
Analisis Data dan Eksplorasi Dataset Iris
Javanka Amedeo Cavendish


Summary
Tujuan dari analisis ini adalah untuk memahami karakteristik dataset Iris melalui langkah-langkah pra-pemrosesan data dan eksplorasi data (EDA). Analisis ini akan membantu kita dalam mengidentifikasi pola dan hubungan antar fitur yang ada dalam dataset.
Dataset Iris adalah salah satu dataset yang paling dikenal dalam komunitas pembelajaran mesin. Dataset ini terdiri dari 150 sampel bunga iris dengan empat fitur: sepal length, sepal width, petal length, dan petal width, serta satu kolom target yang menunjukkan spesies bunga (setosa, versicolor, dan virginica).
Description
Untuk memulai proyek analisis data dari awal hingga eksplorasi data (EDA), berikut adalah langkah-langkah yang perlu dilakukan. Proses ini akan mencakup pengunduhan dataset terbuka, pra-pemrosesan data, dan analisis data eksplorasi. Saya akan menggunakan Python dengan pustaka seperti pandas, numpy, matplotlib, dan seaborn.
1.Pilih dan Unduh Dataset
Saya mengunduh dataset di Keagle, berikut https://www.kaggle.com/datasets/himanshunakrani/iris-dataset. Setelah diunduh, kemudian buka google colab dan upload.
2. Impor Pustaka yang Dibutuhkan

3. Membaca File Excel

4. Melihat Sekilas Data

5. Pra-pemrosesan Data (Data Cleaning), meliputi
- mengidentifikasi dan mengatasi nilai hilang
- menghapus baris duplikat
- mengubah kolom ‘species’ menjadi numerik agar memudahkan menghitung korelasi.

6. Eksplorasi Data (Exploratory Data Analysis - EDA)
- Distribusi variabel : histogram untuk melihat distribusi dari setiap variabel numerik (sepal_length, sepal_width, petal_length, petal_width)

- Pair Plot: Plot pasangan untuk melihat hubungan antar variabel serta distribusi setiap variabel berdasarkan species.

- Heatmap Korelasi: Heatmap untuk melihat korelasi antar variabel numerik dalam dataset.

- Box Plot: Box plot untuk melihat distribusi dan outliers dari setiap variabel numerik berdasarkan species.

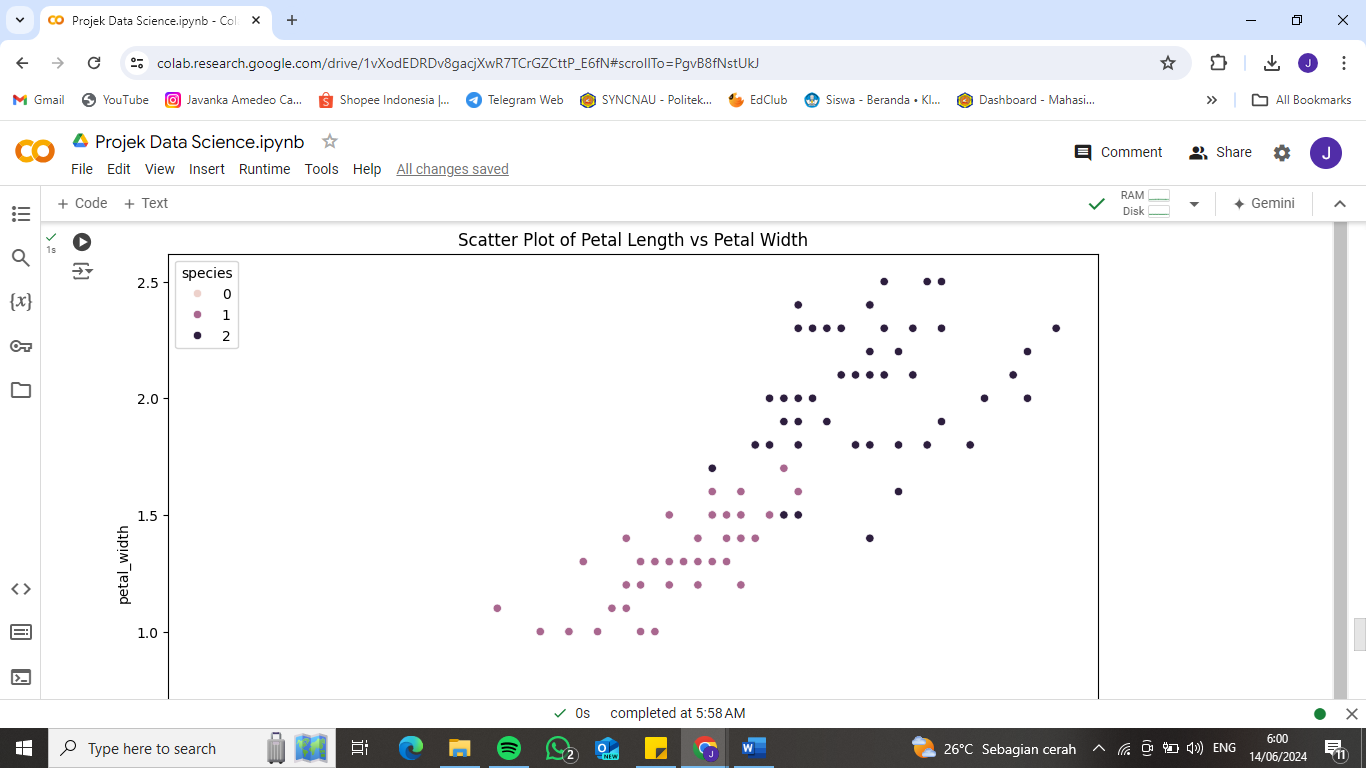
- Scatter Plot: Scatter plot untuk melihat hubungan antara sepal_length dan sepal_width, serta petal_length dan petal_width, dengan pewarnaan berdasarkan species.

Berikut saya sertakan link hasil pengerjaan di google colab https://colab.research.google.com/drive/1vXodEDRDv8gacjXwR7TCrGZCttP_E6fN#scrollTo=Xe6X7l5BvbyK
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Data Science SIB Batch 6
