
Analisis dan Pemodelan dengan Dataset Iris
Nugraha Varrel Kusuma

Summary
Selamat datang dalam perjalanan menarik melalui dunia data science dengan dataset Iris! Portofolio ini akan membawa Anda langkah demi langkah melalui berbagai teknik analisis data dan pembelajaran mesin, mengubah dataset bunga iris yang sederhana menjadi harta karun wawasan dan kekuatan prediktif. Sepanjang perjalanan, kita akan menjelajahi data, membersihkannya, memvisualisasikannya dalam grafik yang indah, mendeteksi anomali, dan bahkan membangun model untuk membuat prediksi dan klasifikasi. Mari kita mulai!
Description
Bab 1: Memuat dan Mempersiapkan Data
Memuat Dataset
Petualangan kita dimulai dengan memuat dataset Iris yang terkenal. Dataset ini berisi 150 sampel bunga iris, masing-masing dijelaskan oleh empat fitur: panjang sepal, lebar sepal, panjang petal, dan lebar petal. Tugas kita adalah mengklasifikasikan bunga-bunga ini ke dalam tiga spesies: Setosa, Versicolor, dan Virginica.

Bab 2: Pembersihan Data
Memeriksa Nilai yang Hilang
Sebelum kita memulai analisis, kita perlu memastikan data kita bersih. Mari kita periksa apakah ada nilai yang hilang yang mungkin mengganggu perjalanan kita.

Dengan senang hati, tidak ada nilai yang hilang, dan data kita siap untuk dieksplorasi!
Bab 3: Transformasi Data
Standardisasi Data
Untuk mempersiapkan data kita untuk analisis dan pemodelan, kita menstandarkan fitur-fiturnya. Langkah ini memastikan bahwa setiap fitur berkontribusi sama dalam analisis.
Pengurangan Dimensi dengan PCA
Kita menggunakan Principal Component Analysis (PCA) untuk mengurangi dimensi data kita. Teknik ini membantu kita memvisualisasikan data dalam dua dimensi sambil mempertahankan informasi terpenting.
Bab 4: Analisis Data Eksploratif
Statistik Deskriptif
Mari kita mulai eksplorasi kita dengan beberapa statistik deskriptif dasar untuk memahami distribusi dan karakteristik fitur-fitur kita.

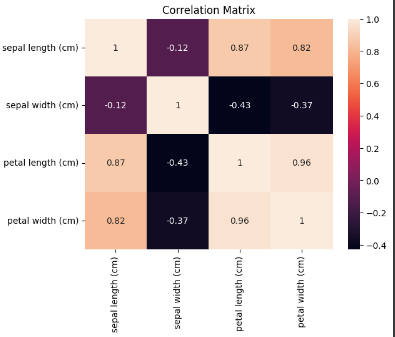
Matriks Korelasi
Selanjutnya, kita mengeksplorasi hubungan antara fitur-fitur menggunakan matriks korelasi. Heatmap ini akan mengungkapkan seberapa kuat setiap pasangan fitur saling berhubungan.

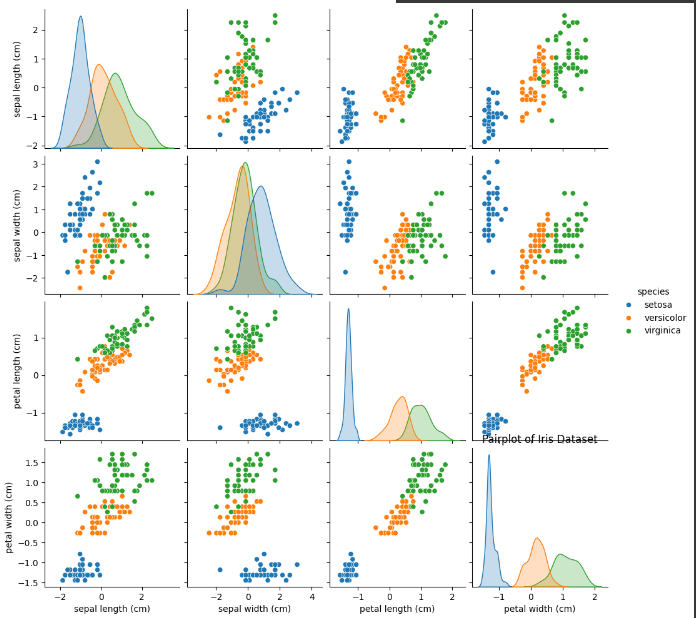
Visualisasi Pairplot
Untuk mendapatkan pandangan komprehensif tentang hubungan antara semua pasangan fitur, kita membuat pairplot. Visualisasi ini sangat informatif untuk memahami pemisahan spesies.

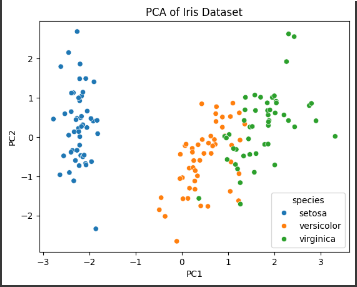
Plot Scatter PCA
Menggunakan hasil PCA kita, kita dapat membuat plot scatter untuk memvisualisasikan data dalam dua dimensi. Plot ini membantu kita melihat seberapa baik spesies dapat dipisahkan berdasarkan komponen utama.

Bab 5: Deteksi Anomali
Isolation Forest
Petualangan kita sekarang membawa kita ke bidang deteksi anomali yang menarik. Menggunakan algoritma Isolation Forest, kita mengidentifikasi anomali dalam data kita yang mungkin mewakili outlier atau observasi yang tidak biasa.

Bab 6: Membangun Model
Model Regresi
Kita memulai petualangan pemodelan kita dengan regresi. Menggunakan regresi linier, kita bertujuan untuk memprediksi panjang sepal bunga iris berdasarkan fitur lainnya.

Model Klasifikasi
Selanjutnya, kita membangun model klasifikasi menggunakan K-Nearest Neighbors (KNN). Tujuan kita adalah mengklasifikasikan bunga iris ke dalam spesies mereka berdasarkan dua fitur pertama.

Model Klasterisasi
Petualangan pemodelan terakhir kita melibatkan klasterisasi. Menggunakan algoritma K-Means, kita mengklasterkan bunga iris ke dalam tiga kelompok dan mengevaluasi kualitas klasterisasi menggunakan skor silhouette.

Kesimpulan
Perjalanan kita melalui dataset Iris telah dipenuhi dengan wawasan dan penemuan. Dari pembersihan dan transformasi data hingga analisis eksploratif dan teknik pemodelan lanjutan, kita telah menjelajahi spektrum penuh data science. Setiap langkah telah memberi kita pemahaman yang lebih dalam dan alat yang kuat untuk mengatasi masalah dunia nyata.
Portofolio ini tidak hanya menunjukkan keahlian teknis yang diperlukan untuk analisis data dan pembelajaran mesin, tetapi juga menampilkan keindahan dan keanggunan mendongeng dengan data. Terima kasih telah bergabung dalam perjalanan ini melalui dunia data science dengan dataset Iris!
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Data Science SIB Batch 6
