek saya.

Gambar 6 : Feature Extraction With MFCCs
Spectral Centroid adalah salah satu metode ekstraksi fitur dalam analisis audio yang mengukur "pusat massa" dari spektrum frekuensi. Secara intuitif, spectral centroid menunjukkan di mana sebagian besar energi spektral dari sinyal audio terkonsentrasi, memberikan gambaran tentang "kecerahan" atau "kejelasan" dari suara tersebut. Berikut merupakan implementasi dalam proyek Google Colab saya.

Gambar 7 : Feature Extraction using Spectral Centroid
Zero Crossing Rate (ZCR) adalah metode ekstraksi fitur dalam analisis sinyal audio yang menghitung seberapa sering sinyal audio melintasi sumbu nol dalam suatu interval waktu tertentu. Dengan kata lain, ZCR mengukur jumlah perubahan tanda pada sinyal audio dalam suatu periode waktu. Berikut merupakan implementasi dalam proyek Google Colab saya.

Gambar 8 : Feature Extraction using Zero Crossing Rate (ZCR)
Ekstraksi Fitur dari semua metode dan berbagai representasi ukuran statistik telah selesai, dan sekarang kita punya 24 variabel yang bertipe data list berisi hasil ekstraksi fitur yang telah kita lakukan sebelumnya. Selanjutnya dari 24 variabel list hasil ekstraksi fitur tersebut akan digabungkan bersamaan juga dengan kolom target yang ada di file TRAIN.csv, kolom nama file audio, dan class/target yang telah di convert (label encoding) menjadi data angka integer (angka diskrit) dalam satu dataframe utama dan berikut ini main dataframe yang telah kita buat.

Gambar 9 : Display Main Dataframe
Nah, sekarang dataset utama kita sudah jadi, dan sudah siap untuk masuk ke tahap Exploratory Data Analysis (EDA) agar dapat memperoleh pemahaman akan karakteristik data denga lebih dalam lagi.
Exploratory Data Analysis (EDA)
Exploratory Data Analysis merupakan sebuah tahapan dalam Data science process yang bertujuan untuk menggali lebih dalam tentang karakteristik, distribusi, pola dan trend, ataupun hubungan antar variabel agar memperoleh informasi yang lengkap dan menyeluruh tentang keadaan data tersebut. Nantinya hasil dari tahap EDA ini akan menentukan langkah selanjutnya seperti apa yang akan diambil dalam tahapan preprocessing dan permodelan. jika tidak dilakukan tahap EDA ini maka akan memperbesar kemungkinan langkah preprocessing dan permodelan tidak berdasar dan membuat langkah menjadi tidak tepat sasaran. Berikut ini saya melakukan beberapa teknik dalam EDA untuk menggali informasi pada main dataset yang sudah kita buat sebelumnya.
Menampilkan Informasi Dasar Dataset

Gambar 10 : Display Basic Information of Dataset
Untuk hal - hal yang termuat dalam informasi dasar ini diantaranya daftar nama kolom, jumlah entri data, jumlah kolom, tipe data, jumlah data null, dan juga memory yang digunakan. Informasi ini sangat penting untuk wawasan tentang informasi struktural dari dataset, sehingga jika ada yang kurang tepat dengan tujuan analisis kita maka kita perlu melakukan transformasi struktural pada tahap preprocessing data nanti. Pada gambar terlihat semuanya sudah ada sebagaimana yang kita inginkan, maka dalam data preprocessing tidak perlu dilakukan transformasi strruktural.
Visualisasi Box-Plot
Visualisasi Boxplot diperlukan untuk memperoleh informasi terkait sebaran data terhadap pembagian wilayah quartil, selain itu juga digunakan untuk mengetahui secara singkat apakah data tersebut memiliki outlier atau tidak. Outlier merupakan salah satu masalah yang sangat penting untuk diatasi sebelum masuk kepada langkah permodelan, karena data yang keluar dari pola distribusi mayoritas data akan membiaskan hasil prediksi dari model, terlebih lagi model machine learning yang memiliki dasar perhitungan dari jarak, seperti KNN dan SVM. Berikut tampilan Sample Boxplot pada dataset untuk setiap fiturnya.

Gambar 11 : Script display Boxplot for Any Features
Dari kode script diatas, saya dapat mendapatkan beberapa sample hasil visualisasi boxplot untuk beberapa fitur seperti berikut.




Terlihat pada gambar beberapa boxplot diatas, bahwa terdapat banyak outlier (lingkaran diluar batas) pada beberapa fitur dari dataset utama kita, jadi langkah untuk mengatsi hal ini sebenarnya ada penghapusan, dan normalisasi data. Jika kita pilih untuk penghapusan data outlier, maka kita akan kehilangan banyak sekali informasi, karena outlier disitu tidak sedikit, jadi Normalisasi data menjadi solusi untuk dilakukan agar dapat mengatasi data outlier ini.
Correlation Analysis dengan Heatmap
Dalam tahap analisis korelasi ini, tujuannya adalah untuk mencari ketergantungan antara satu fitur dengan fitur - fitur yang lainnya dan kolom target/class. Analisis korelsi menggunakan angka indeks yang memiliki rentang antara -1 s/d 1 untuk menggambarkan ketergantungan tersebut, semakin indeks mendekati angka 0 maka semakin tidak ada hubungan/korelasi antara kedua fitur yang diamati, sedangkan jika nilai indeks mendekati nilai -1 maka hubungan/ketergantungannya semakin kuat namun berbanding terbalik, lalu jika nilai indeks semakin mendekati 1 maka menunjukkan bahwa hubungan antara keduanya kuat dan sebanding. Agar lebih mudah kita akan sajikan hasil analisis korelasi dari semua kolom yang ada di dataset (yang termasuk kolom data numerik) dalam visualisasi Heatmap menggunakan library Matplotlib dan Seaborn. Berikut implementasinya dalam proyek saya.

Gambar 12 : Script for Heatmap Visualization
Jika script python tersebut dijalankan maka akan memerikan hasil visualisasi seperti yang tertampil pada gambar berikut ini.

Gambar 13 : Corelation Analysis with Heatmap
Pada gambar tersebut diatas, kita dapat melihat bahwa hubungan antara class dan semua fitur fiturnya cukup kecil, padahal seharusnya semua fitur harus memberikan kontribusi yang maksimal kepada class/target jika itu merupakan kombinasi fitur yang baik. Maka dengan ini banyak sekali sampah - sampah (data yang tidak mengandung informasi) yang ada pada dataset kita sekarang ini, jika dibiarkan maka akan membuat performa model menjadi kurang maksimal, karena data yang masuk banyak yang mengandung sampah. Untuk menangani hal ini kita perlu melakukan Fature Extraction dan sekaligus reduksi dimensi dengan PCA. Dengan ini, nantinya dataset akan menjadi lebih bersih dan padat/banyak akan informasi
Cek Keseimbangan dari Proporsi Class/target
Imbalance Dataset merupakan istilah yang digunakan untuk menggambarkan dimana proporsi antara label dalam kolom class/target tidak seimbang secara signifikan. satu label jumlahnya dapat lebih banyak 2-3 kali lipat dari jumlah label lainnya, mengindikasikan terjadinya Imbalance dataset. Jika hal ini dibiarkan, maka akan membuat model machine learning yang dihasilkan akan condong kepada label yang memiliki jumlah proporsi yang lebih besar, sehinga membuat hasil prediksi menjadi bias dan tidak realistis. Untuk menangani Imbalance Dataset ini, ada beberapa cara di antaranya melakukan resampling, dan memberikan pembobotan yang lebih besar kepada label yang memiliki proporsi kecil. Berikut ini implementasi saya dalam proyek ini di google colab :

Gambar 14 : Script for Visualization Countplot
Berikut merupakan hasil dari tampilan Visusalisasi Countplot pada kolom class.

Gambar 14 : Visualization Countplot for Cecking Imbalance Dataset
Dari hasil visualisasi tersebut terlihat bahwa proporsi antara label positive, neutral, dan negative cukup seimbang, jadi kita tidak perlu melakukan langkah untuk mengatsi imbalance dataset.
Data Preprocessing
Data preprocessing adalah tahap lanjutan dari EDA, untuk menindak lanjuti berdasarkan kondisi data yang telah dijelaskan di tahap EDA sebelumnya. Berikut ini merupakan tahapan preprocessing yang saya lakukan pada proyek ini.
Normalization/scaling

Feature Extraction and Dimensionality Reduction with PCA



Train Test Split

Machine Learning Modeling with SVM Classifier and GridsearchCV

Model Evaluation with Classification Report

Informasi Course Terkait
Kategori: Speech ProcessingCourse: Speech Classification Menggunakan Machine Learning



