
Speech classification lagu Populer deep learning
Rahman Aulia Krisnapati



Summary
Sebuah sistem klasifikasi ucapan menggunakan jaringan saraf dalam hal ini akan memproses lagu-lagu populer dari The Weeknd untuk mengidentifikasi elemen-elemen penting dalam suara, seperti nada, ritme, dan tekstur vokal. Deep neural network akan belajar dari data suara untuk mengklasifikasikan lagu-lagu ini berdasarkan ciri-ciri yang ada, membantu dalam mengenali pola dan membedakan lagu-lagu berdasarkan gaya, genre, atau elemen lain yang diperlukan.
Description
Deskripsi Project
Proyek klasifikasi lagu menggunakan deep neural network melibatkan serangkaian langkah penting. Pertama, data lagu-lagu populer dari The Weeknd dikumpulkan dan dipersiapkan untuk analisis, termasuk normalisasi audio dan ekstraksi fitur-fitur seperti spektrum frekuensi dan pola waktu. Data kemudian dibagi menjadi set pelatihan, validasi, dan pengujian. Berikutnya, sebuah jaringan saraf yang sesuai dirancang, mungkin menggunakan arsitektur seperti Convolutional Neural Network (CNN) atau Recurrent Neural Network (RNN), yang akan dilatih menggunakan data pelatihan untuk mengklasifikasikan lagu berdasarkan fitur-fitur yang dikenali. Setelah melatih model, validasi menggunakan set data yang terpisah dilakukan untuk menyetel parameter dan mencegah overfitting. Evaluasi akhir dilakukan menggunakan set pengujian untuk mengukur kinerja model dalam mengidentifikasi dan mengklasifikasikan lagu-lagu. Hasil evaluasi membantu dalam mengevaluasi keefektifan model dan memungkinkan penyempurnaan lebih lanjut, memastikan klasifikasi yang lebih akurat dan efektif dari lagu-lagu populer The Weeknd.
Tujuan
Tujuan dari proyek klasifikasi lagu menggunakan deep neural network adalah untuk mengembangkan model yang dapat mengidentifikasi secara otomatis ciri-ciri unik dari lagu-lagu populer The Weeknd. Melalui analisis fitur-fitur audio, seperti melodi, ritme, dan karakteristik vokal, tujuan utamanya adalah memungkinkan sistem untuk mengklasifikasikan lagu-lagu ke dalam kategori atau genre yang tepat. Diharapkan bahwa model ini dapat digunakan untuk merekomendasikan lagu kepada pengguna berdasarkan preferensi mereka atau dapat diaplikasikan dalam platform streaming musik untuk meningkatkan pengalaman pengguna dengan menyajikan konten yang lebih relevan dan sesuai dengan selera mereka.
Kode Program dan Penjelasan
from scipy.io import wavfile: Ini adalah baris yang mengimpor modul wavfile dari library scipy.io. Modul ini memungkinkan kita untuk membaca file audio dalam format WAV.
import numpy as np: Di sini, kita mengimpor library numpy dengan alias np. numpy sering digunakan untuk manipulasi array dan operasi matematika di Python.
import matplotlib.pyplot as plt: Mengimpor matplotlib dengan alias plt, yang digunakan untuk membuat visualisasi grafik atau plot data.
import pywt: Ini adalah library pywt yang digunakan untuk melakukan transformasi wavelet, yaitu teknik untuk menganalisis data dalam domain waktu-frekuensi.
samplerate, data = wavfile.read('audiopopular.wav'): Baris ini membaca file audio WAV yang disimpan dalam file 'audiopopular.wav'. Hasil pembacaan audio disimpan dalam variabel data, sedangkan nilai sampling rate (frekuensi sampel) disimpan dalam variabel samplerate.
t = np.arange(len(data)) / float(samplerate): Baris ini menghasilkan nilai-nilai waktu yang sesuai untuk setiap sampel dalam data audio. np.arange(len(data)) menghasilkan array berurutan dari 0 hingga len(data) - 1, merepresentasikan jumlah sampel. Ini kemudian dibagi dengan nilai float(samplerate) untuk mendapatkan nilai waktu sesuai dengan frekuensi sampel.
print("data -> ", data): Ini adalah perintah untuk mencetak nilai-nilai dari data audio. Data audio direpresentasikan dalam bentuk array yang berisi amplitudo dari setiap sampel audio.
print("data length -> ", len(data)): Mencetak panjang data audio, yaitu jumlah sampel dalam file audio tersebut.
print("np.arange(len(data)) -> ", np.arange(len(data))): Menampilkan array yang merepresentasikan indeks dari setiap sampel audio dari 0 hingga panjang data audio - 1.
print("float(samplerate) -> ", float(samplerate)): Mencetak nilai dari frekuensi sampel (sampling rate) dalam bentuk floating point.
print("time -> ", t): Menampilkan array yang berisi nilai waktu yang sesuai dengan setiap sampel audio, dihitung berdasarkan frekuensi sampel.
cA, cD = pywt.dwt(data, 'bior6.8', 'per'): Baris ini melakukan Discrete Wavelet Transform (DWT) terhadap data audio (data) menggunakan wavelet bior6.8 dengan mode 'periodization'. Hasil transformasi terbagi menjadi dua bagian: cA (approximation coefficients) dan cD (detail coefficients).
y = pywt.idwt(cA, cD, 'bior6.8', 'per'): Kode ini melakukan Inverse Discrete Wavelet Transform (IDWT) dari cA dan cD yang telah dihasilkan sebelumnya menggunakan wavelet yang sama (bior6.8) dan mode 'periodization'. Hasil dari inversi ini disimpan dalam variabel y.
wavfile.write('sampleR.wav', samplerate, y): Baris ini menyimpan hasil dari IDWT ke dalam file audio baru dengan nama 'sampleR.wav'. Proses ini menghasilkan file audio dari data yang sudah diterapkan transformasi wavelet dan kemudian dikembalikan ke domain waktu.
wavfile.write('samplecD.wav', samplerate, cD): Kode ini menyimpan detail coefficients (cD) dari DWT ke dalam file 'samplecD.wav'. Detail coefficients merepresentasikan komponen tingkat detail dari data setelah proses DWT.
wavfile.write('samplecA', samplerate, cA): Baris ini menyimpan approximation coefficients (cA) dari DWT ke dalam file 'samplecA.wav'. Approximation coefficients merepresentasikan komponen tingkat aproksimasi dari data setelah proses DWT.

L = len(data); y = y[0:L];: Di sini, kita membuat variabel L yang menyimpan panjang data asli (data). Kemudian, kita memastikan panjang sinyal yang direkonstruksi (y) sesuai dengan panjang data asli dengan mengambil bagian dari y yang sepanjang data asli. Ini dilakukan agar kedua sinyal memiliki panjang yang sama untuk keperluan plotting.
plt.figure(figsize=(30, 20)): Membuat sebuah figure (gambar) untuk plot dengan ukuran 30x20 inch.
plt.subplot(4, 1, 1), plt.subplot(4, 1, 2), dst.: Baris-baris ini menentukan subplot-subplot di dalam gambar yang dibuat sebelumnya. Pada gambar dengan ukuran 30x20 inch, akan ada 4 subplot dalam kolom, dan 1 baris (4 baris secara vertikal).
plt.plot(t, data, color='k'): Memplot data audio asli (data) dalam domain waktu pada subplot pertama. Warna plot diatur sebagai hitam ('k').
plt.plot(cA, color='r'): Memplot approximation coefficients (cA) dari hasil DWT pada subplot kedua. Warna plot diatur sebagai merah ('r').
plt.plot(cD, color='g'): Memplot detail coefficients (cD) dari hasil DWT pada subplot ketiga. Warna plot diatur sebagai hijau ('g').
plt.plot(t, y, color='b'): Memplot sinyal yang direkonstruksi (y) setelah proses IDWT pada subplot keempat. Warna plot diatur sebagai biru ('b').
plt.savefig('plot.png', dpi=100): Menyimpan gambar plot tersebut dalam format PNG dengan nama file 'plot.png' dan resolusi 100 dpi.
plt.show(): Menampilkan gambar plot secara interaktif atau dalam output.
samplerate, data = wavfile.read('audiopopular.wav'): Baris ini membaca file audio WAV yang disimpan dalam file 'audiopopular.wav'. Hasil pembacaan audio disimpan dalam variabel data, sedangkan nilai sampling rate (frekuensi sampel) disimpan dalam variabel samplerate.
t = np.arange(len(data)) / float(samplerate): Baris ini menghasilkan nilai-nilai waktu yang sesuai untuk setiap sampel dalam data audio. np.arange(len(data)) menghasilkan array berurutan dari 0 hingga len(data) - 1, merepresentasikan jumlah sampel. Ini kemudian dibagi dengan nilai float(samplerate) untuk mendapatkan nilai waktu sesuai dengan frekuensi sampel.
coeffs = pywt.wavedec(data, 'bior6.8', mode='sym', level=2): Kode ini melakukan Discrete Wavelet Transform (DWT) pada data audio (data) menggunakan wavelet bior6.8 dengan mode 'symmetric' dan tingkat dekomposisi sebanyak 2 tingkat. Hasil transformasi terbagi menjadi cA2, cD2, dan cD1 yang merupakan approximation coefficients tingkat kedua, serta detail coefficients tingkat kedua dan pertama.
y = pywt.waverec(coeffs, 'bior6.8', mode='sym'): Baris ini melakukan Inverse Discrete Wavelet Transform (IDWT) dari koefisien yang dihasilkan sebelumnya (coeffs) menggunakan wavelet yang sama (bior6.8) dan mode 'symmetric'. Hasil dari inversi ini disimpan dalam variabel y.
wavfile.write('sampleR.wav', samplerate, y): Menyimpan hasil dari IDWT ke dalam file audio baru dengan nama 'sampleR.wav'. Proses ini menghasilkan file audio dari data yang sudah diterapkan transformasi wavelet dan kemudian dikembalikan ke domain waktu.
wavfile.write('samplecA2.wav', samplerate, cA2), wavfile.write('samplecD2.wav', samplerate, cD2), wavfile.write('samplecD1.wav', samplerate, cD1): Kode ini menyimpan approximation coefficients (cA2), detail coefficients tingkat kedua (cD2), dan detail coefficients tingkat pertama (cD1) dari DWT ke dalam file audio terpisah.
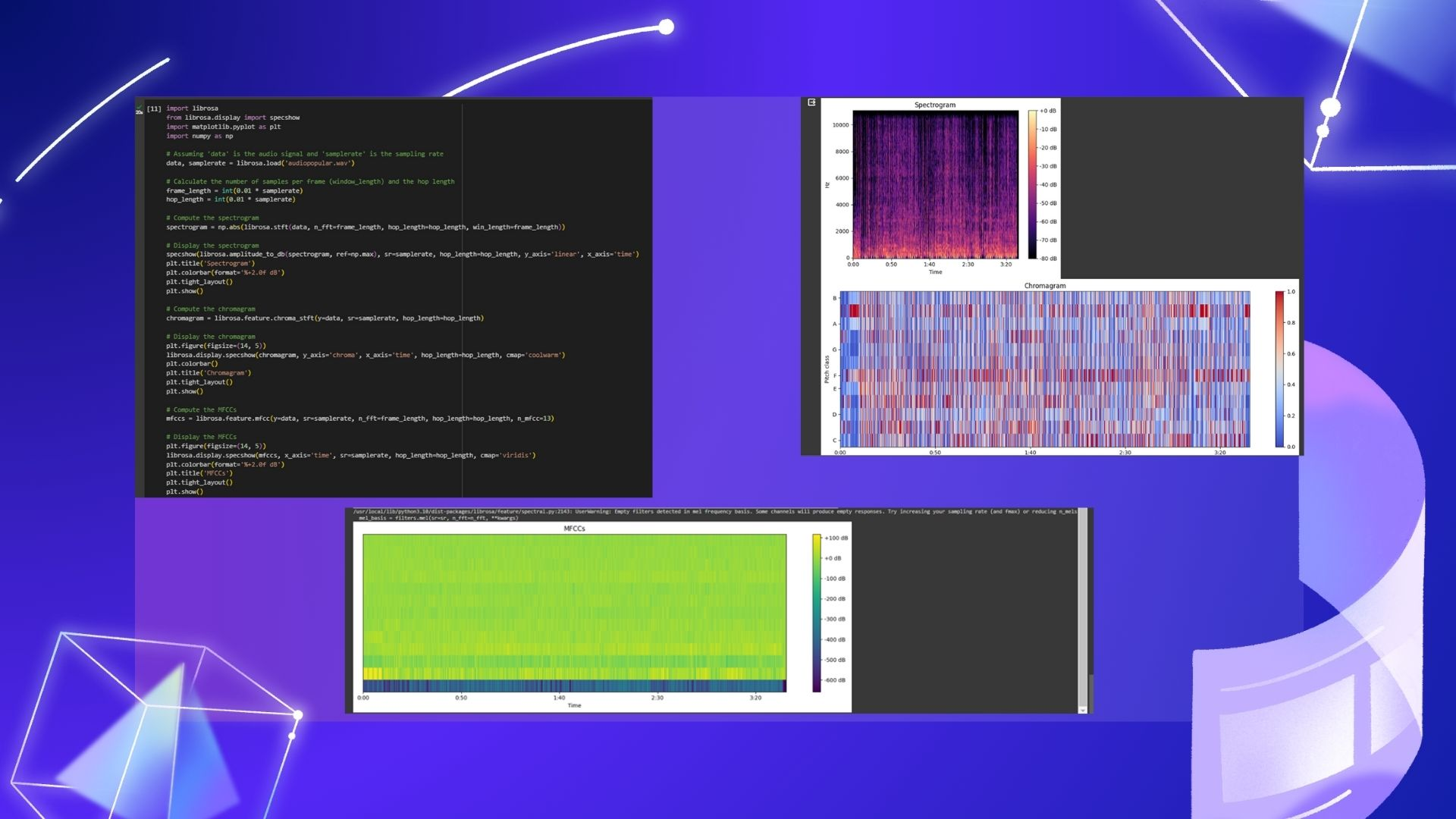
Memuat dan Menganalisis Audio:
- Menggunakan librosa.load() untuk memuat file audio.
- Menghitung frame length dan hop length untuk analisis.
Spectrogram:
- Menggunakan Short-time Fourier Transform (STFT) untuk representasi frekuensi dari audio.
Chromagram:
- Menghitung chroma dari sinyal audio menggunakan STFT.
Mel-frequency Cepstral Coefficients (MFCCs):
- Menghitung MFCCs untuk merepresentasikan karakteristik spektral audio.
Visualisasi Representasi Audio:
- Menampilkan spektrogram, chromagram, dan MFCCs dalam bentuk grafik untuk masing-masing analisis.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Speech Classification Menggunakan Deep Neural Network
