
Klasifikasi Chord Musik Menggunakan Random Forest
Keisha Maura Putri



Summary
Dataframe atau data yang digunakan dalam proses klasifikasi ini menggunakan dataset file audio yang berisi hasil record audio untuk kunci Major dan Minor yang berdurasi kurang lebih 2 - 3 detik per file nya. File ini selanjutnya akan di transformasi menggunakan algoritma FFT yang juga dibantu dengan beberapa fungsi atau beberapa proses yang nantinya dapat membantu melakukan konversi atau pengubahan data file audio tersebut menjadi bentuk teks atau informasi terkait file audio tersebut. Di akhir, proses klasifikasi akan menggunakan classifier Random Forest yang akan memperoleh nilai akurasi prediksi sebesar 95%.
Description
A. Data Preprocessing & Exploration
Lakukan import terhadap library-library yang kiranya diperlukan.

Melakukan inisialisasi terhadap variabel-variabel yang diperlukan, lalu membuat suatu perulangan untuk menentukan nilai start_freq juga data_freq untuk 12 nada dan 8 oktaf, yang pada setiap iterasinya nilai frekuensi saat ini (start_freq) akan dikalikan dengan 2^(1/12) lalu disimpan dalam list data_freq.

Melakukan display file audio yang dipilih ingin ditampilkan untuk di play, dalam hal ini, adalah file audio Major_20.wav yang tersimpan dalam ‘audio_1’.

Melakukan plotting terkait gelombang suara berdasarkan sinyal dalam domain waktu dan frekuensi yang dilakukan dengan konversi file audio yang diinginkan menggunakan algoritma Fast Fourier Transform (FFT).



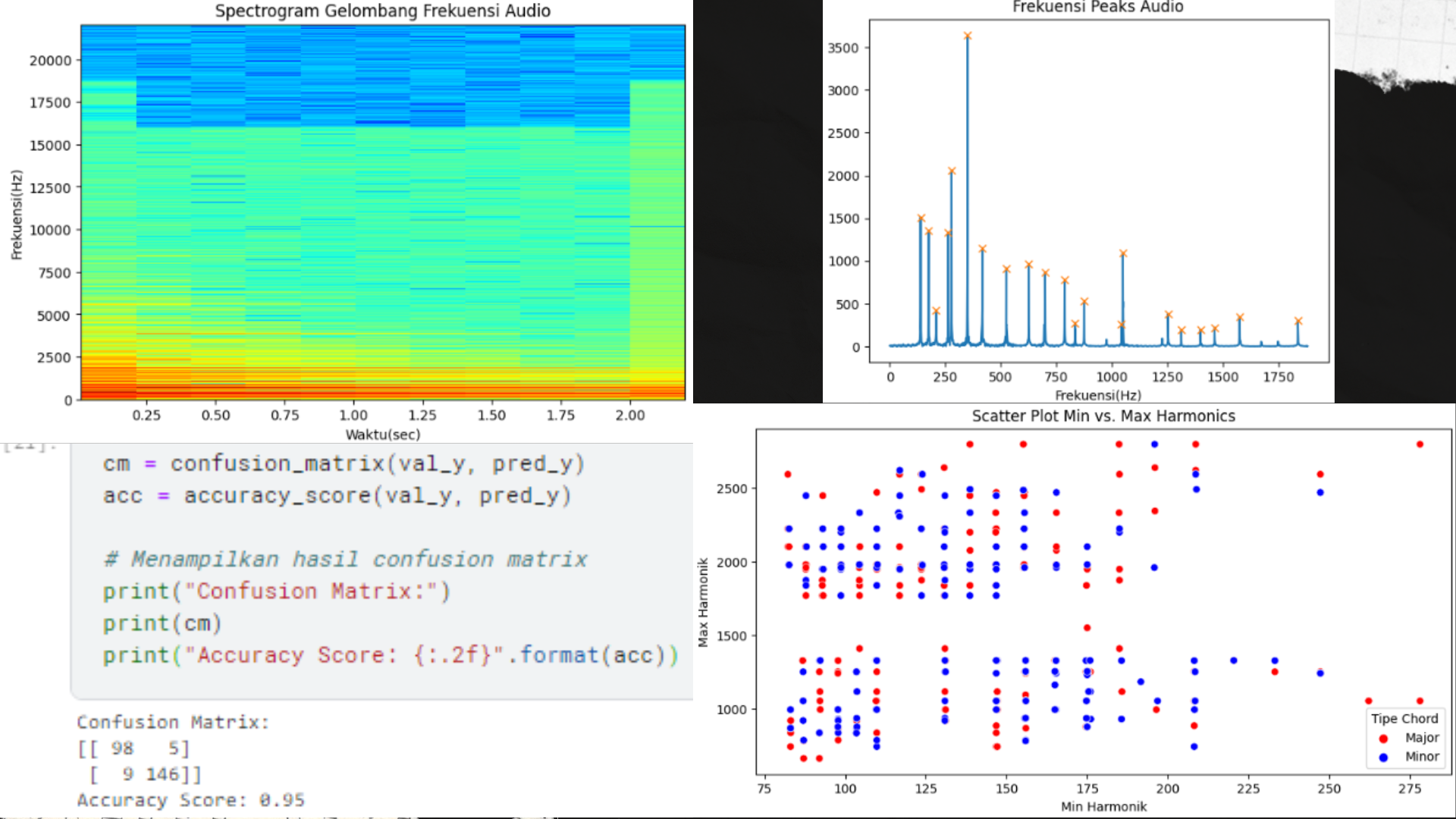
Melakukan plotting kembali terhadap gelombang frekuensi audio dalam bentuk spectogram.


Melakukan pembuatan fungsi peaks_freq yang akan melakukan konversi terhadap file audio yang diinginkan menggunakan algoritma FFT mencari titik ‘peak’ file audio atau nilai frekuensi pada level amplitudo yang tinggi. Ketika fungsi peaks_freq dipanggil atau dijalankan, maka juga menampilkan plotting terkait distribusi frekuensi peak dari file audio tersebut di samping menampilkan nilai angka frekuensi peaks audio.



Menentukan path untuk folder Audio_Files, kemudian lakukan iniliasasi variabel max_harm_length yang diikuti dengan pembuatan list data. Selanjutnya, diikuti dengan pengulangan for untuk memproses file-file audio yang terdapat dalam folder tersebut yang akhirnya akan dikonversi menjadi bentuk data atau informasi terkait audio.

Melakukan pembuatan Dataframe df, dan menentukan nama kolom melalui cols, yang diantaranya terdapat kolom Tipe Chord, Nama File, Min Harmonik, Max Harmonik, juga Jumlah Harmonik. Untuk penambahan kolom nilai tiap harmonik pada file audio, dicari tahu berapa jumlah peaks atau harmonik terbanyak pada folder audio, yang mana menunjukkan bahwa jumlah harmonik terbanyak dalam folder audio adalah sebanyak 38 harmonik, maka pada dataframe, kolom harmonik akan dibuat sebanyak 38 kolom.

Melakukan eksplorasi dataframe df dengan mencari tahu jumlah baris dan kolom dari dataframe df, kemudian menampilkan 10 kolom pertama dataframe menggunakan perintah df.head(10).


Masih dalam proses eksplorasi data, untuk melihat informasi terkait dataframe df, maka digunakan perintah df.info() untuk menampilkan informasi terkait jumlah dan nama kolom, serta jumlah data non-null dan tipe data dalam dataframe df.

Untuk proses eksplorasi data selanjutnya, dilakukan perhitungan jumlah data untuk Tipe Chord Major dan Minor, untuk mengetahui perbandingan data berdasarkan Tipe Chord.

Menampilkan informasi statistik pada kolom Jumlah Harmonik untuk dataframe df, yang mencakup informasi terkait jumlah, nilai rata-rata, standar deviasi, minimal, maksimal, serta kuartil data kolom Jumlah Harmonik.

Membuat plotting menggunakan scatter plot untuk menampilkan distribusi minimal dan maksimal harmonik berdasarkan Tipe Chord yang diawali dengan pembuatan subplot berukuran 10 x 5. Pada plotting tersebut, data Tipe Chord Major diwakili oleh warna merah dan Tipe Chord Minor diwakili oleh warna biru.


B. Data Processing
Membuat salinan dataframe df dan menyimpannya dalam df_original, dimana di dalamnya juga akan dilakukan penambahan kolom ‘Interval 1’ yang datanya didapatkan dengan cara membagi data pada kolom ‘Harmonik 2’ dan kolom ‘Harmonik 1’. Untuk melihat visualisasi distribusi ‘Harmonik 2’ dan ‘Interval 1’, dilakukan pembuatan subplot berukuran 7 x 5 yang diberi kode warna merah untuk Tipe Chord Major dan kode warna biru untuk Tipe Chord Minor.


Membuat salinan kembali untuk dataframe df_original, yang disimpan pada dataframe df, dimana di dalamnya terdapat penambahan kolom baru menggunakan pengulangan for untuk kolom Interval.


Melakukan plotting terhadap data kolom ‘Interval’ berdasarkan Tipe Chord Major dan Minor yang diwakili oleh warna merah dan biru, untuk melihat kolom mana yang kiranya dapat digunakan dalam proses training dan prediksi data.



C. Data Training & Prediction
Melakukan import untuk library-library yang kiranya diperlukan dalam proses training dan prediksi data, dalam hal ini proses klasifikasi yang dilakukan akan menggunakan classifier Random Forest.

Melakukan pengulangan for untuk penambahan kolom Interval 4_1, 5_1, dan 6_1 yang diperoleh berdasarkan hasil bagi ‘Harmonik i’ dan ‘Harmonik 1’, kemudian melakukan penggantian nilai atau pelabelan pada data kolom Tipe Chord yang semula ‘Major’ dan ‘Minor’ menjadi 1 dan 0. Hal ini dilakukan untuk menyiapkan data pada proses training dan prediksi model klasifikasi, sehingga model dapat dilatih untuk memprediksi jenis akord (Major atau Minor) berdasarkan fitur-fitur ini.


Melakukan pengecekan nilai akurasi klasifikasi menggunakan classifier Random Forest dengan menggunakan metode Cross Validation. Semakin besar nilainya, semakin bagus akurasinya.

Melakukan pendefinisian kembali classifier yang akan digunakan untuk proses training dan prediksi data, dimana dalam hal ini menggunakan classifier Random Forest.

Melakukan pembuatan confusion matrix berdasarkan hasil Data Training & Prediction yang telah dilakukan sebelumnya, dan ketika ditampilkan didapatkan confusion matrix dengan akurasi bernilai 95% untuk klasifikasi Chord Musik menggunakan Random Forest. Dengan rincian True Positive (TP) sebanyak 98, True Negative (TN) sebanyak 146, False Positive (FP) sebanyak 5, dan False Negative (FN) sebanyak 9.

Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Data Science



