
Monitoring Kualitas Udara di Kota Ancona
Puteri Amelia Azli


Summary
Ancona adalah salah satu kota di Eropa yang terletak di wilayah Marche, Italia Tengah. Kota ini berfungsi sebagai pelabuhan laut dan ibu kota provinsi Ancona. Diportofolio ini, akan dijelaskan mengenai pre-processing data dan exploratory data analysis terhadap kualitas udara di kota Ancona dimulai dari pengenalan dataset hingga visualisasi dari dataset yang sudah dilakukan pre-processing dan Exploratory Data Analysis.
Description
Pre-processing data dan Exploratory Data Analysis (EDA) adalah dua langkah penting dalam alur kerja data science. Keduanya berfungsi untuk memahami dan menyiapkan data sebelum menerapkan model machine learning atau analisis lebih lanjut.
Pre-processing Data
Pre-processing data adalah tahap di mana data mentah disiapkan untuk analisis lebih lanjut. Tahap ini melibatkan berbagai teknik dan langkah untuk membersihkan dan mengubah data sehingga bisa digunakan dalam algoritma machine learning atau analisis statistik. Langkah-langkah pre-processing data meliputi:
Cleaning (Pembersihan Data):
- Mengisi nilai yang hilang (missing values) atau menghapus baris/kolom yang hilang.
- Menghapus atau memperbaiki data yang duplikat.
- Mengoreksi kesalahan dalam data seperti inkonsistensi dan kesalahan ketik.
Transformation (Transformasi Data):
- Mengubah data ke dalam format yang sesuai untuk analisis, seperti normalisasi atau standarisasi.
- Mengonversi data kategorikal ke dalam bentuk numerik (misalnya, menggunakan one-hot encoding atau label encoding).
- Menggabungkan fitur atau membuat fitur baru yang relevan untuk analisis (feature engineering).
Reduction (Reduksi Dimensi):
- Mengurangi jumlah fitur dalam dataset untuk mengurangi kompleksitas dan meningkatkan efisiensi.
- Teknik seperti Principal Component Analysis (PCA) atau t-SNE digunakan untuk merangkum informasi penting dari banyak fitur menjadi fitur yang lebih sedikit.
Integration (Integrasi Data):
- Menggabungkan data dari berbagai sumber atau dataset yang berbeda untuk membentuk dataset yang lebih lengkap.
Exploratory Data Analysis (EDA)
Exploratory Data Analysis (EDA) adalah proses awal dalam analisis data di mana data dieksplorasi secara visual dan statistik untuk memahami pola, hubungan, dan anomali.
Tujuan dilakukannya EDA yaitu untuk:
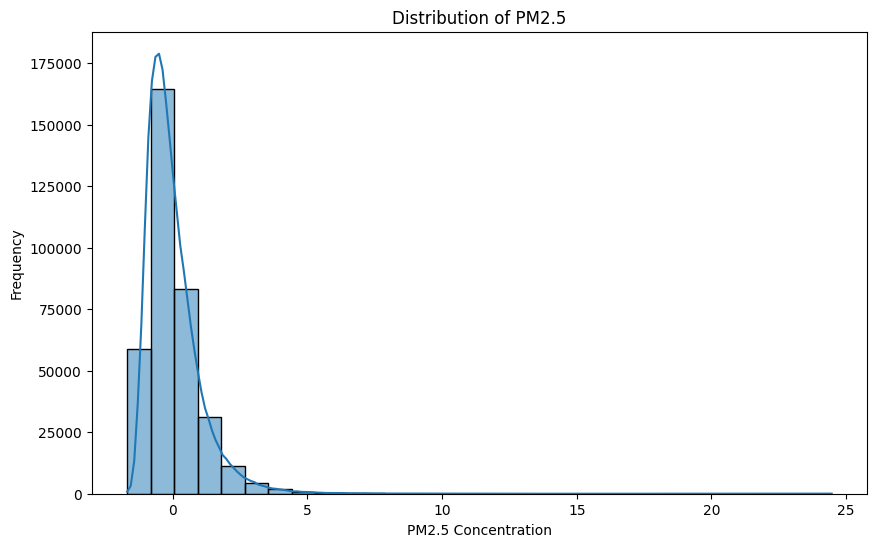
- Memahami Distribusi Data: menggunakan visualisasi seperti histogram, box plot, dan density plot untuk melihat distribusi setiap fitur.
- Mengidentifikasi Hubungan dan Korelasi: menggunakan scatter plot, pair plot, dan matriks korelasi untuk menemukan hubungan antara fitur-fitur dalam dataset.
- Mendeteksi Anomali: mencari outliers atau data yang tidak biasa yang mungkin mempengaruhi analisis atau model.
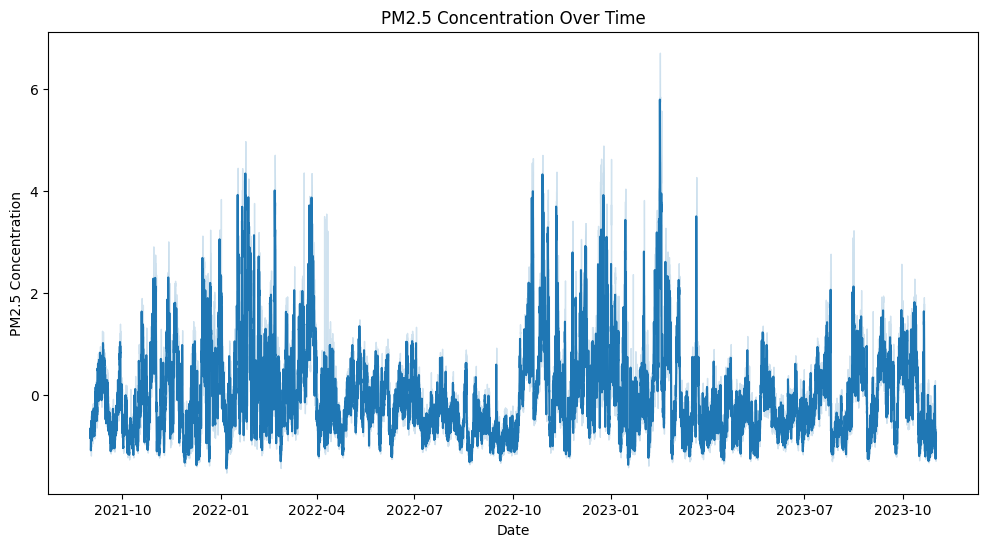
- Menentukan Pola dan Tren: menganalisis tren waktu, pola musiman, atau tren jangka panjang dalam data.
Langkah-langkah EDA
- Descriptive Statistics (Statistik Deskriptif): menghitung statistik dasar seperti mean, median, mode, standar deviasi, dan kuartil untuk memahami karakteristik data.
- Data Visualization (Visualisasi Data): menggunakan berbagai jenis grafik dan plot seperti bar plot, scatter plot, line plot, box plot, heatmap, dll., untuk mendapatkan wawasan visual dari data.
- Correlation Analysis (Analisis Korelasi): menghitung korelasi antara fitur-fitur numerik untuk melihat seberapa kuat hubungan antara fitur-fitur tersebut.
- Identifying Missing Values (Mengidentifikasi Nilai yang Hilang): menentukan lokasi dan jumlah missing values dalam dataset, dan memutuskan cara untuk menanganinya (misalnya, mengisi dengan mean/median, menghapus, atau menggunakan teknik imputasi).
Implementasi Pre-processing Data dan EDA
Dalam implementasi ini, kita akan menggunakan tools online https://colab.research.google.com/ dengan dataset air-quality-monitoring-in-european-cities yang bisa diakses pada platform kaggle. Dari dataset ini, kita akan melihat bagaimana kualitas udara di kota Ancona. Sebelum itu, kita perlu melakukan pre-processing data terlebih dahulu lalu kemudian melakukan Exploratory Data Analysis (EDA).
Berikut adalah library yang diperlukan dalam pre-processing dan Exploratory Data Analysis (EDA):

Berikut adalah informasi dasar dari dataset:
- 5 data teratas dalam dataset

- Tipe data dari masing-masing kolom dalam dataset:

Langkah selanjutnya adalah melakukan pre-processing data.
- Berikut adalah visualisasi nilai yang hilang dalam dataset (missing value):

- Salah satu cara untuk mengatasi missing value adalah dengan menghapus baris dengan nilai kosong dalam dataset, berikut adalah sintax-nya:

- Dari yang terlihat dari tipe data, kolom date memiliki tipe data object, maka kita harus mengubahnya menjadi tipe data datetime untuk mempermudah ketika ingin membuat visualisasi dari data berdasarkan waktunya, berikut adalah sintaxnya:

- Kemudian lakukan normalisasi data dan reduksi dimensi, berikut adalah sintaxnya:

Langkah selanjutnya adalah melakukan Exploratory Data Analysis (EDA)
- Lakukan statistik deskriptif dari data, berikut adalah sintaxnya:

- Kemudian hitung matriks korelasi hanya untuk kolom numerik dan visualisasikan menggunakan heatmap, berikut adalah hasilnya:

Berikut adalah visualisasi data yang sudah dilakukan pre-processing dan Exploratory Data Analysis (EDA)
- Histogram untuk melihat distribusi polutan


- Boxplot untuk melihat distribusi polusi udara berdasarkan nama stasiun


- Polusi udara berdasarkan waktu dengan grafik timeline


- Scatter plot untuk mendeteksi anomali

Kesimpulan:
Pre-processing data dan EDA adalah langkah-langkah krusial dalam alur kerja data science. Pre-processing memastikan data dalam kondisi yang dapat dianalisis, sementara EDA membantu memahami data secara mendalam sebelum menerapkan model atau analisis lanjutan. Keduanya bekerja bersama untuk memberikan landasan yang kuat dalam proses analisis data.
Lampiran:
Dataset dapat diakses melalui: https://www.google.com/url?q=https%3A%2F%2Fwww.kaggle.com%2Fdatasets%2Fyekenot%2Fair-quality-monitoring-in-european-cities
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Data Science SIB Batch 6
