
Machine Learning | Klasifikasi Random Forest
Najwaa Nahda Assegaf



Summary
Proyek ini menggabungkan analisis data dan machine learning untuk mengkategorikan pola pengeluaran pelanggan. Menggunakan Python dan Pandas, data dimuat dan diproses untuk mengeksplorasi pola dan korelasi antar fitur. Rekayasa fitur menyediakan wawasan tambahan yang, bersama fitur asli, membantu melatih model Random Forest. Model ini diuji dengan validasi silang untuk menjamin keandalan prediksinya, tidak hanya pada data yang telah dipelajari tetapi juga pada data baru.
Evaluasi model menggunakan metrik akurasi dan matriks kebingungan menunjukkan kemampuan prediksi yang tinggi, sementara visualisasi dari Matplotlib dan Seaborn membantu memahami dan menyajikan hasilnya secara intuitif. Proyek ini membuktikan bagaimana teknik data-driven dapat meningkatkan strategi bisnis, manajemen inventaris, dan pengalaman pelanggan, merefleksikan keterampilan analisis yang mendalam dan pemahaman machine learning yang kuat, yang merupakan aset penting dalam portofolio profesional di bidang data science.
Description
Dataset
Sebuah dataset adalah kumpulan data yang disusun dan disajikan dalam format tertentu, biasanya dalam bentuk tabel, di mana baris mewakili sampel individu dan kolom mewakili variabel atau fitur tertentu dari sampel tersebut. Dataset digunakan dalam berbagai bidang, termasuk ilmu komputer, statistik, dan penelitian ilmiah, sebagai bahan dasar untuk analisis, pemodelan, dan pembuatan keputusan.
Dataset customer_shopping_data.csv dari Kaggle yang disediakan oleh Mehmet Tahiri Aslan adalah kumpulan data yang berisi informasi tentang transaksi belanja pelanggan di berbagai mal. Setiap baris dalam dataset mewakili satu transaksi belanja dan menyajikan informasi seperti nomor faktur, ID pelanggan, jenis kelamin, usia, kategori produk yang dibeli (seperti pakaian, sepatu, atau buku), kuantitas produk yang dibeli, harga per unit, metode pembayaran, tanggal faktur, dan nama pusat perbelanjaan di mana pembelian dilakukan. Dataset ini dapat digunakan untuk analisis perilaku belanja, segmentasi pelanggan, prediksi penjualan, dan banyak aplikasi analisis data lainnya. Berikut adalah atribut-atribut dalam Dataset:
- invoice_no: Nomor faktur transaksi belanja. Ini merupakan identifier unik untuk setiap transaksi.
- customer_id: ID unik yang mewakili setiap pelanggan.
- gender: Jenis kelamin pelanggan (misalnya, laki-laki atau perempuan).
- age: Usia pelanggan.
- category: Kategori produk yang dibeli dalam transaksi tersebut (misalnya, pakaian, sepatu, buku).
- quantity: Jumlah produk yang dibeli dalam transaksi tersebut.
- price: Harga per unit produk yang dibeli.
- payment_method: Metode pembayaran yang digunakan untuk transaksi tersebut (misalnya, kartu kredit, kartu debit, tunai).
- invoice_date: Tanggal transaksi dilakukan.
- shopping_mall: Nama pusat perbelanjaan di mana transaksi dilakukan.
Dataset customer_shopping_data.csv bersumber dari link kaggle:
https://www.kaggle.com/datasets/mehmettahiraslan/customer-shopping-dataset
Klasifikasi Data
Klasifikasi data adalah sebuah proses dalam pembelajaran mesin yang melatih sebuah model untuk memprediksi label kategori dari sebuah dataset. Proses ini melibatkan penggunaan algoritma tertentu untuk mengidentifikasi pola dalam data dan menggunakan pola tersebut untuk mengkategorikan entri data baru. Sebagai contoh, klasifikasi email menjadi spam atau bukan spam adalah salah satu penggunaan umum dari teknik klasifikasi. Mengklasifikasikan dataset customer-shopping-dataset penting karena dataset ini memberikan informasi mendalam tentang perilaku belanja pelanggan di berbagai pusat perbelanjaan. Berikut beberapa alasan mengapa dataset ini perlu diklasifikasikan:
- Mengidentifikasi pola pengeluaran
- Segmentasi pelanggan
- Optimasi penawaran dan promosi
- Perencanaan persediaan dan stok
- Meningkatkan pengalaman pelanggan
- Analisis lebih lanjut
Secara keseluruhan, dengan mengklasifikasikan dataset customer_shopping_dataset.csv, tidak hanya memahami pola belanja saat ini tetapi juga dapat meramalkan dan merespons kebutuhan pelanggan di masa depan dengan lebih efektif.
Random Forest
Random Forest adalah algoritma pembelajaran mesin ensemble yang bekerja dengan membuat banyak pohon keputusan selama fase pelatihan dan output kelas dengan mode (kelas yang paling sering) atau prediksi rata-rata dari pohon-pohon individual. Ini umum digunakan untuk tugas-tugas klasifikasi dan regresi karena kemampuannya yang baik dalam mengurangi overfitting dan menangani dataset besar dengan dimensi fitur yang tinggi.
Dalam konteks data ini, Random Forest digunakan untuk mengklasifikasikan pelanggan berdasarkan perilaku pengeluaran mereka, yang diindikasikan oleh pembuatan fitur is_high_spending sebagai target klasifikasi. Model ini kemudian dievaluasi menggunakan metrik seperti akurasi dan laporan klasifikasi untuk menilai kinerjanya, dan menggunakan validasi silang untuk memastikan bahwa model tersebut tidak overfit dan berkinerja baik pada data yang tidak terlihat selama pelatihan.
Proses Klasifikasi berbasis Random Forest
Import library yang diperlukan, memuat dan memproses dataset:

Import pandas as pd adalah perintah untuk mengimpor library pandas sebagai pd, sehingga dapat menggunakan fungsi-fungsi pandas dengan menggunakan alias pd.df = pd.read_csv(customer_shopping_data.csv) membaca file CSV dengan nama customer_shopping_data.csv dan memuatnya ke dalam sebuah objek DataFrame yang disebut df. Sebagai informasi, DataFrame adalah struktur data utama yang digunakan dalam pandas untuk mengelola data tabular.
Eksplorasi data:


Perintah df.head() digunakan untuk menampilkan lima baris pertama (default) dari DataFrame df. Ini berguna untuk melihat contoh data pertama dalam DataFrame dan memastikan bahwa pembacaan data berjalan dengan baik. df.head() digunakan untuk menampilkan lima baris pertama (default) dari DataFrame df. Ini berguna untuk melihat contoh data pertama dalam DataFrame dan memastikan bahwa pembacaan data berjalan dengan baik. df.info() digunakan untuk menampilkan informasi lengkap mengenai DataFrame df. Informasi ini mencakup jumlah baris, tipe data dari masing-masing kolom, dan apakah ada nilai-nilai null dalam DataFrame. Ini membantu dalam pemahaman awal tentang data yang dimiliki. print(df.columns) mencetak daftar kolom atau atribut yang ada dalam DataFrame df. Daftar ini mencakup nama-nama kolom yang ada dalam data, dan ini berguna untuk memahami struktur data yang lebih detail. Diketahui kolom dalam tabel dataset adalah invoice_no, customer_id, gender, age, category, quantity, price, payment_method, invoice_date, shopping_mall.
Pembuatan fitur tambahan:

Menghitung total pengeluaran (total_spent) untuk setiap transaksi dengan mengalikan price dengan quantity. Menghitung median dari total_spent dan menyimpannya di variabel median_spent. Membuat kolom baru bernama is_high_spending di mana diberikan nilai 1 jika total_spent untuk transaksi tersebut lebih dari median_spent dan diberikan nilai 0 jika total_spent untuk transaksi tersebut kurang dari atau sama dengan median_spent. Dengan demikian, kolom is_high_spending mengklasifikasikan pelanggan menjadi dua kategori berdasarkan apakah total pengeluaran mereka di atas atau di bawah median total pengeluaran di dataset.
One-hot encoding untuk variabel kategorikal:

One-hot encoding adalah teknik untuk mengubah variabel kategorikal menjadi format yang bisa diberikan ke algoritma machine learning. Setiap kategori unik dalam kolom asli akan menjadi kolom baru di DataFrame.Kode tersebut menggunakan one-hot encoding untuk mengubah variabel kategorikal dalam DataFrame df seperti gender, category, payment_method, dan shopping_mall menjadi representasi biner yang memungkinkan algoritma pembelajaran mesin memprosesnya. Hasilnya adalah DataFrame baru yang menggantikan df, di mana setiap nilai kategorikal menjadi kolom-kolom baru yang berisi 0 atau 1, mengindikasikan keberadaan atau ketiadaan nilai tersebut dalam setiap observasi. Ini mempermudah analisis dan pemodelan data dengan mengkonversi informasi kategorikal menjadi bentuk numerik yang dapat digunakan oleh algoritma machine learning.
Pembagian data menjadi fitur dan label serta train-test split:

Kode tersebut mengimpor fungsi train_test_split dari pustaka sklearn yang digunakan untuk membagi dataset menjadi set pelatihan dan set pengujian. Lalu, mempersiapkan fitur (X) dengan menghapus kolom-kolom yang tidak diperlukan dari DataFrame df menggunakan fungsi drop. Kolom target atau label (y) yang akan diprediksi adalah is_high_spending. Membagi data tersebut menjadi set pelatihan (X_train dan y_train) dan set pengujian (X_test dan y_test) dengan proporsi 80% untuk pelatihan dan 20% untuk pengujian, menggunakan fungsi train_test_split dengan random_state 42 agar pembagian data konsisten setiap kali kode dijalankan.
Membuat dan melatih model klasifikasi, memprediksi data uji:

Kode tersebut menggunakan algoritma Random Forest dari pustaka sklearn untuk klasifikasi. Pertama, mengimpor kelas RandomForestClassifier. Kemudian, membuat sebuah instance dari kelas tersebut dengan nama clf dan mengatur random_state ke 42 untuk memastikan hasil yang dapat direproduksi. Setelah itu, melatih model tersebut dengan data pelatihan (X_train dan y_train) menggunakan metode fit. Setelah model dilatih, menggunakan model tersebut untuk memprediksi label dari data pengujian (X_test) dan menyimpan hasil prediksi tersebut dalam variabel y_pred.
Evaluasi Model:

Kode tersebut bertujuan untuk mengevaluasi performa model klasifikasi yang telah dilatih. Dari pustaka sklearn, diimpor fungsi accuracy_score dan classification_report. Fungsi accuracy_score digunakan untuk menghitung akurasi model dengan membandingkan label sebenarnya (y_test) dengan label yang diprediksi (y_pred). Hasil akurasi yang didapat adalah 1.0 atau 100%, menunjukkan bahwa model berhasil memprediksi semua data pengujian dengan benar. Selanjutnya, classification_report memberikan laporan detil mengenai performa model, termasuk presisi, recall, dan f1-score untuk setiap kelas label. Laporan ini menunjukkan bahwa model memiliki presisi, recall, dan f1-score sebesar 100% untuk kedua kelas label, yang berarti model melakukan prediksi dengan sempurna untuk dataset pengujian ini.
Visualisasi Confusion Matrix:


Kode tersebut bertujuan untuk memvisualisasikan confusion matrix dari hasil prediksi model klasifikasi. Fungsi confusion_matrix dari pustaka sklearn digunakan untuk menghasilkan matriks dari label sebenarnya (y_test) dan label yang diprediksi (y_pred). Matriks ini memberikan informasi tentang seberapa banyak observasi yang benar-benar diklasifikasikan dengan benar atau salah. Selanjutnya, menggunakan pustaka seaborn dan matplotlib, matriks tersebut divisualisasikan sebagai heatmap. Di dalam heatmap, angka-angka menunjukkan jumlah observasi untuk setiap kombinasi label sebenarnya dan label yang diprediksi. Dengan label sumbu y sebagai True label dan sumbu x sebagai Predicted label, visualisasi ini memberikan gambaran cepat tentang area di mana model mungkin membuat kesalahan dan seberapa sering kesalahan tersebut terjadi.
Validasi Silang:

Kode tersebut menggunakan teknik validasi silang (cross-validation) untuk mengevaluasi performa model klasifikasi di seluruh dataset. Menggunakan fungsi cross_val_score dari pustaka sklearn, dataset dibagi menjadi 5 fold (seperti ditentukan oleh parameter cv=5). Model klasifikasi (clf) kemudian dilatih dan dievaluasi 5 kali, setiap kali dengan fold yang berbeda sebagai set pengujian. Hasil dari kelima evaluasi tersebut disimpan dalam variabel scores. Hasil menunjukkan bahwa model memiliki akurasi 100% di setiap fold, yang ditunjukkan oleh nilai [1. 1. 1. 1. 1.]. Rata-rata dari skor ini juga 1.0 atau 100%, menegaskan bahwa model memiliki performa yang konsisten dan sempurna di seluruh dataset saat menggunakan teknik validasi silang.
Membuat DataFrame dari Hasil Prediksi:

Kode tersebut bertujuan untuk membuat DataFrame baru yang menampilkan label sebenarnya (y_test) dan label yang telah diprediksi oleh model (y_pred) untuk setiap observasi dalam data pengujian. Fungsi pd.DataFrame dari pustaka pandas digunakan untuk membuat DataFrame ini dengan dua kolom: True Labels yang menampilkan label sebenarnya dan Predicted Labels yang menampilkan label yang diprediksi. Ketika menampilkan lima baris pertama dari DataFrame ini menggunakan head(), dapat dilihat bahwa untuk setiap entri, label sebenarnya dan label yang diprediksi cocok, menunjukkan bahwa prediksi model sesuai dengan label sebenarnya dalam contoh-contoh tersebut.
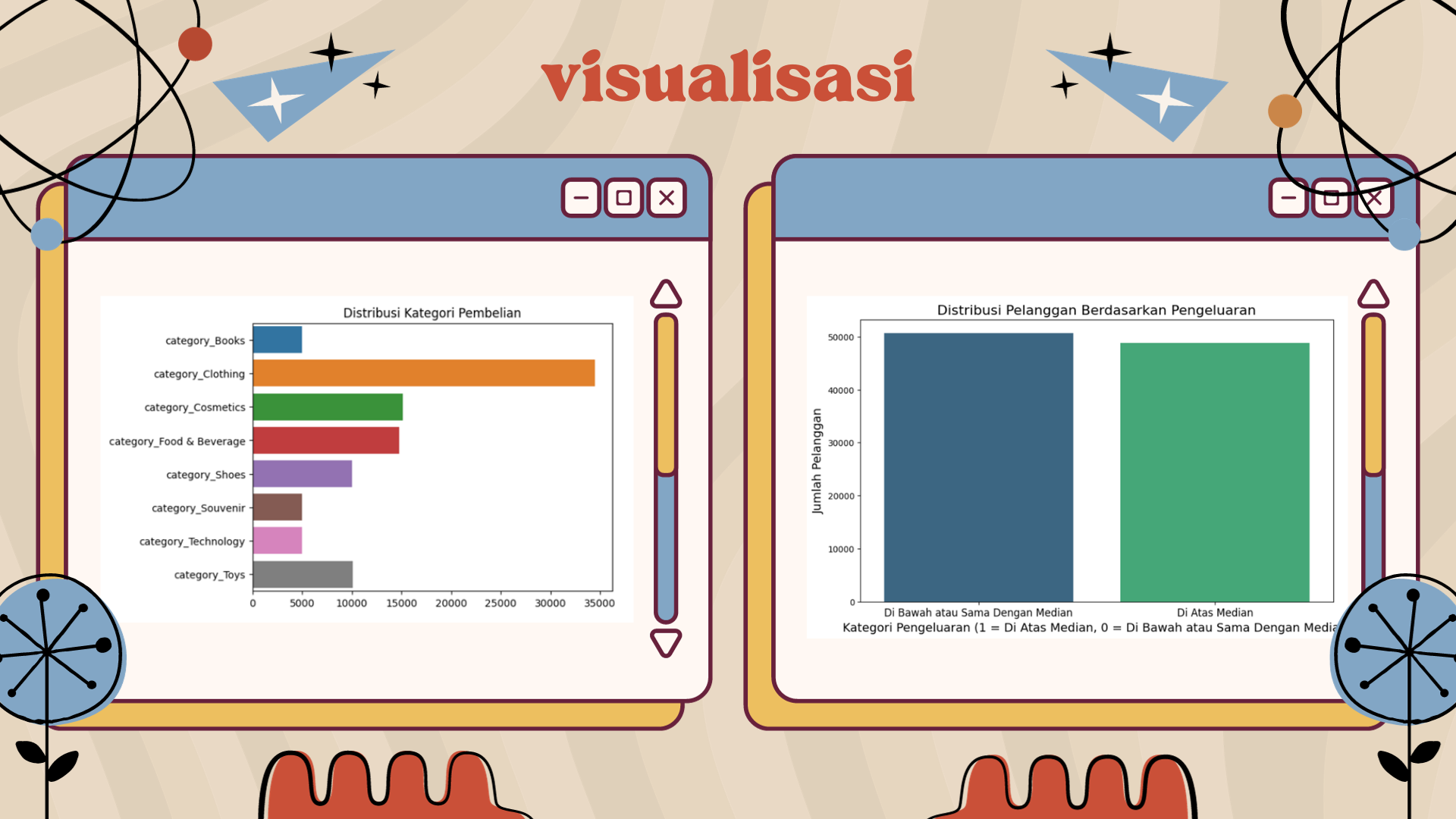
Visualisasi Distribusi Kategori Pembelian:


Kode tersebut dirancang untuk memvisualisasikan distribusi kategori pembelian dari dataset. Pertama-tama, daftar kolom yang berhubungan dengan kategori dibuat dengan mencari kolom yang namanya dimulai dengan category_ (hasil dari one-hot encoding). Kemudian, jumlah setiap kategori dihitung menggunakan metode sum() pada DataFrame. Selanjutnya, pustaka seaborn digunakan untuk membuat bar plot dengan kategori sebagai sumbu y dan jumlahnya sebagai sumbu x, memberikan gambaran visual mengenai seberapa sering setiap kategori muncul dalam dataset. Judul “Distribusi Kategori Pembelian” menambah konteks pada visualisasi tersebut.
Visualisasi Distribusi Pelanggan berdasaekan Pengeluaran:



Kode tersebut menggunakan pustaka seaborn dan matplotlib untuk memvisualisasikan distribusi pelanggan berdasarkan pengeluaran mereka. Pertama, kode menghitung jumlah pelanggan untuk setiap kategori pengeluaran dengan metode value_counts(). Selanjutnya, sebuah bar plot dibuat untuk menampilkan distribusi tersebut. Ukuran gambar disetel agar lebih besar agar lebih mudah dibaca. Bar plot menampilkan dua kategori pengeluaran: pelanggan yang menghabiskan di atas median (ditandai dengan angka 1) dan mereka yang menghabiskan di bawah atau sama dengan median (ditandai dengan angka 0). Warna bar diatur dengan palet viridis dan label sumbu, judul, serta tanda tick disesuaikan untuk meningkatkan keterbacaan visualisasi.
Kesimpulan
Dalam rangkaian proyek analitik ini, teknik machine learning digunakan untuk mengkategorisasikan pola pengeluaran pelanggan berdasarkan dataset yang komprehensif. Mengawali dengan pemrosesan data menggunakan library Pandas, proyek ini melakukan analisis eksploratif untuk memahami distribusi dan hubungan antar fitur dalam data. Fitur-fitur baru seperti total_spent dan is_high_spending dikembangkan untuk menangkap aspek-aspek tersembunyi dari perilaku pengeluaran. Melalui proses encoding yang cermat, data ini kemudian disiapkan untuk model klasifikasi Random Forest, yang dipilih karena ketahanannya terhadap overfitting dan efektivitasnya dalam mengelola dataset besar.
Evaluasi dari model klasifikasi ini dilakukan dengan teliti melalui penggunaan skor akurasi, laporan klasifikasi, dan matriks kebingungan, yang semuanya mengindikasikan presisi tinggi dalam prediksi model. Visualisasi data melalui matriks kebingungan dan plot batang memperjelas pemahaman akan kinerja model dan memberikan wawasan intuitif terhadap pola yang ada. Validasi silang menegaskan konsistensi dan keandalan model di berbagai sampel data. Hasil-hasil ini, yang ditunjukkan melalui skor akurasi sempurna, menegaskan kemampuan algoritma dalam membedakan tingkat pengeluaran pelanggan dengan efektif, menggarisbawahi pentingnya analitik prediktif dan machine learning untuk menggali kecerdasan bisnis yang dapat digunakan untuk strategi pemasaran yang lebih terfokus, manajemen inventaris yang lebih baik, dan pengalaman pelanggan yang ditingkatkan. Proyek ini menonjolkan aplikasi praktis dari data science dalam menginformasikan keputusan bisnis yang strategis.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Machine Learning For Beginner



