
Prediksi Biaya Medis
Mohamad Arif Muharam



Summary
Regresi merupakan salah satu task data science yang bertujuan untuk memprediksi nilai baru yang bersifat kontinu. Prediksi dilakukan berdasarkan data sebelumnya kemudian dapat memprediksi nilai yang akan datang. Pada portofolio kali ini akan menggunakan dataset medical cost berikut https://www.kaggle.com/datasets/mirichoi0218/insurance. Dari dataset tersebut permasalahan yang akan diangkat yaitu berdasarkan variabel apa sehingga biaya medis dapat berubah baik itu biayanya menjadi tinggi ataupun rendah.
Description
Pada dataset diketahui kolom - kolom nya yaitu : age, sex, bmi, children, smoker, region, dan charges. Masing - masing kolom akan dilihat korelasinya dengan charges (biaya). Sehingga diketahui hal atau variabel apa yang menjadikan biaya medis mengalami perubahan atau perbedaan. Untuk pembuatan model nya sebagai berikut :
Import library dan membaca data
Mengimport beberapa library yang dibutuhkan dan membaca atau memasukkan datapada variabel dengan fungsi read_cvs pada pandas.
Melihat jumlah baris, kolom, dan nilai yang kosong
Melihat jumlah baris dan kolom pada dataset. Kemudian mengecek juga apakah terdapat nilai yang kosong (missing value) pada data.
Feature Engineering
Mengubah feature pada tipe data string menjadi integer.

Eksplorasi Data (Scatter plot dan Heatmap)
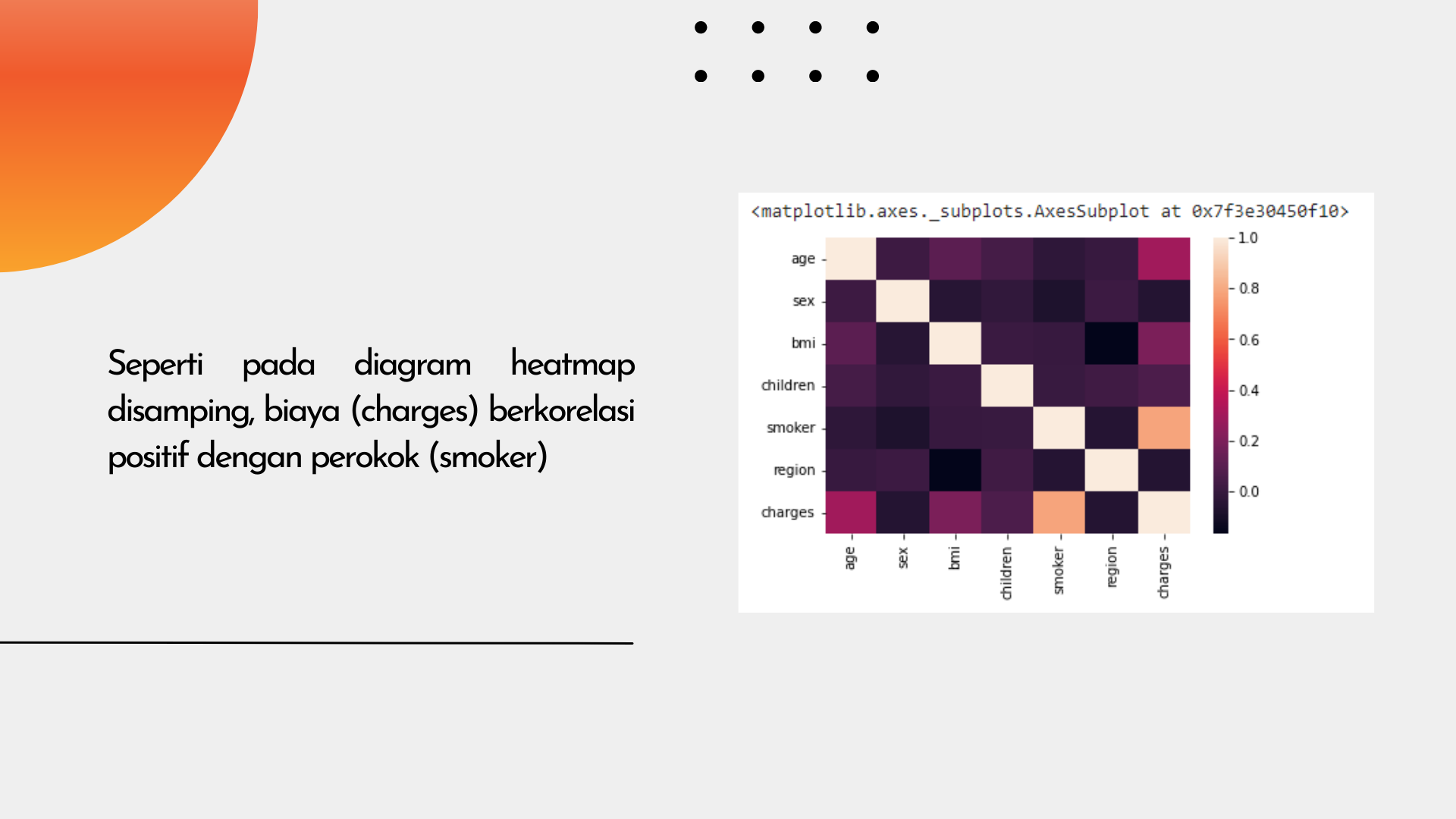
Melihat korelasi yang ada pada masing - masing variabel. Pada visualisasi dalam bentuk heatmap dapat terlihat variabel yang memiliki korelasi yang positif dengan kolom charges (biaya) yaitu smoker (perokok).

Visualisasi Data
Pada visualisasi berikut dapat dilihat variabel charges dan warna yang menunjukkan variabel smoker. Untuk warna kuning ditujukkan untuk perokok sedangkan untuk warna biru bukan perokok. Secara umum, untuk perokok biaya (charges) yang harus dikeluarkan cenderung tinggi dibandingkan yang tidak perokok. Walaupun begitu kemungkinan ada variabel lainnya yang menjadi biaya medis lebih tinggi atau rendah seperti age (umur), atau bmi (indeks massa tubuh).

Perbandingan Algoritma

Terdapat beberapa algoritma yang dipakai untuk mencari yang terbaik. Algoritma yang dipakai yaitu Support Vector Machine (SVM), Decision Tree dan Linear Regression. Jika dilihat terdapat beberapa evaluasi metrik yang dipakai untuk r2 menandakan seberapa baik model fit dengan data dengan rentang 0 - 1. Jika nilainya 1 maka model dikatakan sudah baik atau tepat. Untuk MAE dan RMSE merupakan nilai error, sehingga diharapkan nilai nya kecil. Algoritma yang memiliki nilai r2 besar terdapat pada algoritma linear regression namun nilai MAE yang kecil terdapat pada algoritma SVM.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Python Data Science untuk Pemula
