
Komparasi Algoritma Klasifikasi
Ahmad Sholihin


Summary
Komparasi Algoritma Klasifikasi adalah sebuah program dari bahasa pemrograman python yang digunakan untuk menentukan data pencemaran udara untuk diklasifikasikan. Algoritma yang akan di komparasi adalah algoritma Naive Bayes, KNN, SVM.
Description
Latar Belakang
Pencemaran merupakan kondisi yang buruk akibat tercampurnya zat-zat tertentu yang seharusnya tidak tercampur. Udara merupakan komponen yang sangat dibutuhkan oleh manusia, tumbuhan, dan hewan. Polusi udara atau pencemaran udara memiliki arti dan makna yang sama. Pengertian pencemaran udara adalah peristiwa masuknya atau tercampurnya unsur-unsur berbahaya ke dalam lapisan udara yang dapat mengakibatkan menurunnya kualitas udara di lingkungan.
Menurut Chambers, definisi pencemaran udara atau polusi udara adalah bertambahnya substrat atau bahan kimia atau fisik ke dalam udara hingga mencapai jumlah tertentu, sehingga dapat dirasakan oleh manusia atau dapat diukur dan dihitung serta memberikan dampak pada makhluk hidup. Parker berpendapat pencemaran udara adalah perubahan atmosfer karena masuknya bahan kontaminan alami atau buatan ke dalam atmosfer.
Polutan merupakan suatu bahan atau zat yang memiliki kadar melebihi ambang batas pada waktu yang tidak tepat, sehingga menjadi bahan pencemar lingkungan. Terdapat beberapa polutan yang dapat menjadi penyebab pencemaran udara, seperti karbon monoksida, oksigen nitrogen, oksida sulfur, CFC, hidrokarbon, dan radikal bebas.
Polusi udara adalah masalah lingkungan yang nyata. Banyak negara telah menyatakan perang untuk melawan polusi ini dan menekan peningkatan pemanasan global. Misalnya, kendaraan atau alat transportasi berbasis bahan bakar fosil perlahan mulai digantikan dengan yang bertenaga listrik. Di samping itu, peningkatan kesadaran menghijaukan kembali Bumi dengan menanam pohon telah dilakukan sebagai "paru-paru dunia".
Dataset dan Library
Dataset yang digunakan dalam proyek ini diperolah dari Open data Jakarta dengan judul pencemaran udara dan library yang digunakan yaitu Pandas, Numpy, Matplotlib, Seaborn, Scikit-Learn. Serta Algoritma yang akan digunakan adalah Naive Bayes, KNN dan SVM.
Pengenalan Algoritma
Naive Bayes adalah algoritma machine learning untuk masalah klasifikasi. Ini didasarkan pada teorema probabilitas Bayes. Hal ini digunakan untuk klasifikasi teks yang melibatkan set data pelatihan dimensi tinggi. Beberapa contohnya adalah penyaringan spam, analisis sentimental, dan klasifikasi artikel berita. Tidak hanya dikenal karena kesederhanaannya, tetapi juga karena keefektifannya. Sangat cepat untuk membangun model dan membuat prediksi dengan algoritma Naive Bayes. Naive Bayes adalah algoritma pertama yang harus dipertimbangkan untuk memecahkan masalah klasifikasi teks. Oleh karena itu, Anda harus mempelajari algoritma ini secara menyeluruh.
Algoritma k-Nearest Neighbor adalah algoritma supervised learning dimana hasil dari instance yang baru diklasifikasikan berdasarkan mayoritas dari kategori k-tetangga terdekat. Tujuan dari algoritma ini adalah untuk mengklasifikasikan obyek baru berdasarkan atribut dan sample-sample dari training data. Algoritma k-Nearest Neighbor menggunakan Neighborhood Classification sebagai nilai prediksi dari nilai instance yang baru. Dalam menentukan nilai k, bila jumlah klasifikasi kita genap maka sebaiknya kita gunakan nilai k ganjil, dan begitu pula sebaliknya bila jumlah klasifikasi kita ganjil maka sebaiknya gunakan nilai k genap, karena jika tidak begitu, ada kemungkinan kita tidak akan mendapatkan jawaban.
Algoritma Support Vector Machine merupakan salah satu algoritma yang termasuk dalam kategori Supervised Learning, yang artinya data yang digunakan untuk belajar oleh mesin merupakan data yang telah memiliki label sebelumnya. Sehingga dalam proses penentuan keputusan, mesin akan mengkategorikan data testing ke dalam label yang sesuai dengan karakteristik yang dimiliki nya. Cara kerja dari metode Support Vector Machine khususnya pada masalah non-linear adalah dengan memasukkan konsep kernel ke dalam ruang berdimensi tinggi. Tujuannya adalah untuk mencari hyperplane atau pemisah yang dapat memaksimalkan jarak (margin) antar kelas data. Untuk menemukan hyperplane terbaik, kita dapat mengukur margin kemudian mencari titik maksimalnya. Proses pencarian hyperplane yang terbaik ini adalah ini dari metode Support Vector Machine ini.
Langkah Pembuatan Program
Data Understanding memberikan gambaran awal tentang :
- Kekuatan data
- Kekurangan dan Batasan pengguna data
- Tingkat kesesuaian data dengan masalah bisnis yang akan dipecahkan
- Ketersediaan data (terbuka/tertutup biaya akses ,dsb
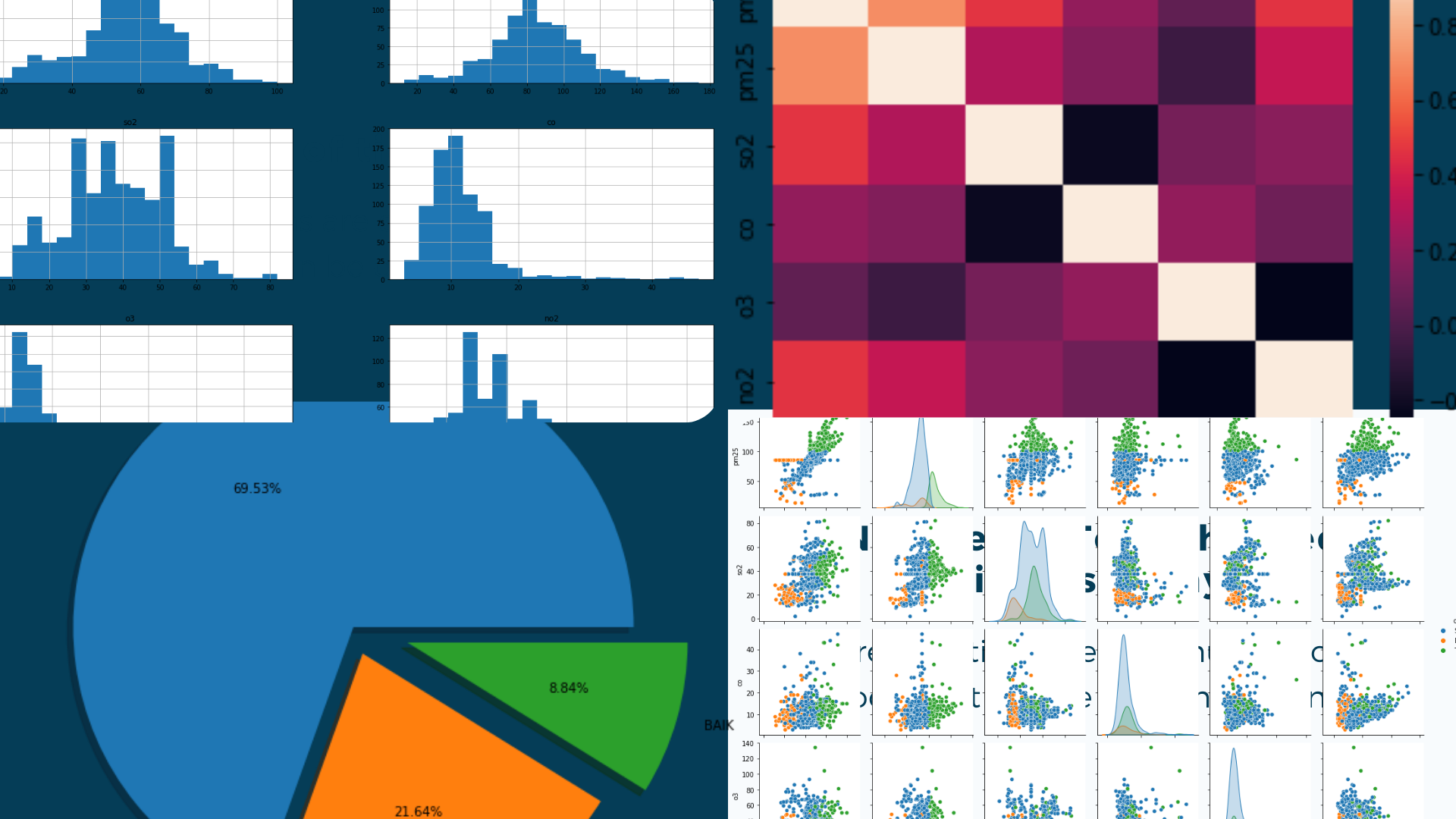
Data preprocessing adalah proses yang mengubah data mentah ke dalam bentuk yang lebih mudah dipahami. Proses ini penting dilakukan karena data mentah sering kali tidak memiliki format yang teratur. Selain itu, data mining juga tidak dapat memproses data mentah, sehingga proses ini sangat penting dilakukan untuk mempermudah proses berikutnya, yakni analisis data.

Machine learning model adalah hasil dari fase latih (training phase) dalam pemelajaran mesin. Training phase ini gunanya untuk menemukan pola-pola di dalam data yang hendak dijadikan dasar pengetahuan sistem yang dibangun. Pola-pola tersebut yang disebut sebagai model. Bisa juga dari pengertian Machine learning model adalah algoritma machine learning yang sebelumnya telah dilakukan proses pelatihan/training dengan data latih tertentu sehingga dia siap digunakan untuk melakukan klasifikasi terhadap data baru.

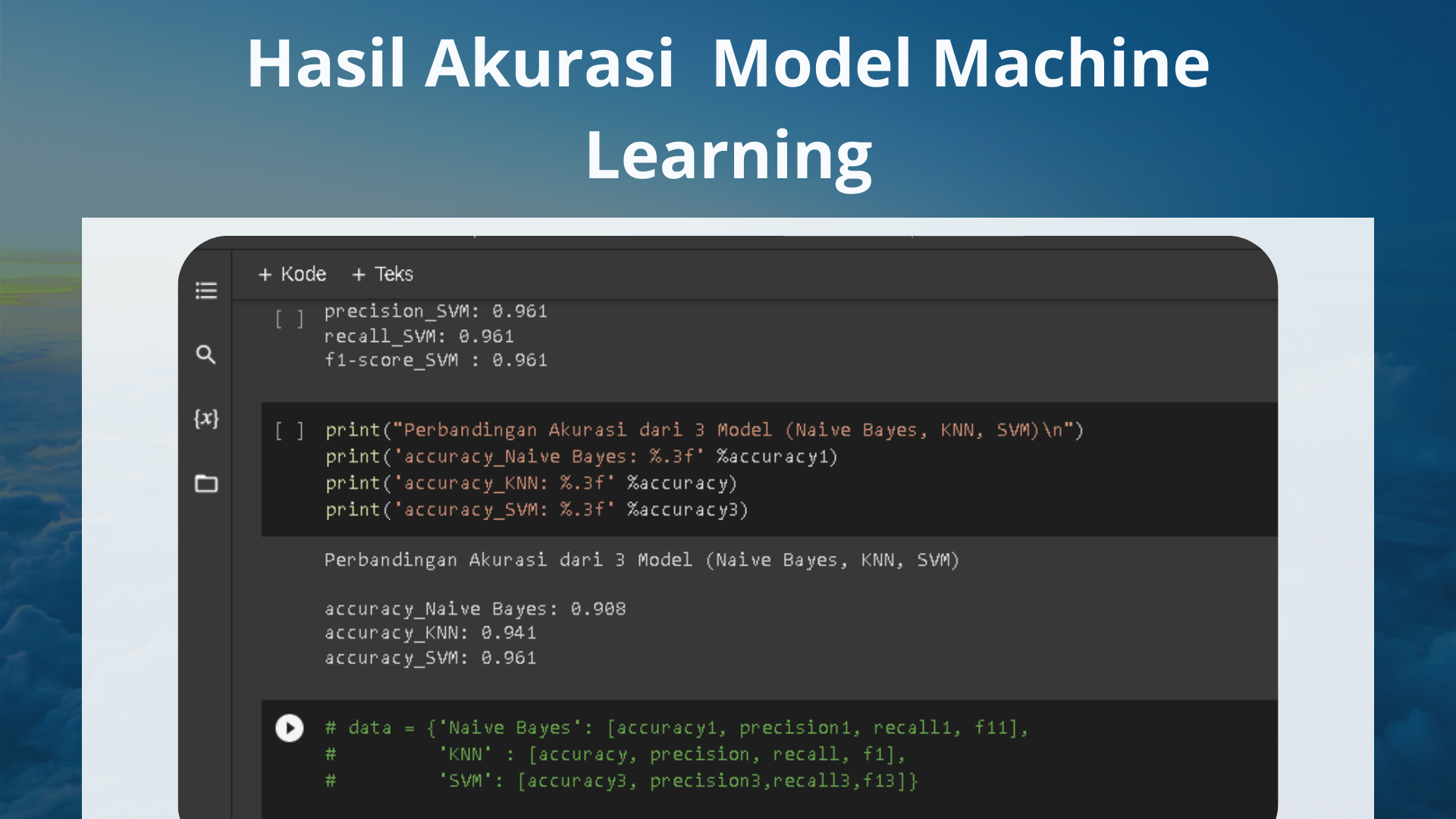
Accuracy menggambarkan seberapa akurat model dapat mengklasifikasikan dengan benar. Maka, accuracy merupakan rasio prediksi benar (positif dan negatif) dengan keseluruhan data. Dengan kata lain, accuracy merupakan tingkat kedekatan nilai prediksi dengan nilai aktual (sebenarnya). Berikut hasil dari evaluasi yang telah dilakukan

Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Master Class Data Science



