
Exploratory Data Analysis (EDA) on Smartphone Data
Nugraha Varrel Kusuma
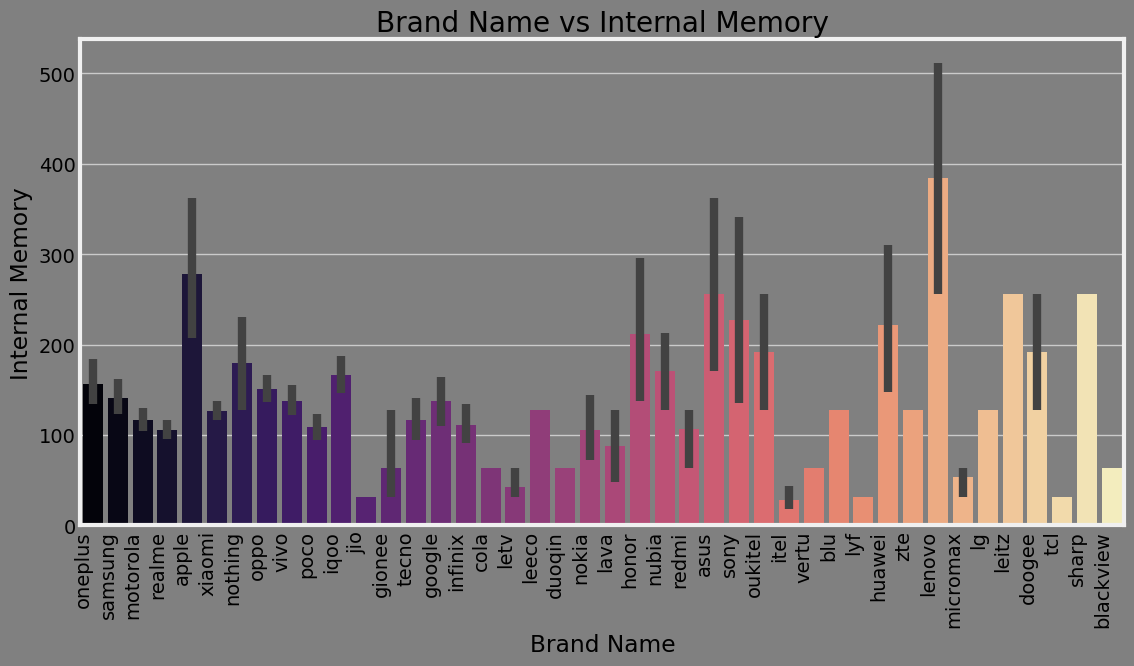
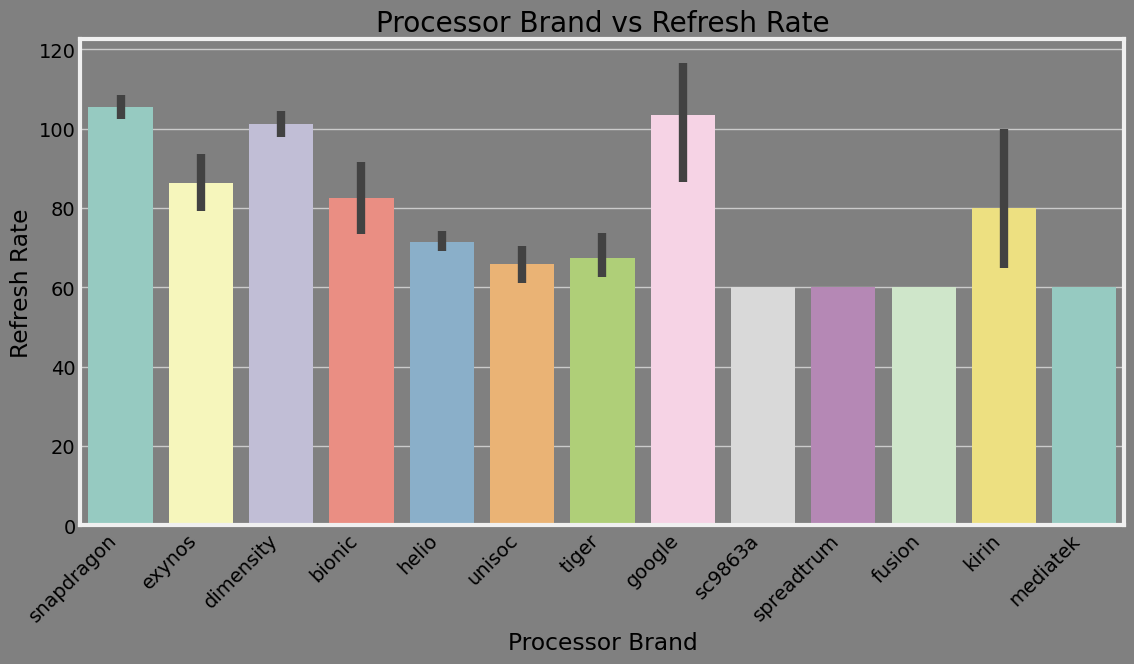
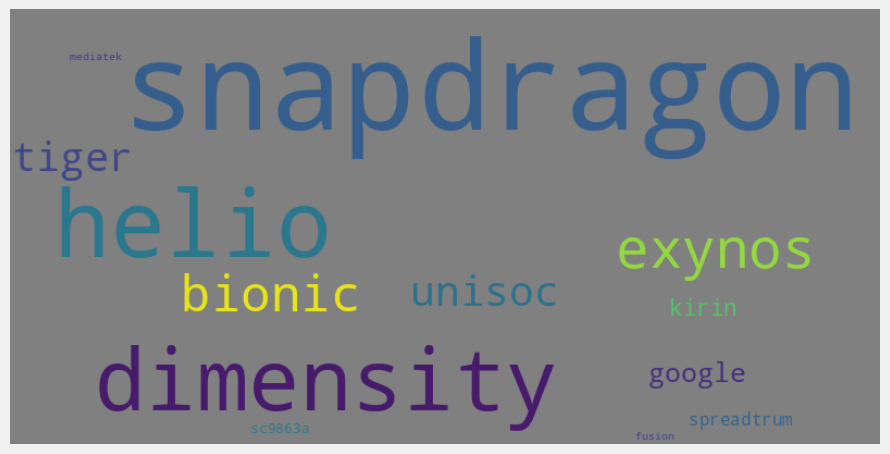

Summary
Analisis Data Eksploratif (EDA) adalah langkah penting dalam proses analisis data yang melibatkan merangkum dan memvisualisasikan data untuk mengekstrak wawasan yang berarti. Dalam proyek ini, kami melakukan EDA pada dataset smartphone untuk memahami pola dan hubungan yang mendasari antara berbagai fitur. Proses ini membantu dalam membuat keputusan yang terinformasi untuk analisis lebih lanjut dan pembuatan model.
link dataset : dataset smartphone
Description
Pengantar
Portofolio ini menyajikan analisis data eksploratif (EDA) pada sebuah dataset smartphone. Analisis ini mencakup memuat dan menyiapkan dataset, pra-pemrosesan data, serta analisis eksploratif yang mendetail untuk mengungkapkan wawasan mengenai berbagai fitur smartphone dan hubungan antar fitur tersebut.
Tujuan
Tujuan dari portfolio ini adalah untuk melakukan Analisis Data Eksploratif (EDA) pada dataset smartphone. EDA membantu kita memahami dataset dengan lebih baik, mengeksplorasi hubungan antar variabel, dan menemukan wawasan yang dapat digunakan untuk pengambilan keputusan yang lebih baik. Melalui kode ini, kami bertujuan untuk:
- Memuat dataset smartphone dan membersihkannya dari nilai yang hilang dan duplikat.
- Mengeksplorasi statistik deskriptif dari dataset untuk memahami karakteristik dasarnya.
- Melakukan analisis univariate dan bivariate untuk memahami distribusi variabel dan hubungan antar variabel.
- Menghasilkan visualisasi data yang informatif untuk menggambarkan pola-pola yang ditemukan.
- Membuat kesimpulan yang mendalam dari analisis data untuk memberikan wawasan yang berharga kepada pembaca.
Melalui langkah-langkah ini, kami berharap untuk mendapatkan pemahaman yang lebih baik tentang pasar smartphone dan faktor-faktor yang memengaruhinya.
Memuat dan Menyiapkan Dataset
a. Memuat Library dan Menyiapkan Lingkungan

Deskripsi
Blok kode ini mengimpor dan memasang library yang diperlukan untuk pemrosesan data, visualisasi, dan analisis statistik. Library seperti pandas, numpy, matplotlib, dan seaborn digunakan untuk berbagai operasi data dan visualisasi. WordCloud digunakan untuk membuat visualisasi awan kata. Selain itu, beberapa pengaturan awal dilakukan, seperti mengatur gaya plot dan menonaktifkan pesan peringatan untuk menjaga output tetap bersih.
b. Memuat Dataset

Deskripsi
Blok kode ini mencoba memuat dataset dari file CSV. Penggunaan try-except memungkinkan penanganan kesalahan yang lebih baik. Jika file tidak ditemukan atau terjadi kesalahan lainnya, pesan kesalahan akan dicetak. Ini memastikan bahwa jika ada masalah selama pemuatan data, pengguna mendapatkan informasi yang jelas mengenai apa yang salah.
Pra-pemrosesan Data
a. Pembersihan Data (Memeriksa Nama Kolom dan Nilai yang Hilang)

Deskripsi
Blok kode ini melakukan beberapa langkah penting dalam pra-pemrosesan data:
- Memeriksa nama kolom untuk memastikan semua kolom yang diharapkan ada.
- Mengidentifikasi nilai yang hilang dalam dataset untuk menentukan kolom mana yang perlu penanganan lebih lanjut.
- Menampilkan informasi umum tentang dataset, termasuk tipe data setiap kolom.
- Memeriksa entri duplikat dalam dataset, yang dapat mengindikasikan masalah dengan data yang diimpor.
b. Menangani Nilai yang Hilang (Mengidentifikasi Kolom dengan Nilai yang Hilang)

Deskripsi
Blok kode ini mengidentifikasi kolom-kolom yang memiliki nilai yang hilang dan menyediakan ringkasan statistik untuk kolom-kolom tersebut. Ini membantu memahami sejauh mana nilai yang hilang dan karakteristik dari kolom-kolom tersebut, yang penting untuk menentukan strategi penanganan yang tepat.
c. Mengisi Nilai yang Hilang

Deskripsi
Blok kode ini menangani nilai yang hilang dalam dataset dengan berbagai cara:
- Mengisi nilai yang hilang dalam kolom 'rating' dengan nilai rata-rata kolom tersebut.
- Mengisi nilai yang hilang dalam kolom 'fast_charging' dengan nilai acak dari set yang telah ditentukan.
- Mengisi nilai yang hilang dalam kolom lain dengan rata-rata masing-masing kolom.
- Menghapus baris yang masih memiliki nilai yang hilang setelah pengisian untuk memastikan dataset yang bersih dan lengkap.
c. Eksplorasi Data (Memeriksa Bentuk Dataset dan Statistik Ringkasan)

Deskripsi
Blok kode ini memeriksa bentuk dataset untuk memahami jumlah baris dan kolomnya. Selain itu, memberikan statistik deskriptif dari semua kolom numerik, seperti mean, median, dan standar deviasi, untuk memberikan gambaran umum tentang distribusi data.
Exploratory Data Analysis (EDA)
a. Analisis Univariat (Distribusi Variabel Numerik)

Deskripsi
Blok kode ini membuat histogram untuk setiap kolom numerik dalam dataset. Histogram ini dilengkapi dengan garis KDE (Kernel Density Estimate) untuk menunjukkan distribusi data. Setiap subplot diberi warna latar belakang abu-abu dan judul yang diformat dengan baik. Ini membantu untuk dengan cepat memahami distribusi dari setiap variabel numerik dalam dataset.
b. Word Cloud dari Merek Prosesor

Deskripsi
Blok kode ini membuat visualisasi word cloud dari merek-merek prosesor yang ada dalam dataset. Word cloud ini membantu untuk melihat frekuensi kemunculan masing-masing merek prosesor dengan cepat, dimana ukuran teks mencerminkan frekuensi tersebut.
c. Distribusi Sistem Operasi dan Ketersediaan Pengisian Cepat

Deskripsi
Blok kode ini memvisualisasikan distribusi sistem operasi dan ketersediaan pengisian cepat menggunakan count plot dan pie chart. Dengan dua jenis plot untuk masing-masing fitur, kita bisa melihat jumlah dan proporsi kategori dengan lebih jelas. Count plot menunjukkan jumlah dalam setiap kategori, sementara pie chart menunjukkan proporsi masing-masing kategori dalam bentuk persentase.
d. Analisis Bivariat (Nama Merek vs Rating)

Deskripsi
Blok kode ini mengurutkan dataframe berdasarkan rating dan membuat box plot untuk memvisualisasikan distribusi rating berdasarkan merek. Hal ini membantu untuk melihat bagaimana rating bervariasi di antara berbagai merek smartphone dan mengidentifikasi merek-merek dengan rating tertinggi atau terendah.
e. Analisis Multivariat (Korelasi Antar Variabel)

Deskripsi
Blok kode ini menghitung matriks korelasi untuk semua variabel numerik dalam dataset dan memvisualisasikannya menggunakan heatmap. Heatmap membantu untuk melihat hubungan antar variabel dan mengidentifikasi pasangan variabel yang memiliki korelasi tinggi, yang dapat memberikan wawasan tentang keterkaitan antar fitur dalam dataset.
Informasi Course Terkait
Kategori: Algoritma dan PemrogramanCourse: Python Data Science untuk Pemula



