
Prediksi harga Saham Unilever menggunakan LSTM
Ahmad Sholihin


Summary
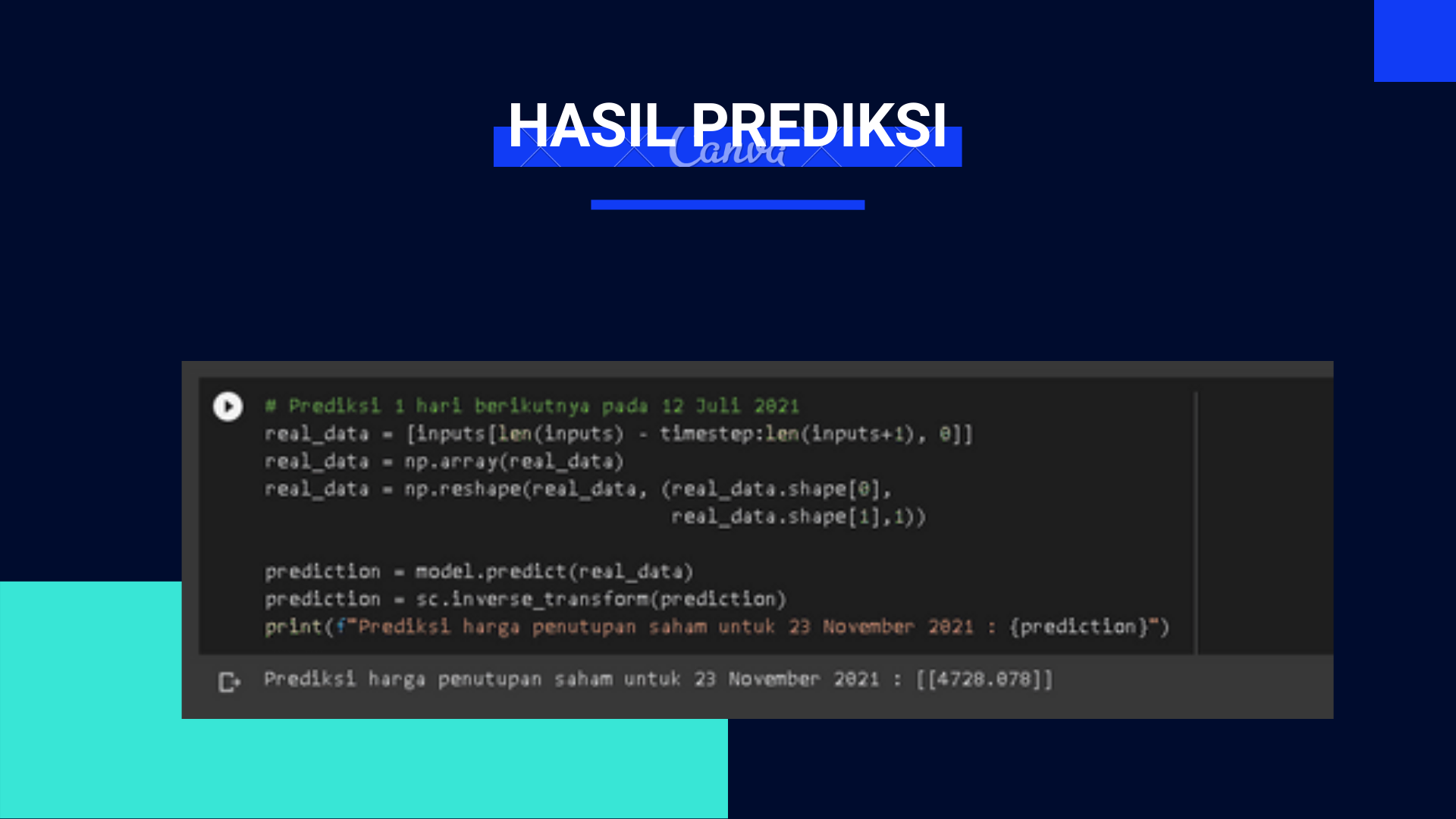
Program ini bertujuan untuk dapat memprediksi harga saham harian pada PT Unilever Indonesia Tbk pada 1 hari berikutnya. Algoritma yang akan di komparasi adalah algoritma dari deep learning yaitu Long Short Term Memory.
Description
Latar Belakang
Saham adalah bukti kepemilikan suatu perusahaan yang merupakan klaim atas penghasilan dan kekayaan perseroan. Perusahaan yang sahamnya dapat dibeli di Bursa Efek Indonesia disebut Perusahaan Tercatat. Saham merupakan salah satu produk pasar modal yang menjadi salah satu instrumen investasi untuk jangka panjang. Wujud dari saham yaitu berupa lembaran-lembaran kertas yang menyatakan bahwa yang namanya tercantum dalam lembaran tersebut adalah pemilik yang sah dari suatu perusahaan dengan persentase sesuai dengan nilai investasi yang ditanamkan pada perusahaan tersebut. Pemilik saham juga memiliki hak untuk mendapatkan dividen sesuai dengan jumlah saham yang dimilikinya. Perolehan dividen ini biasanya tergantung keuntungan dari perusahaan tersebut dan telah diatur sesuai dengan anggaran dasar perusahaan.
Membeli saham perusahaan di pasar modal merupakan investasi yang memiliki risiko lebih tinggi dibandingkan dengan instrumen investasi lain, seperti deposito, emas, tabungan berjangka, dan obligasi. Dengan risiko yang tinggi, investasi saham juga bisa memberikan imbalan atau keuntungan yang tinggi, baik dari dividen maupun kenaikan harga saham. Risiko kerugian yang paling lazim dalam investasi saham adalah harga saham yang lebih rendah dibandingkan saat pembelian. Kerugian investasi saham akan semakin besar jika harga saham terjun bebas. Naik turunnya harga saham sangat dipengaruhi banyak faktor. Harga saham tidak hanya bergantung pada kinerja perusahaan semata, melainkan juga sangat dipengaruhi psikologi pasar.
Dataset dan Library
Dataset yang digunakan dalam proyek ini diperolah dari Yahoo finance open dataset dan library yang digunakan yaitu Pandas, Numpy, Matplotlib, Seaborn, Scikit-Learn dan Keras. Serta Algoritma yang akan digunakan adalah Long Sort Term Memory(LSTM).
Pengenalan Algoritma
Long short term memory network (LSTM) adalah salah satu modifikasi dari recurrent neural network atau RNN. Banyak modifikasi dari RNN, tetapi LSTM merupakan salah satu yang populer di antaranya. LSTM hadir untuk melengkapi kekurangan RNN yang tidak dapat memprediksi kata berdasarkan informasi lampau yang disimpan dalam jangka waktu lama. Dengan demikian, LSTM mampu mengingat kumpulan informasi yang telah disimpan dalam jangka waktu panjang, sekaligus menghapus informasi yang tidak lagi relevan. LSTM lebih efisien dalam memproses, memprediksi, sekaligus mengklasifikasikan data berdasarkan urutan waktu tertentu.
Perbedaan mendasar dari LSTM dan RNN adalah bahwa LSTM melengkapi kekurangan-kekurangan yang dimiliki oleh pendahulunya, recurrent neural network, yang tidak dapat memprediksi data berdasarkan informasi yang telah disimpan dalam waktu cukup lama. Dengan kata lain, persoalan jangka waktu penyimpanan tidak menjadi permasalahan dalam LSTM. Sistem yang menerapkan LSTM dapat memproses, memprediksi, dan mengklasifikasikan informasi berdasarkan data deret waktu. Sesuai dengan konsepnya, LSTM dapat mengingat dan menghapus data-data lawas yang sudah tidak relevan lagi. Dengan demikian, manajemen informasi akan lebih komplet sekaligus aktual.
LSTM memiliki beberapa gerbang yang memiliki fungsi dan tugasnya masing-masing. Berikut penjelasan singkat mengenai struktur LSTM.
- FORGET GATE : Gerbang pertama dalam LSTM disebut dengan forget gate. Mudahnya, gerbang ini bertugas untuk melupakan beberapa informasi yang tidak relevan dan sudah tidak diperlukan oleh sebuah sistem. Alhasil, LSTM dapat menyajikan kumpulan informasi yang lengkap, tetapi tetap aktual sesuai dengan kebutuhan.
- INPUT GATE : Berikutnya, ada gerbang kedua, yakni input gate yang bertugas untuk memasukkan informasi yang berguna untuk mendukung keakuratan data. Tugas input gate adalah untuk menambahkan informasi yang sebelumnya telah diseleksi terlebih dahulu melalui gerbang forget gate. Gerbang ini tidak dimiliki oleh RNN yang hanya memungkinkan satu input data untuk satu output data. Dalam input gate kemudian dikenal istilah input modulation gate yang sering tidak ditulis dalam beberapa ulasan tentang LSTM. Sesuai namanya, input modulation gate berfungsi untuk memodulasi informasi yang ada, sehingga dapat mengurangi kecepatan konvergensi dari data zero-mean.
- OUTPUT GATE : Terakhir adalah output gate yang menjadi gerbang terakhir untuk menghasilkan informasi data yang komplet dan aktual. Gerbang ini bisa menjadi yang terakhir atas sebuah informasi atau hanya menjadi bagian dari tahap pertama saja, sebelum akhirnya informasi akan diproses lewat input gate di sel berikutnya.
Langkah Pembuatan Program
Data Undestanding memberikan gambaran awal tentang :
- Kekuatan data
- Kekurangan dan Batasan pengguna data
- Tingkat kesesuaian data dengan masalah bisnis yang akan dipecahkan
- Ketersediaan data (terbuka/tertutup biaya akses ,dsb
Data preprocessing adalah proses yang mengubah data mentah ke dalam bentuk yang lebih mudah dipahami. Proses ini penting dilakukan karena data mentah sering kali tidak memiliki format yang teratur. Selain itu, data mining juga tidak dapat memproses data mentah, sehingga proses ini sangat penting dilakukan untuk mempermudah proses berikutnya, yakni analisis data.

Deep learning adalah salah satu bidang machine learning yang pada dasarnya memiliki 3 layers neural network atau lebih. Neural network merupakan algoritma yang terinspirasi dari struktur dan fungsi otak manusia yang terdiri dari 3 layer, yaitu input layer, hidden layer dan output layer. Berikut merupakan fungsi dari masing-masing layer:
- Input Layer, mengandung data mentah.
- Hidden Layer, tempat di mana segala algoritma dan komputasi dilakukan.
- Output Layer, menghasilkan hasil sesuai dengan input yang diberikan.
Machine learning model adalah hasil dari fase latih (training phase) dalam pemelajaran mesin. Training phase ini gunanya untuk menemukan pola-pola di dalam data yang hendak dijadikan dasar pengetahuan sistem yang dibangun. Pola-pola tersebut yang disebut sebagai model. Bisa juga dari pengertian Machine learning model adalah algoritma machine learning yang sebelumnya telah dilakukan proses pelatihan/training dengan data latih tertentu sehingga dia siap digunakan untuk melakukan prediksi terhadap data baru.
Setelah memilih model, kini saatnya kamu melatih model yang telah diciptakan. Dalam proses ini, kamu harus memperhatikan seberapa baik model kamu melakukan generalisasi. Hal inilah yang biasa disebut overfitting dan underfitting, di mana keseimbangan dari optimalisasi dan generalisasi tidak seimbang. Generalisasi adalah kemampuan model untuk memprediksi data yang baru dijumpai dengan benar. Demi meningkatkan generalisasi, kamu dapat menyediakan lebih banyak data atau melakukan regularisasi – proses di mana model diberikan constraint tambahan sehingga sistem dapat lebih fokus terhadap aspek yang relevan.

Model machine learning yang telah dilatih kini siap untuk evaluasi. Gunakan set evaluasi yang berisi data-data baru untuk memverifikasi performa model ciptaanmu. Jika akurasi model kurang dari 50%, maka model tersebut perlu dikembangkan lagi. Di sisi lain, jika akurasi model sudah dapat mencapai 90% atau lebih, maka model tersebut sudah tergolong baik.
Metode evaluasi Model yang digunakan adalah
- MAE atau Mean Absolute Error menunjukkan nilai kesalahan rata-rata yang error dari nilai sebenarnya dengan nilai prediksi. MAE sendiri secara umum digunakan untuk pengukuran prediksi error pada analisis time series.
- Mean Absolut Percentage error (MAPE) adalah persentase kesalahan rata-rata secara multak.(absolut). Pengertian Mean Absolute Percentage Error adalah Pengukuran statistik tentang akurasi perkiraan (prediksi) pada metode peramalan. Pengukuran dengan menggunakan Mean Absolute Percentage Error (MAPE) dapat digunakan oleh masyarakat luas karena MAPE mudah difahami dan diterapkan dalam memprediksi akurasi peramalan. Metode Mean Abosolute Percentage Error (MAPE) memberikan informasi seberapa besar kesalahan peramalan dibandingkan dengan nilai sebenarnya dari series tersebut. Semakin kecil nilai presentasi kesalahan (percentage error) pada MAPE maka semakin akurat hasil peramalan tersebut.

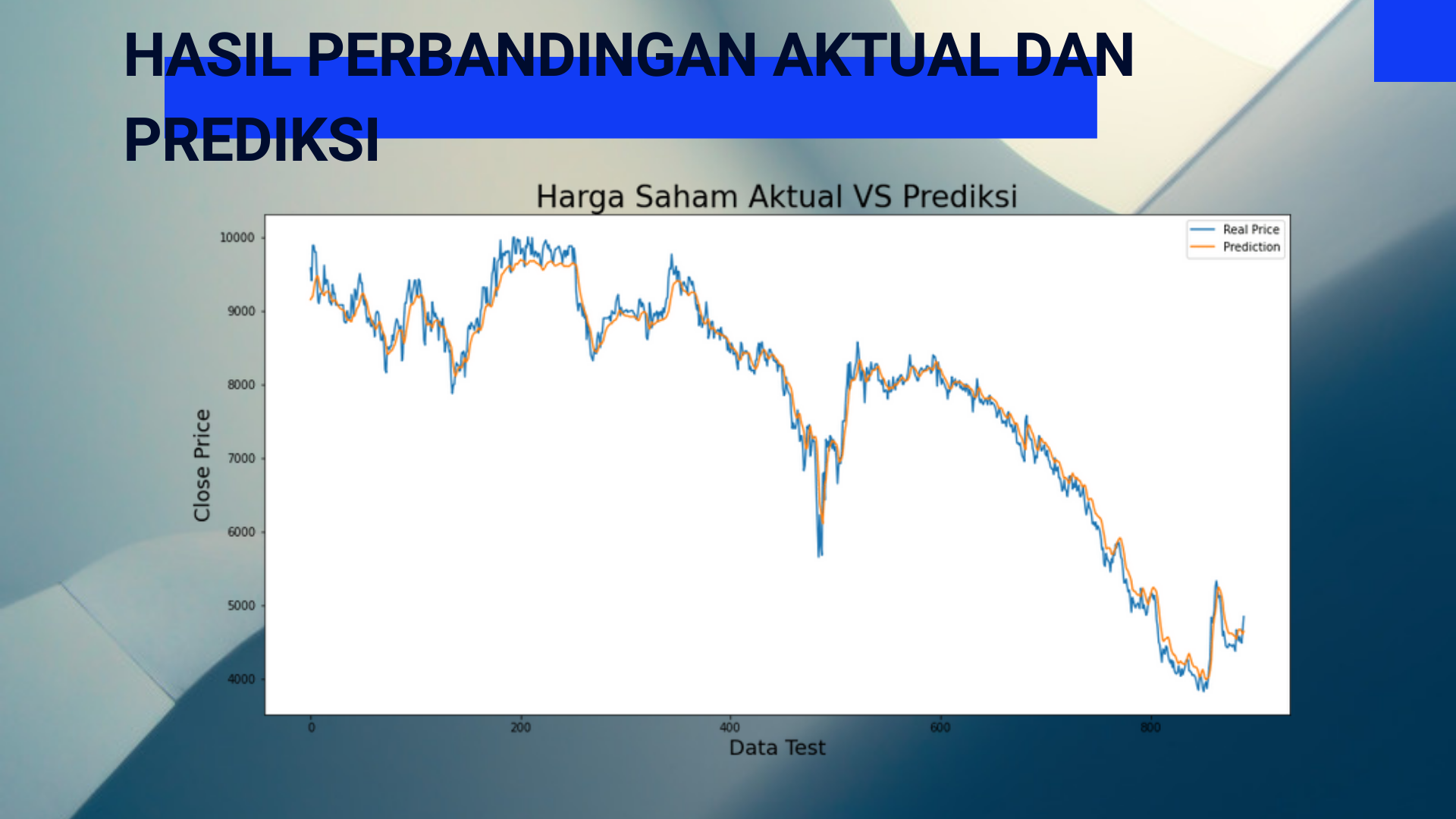
Berikut hasil dari evaluasi yang telah dilakukan


Informasi Course Terkait
Kategori: Artificial IntelligenceCourse: Deep Learning
