
Klasifikasi Jenis Kaca dengan Machine Learning
Angelia

Summary
Ini adalah Klasifikasi Jenis Kaca dengan Machine Learning yang melibatkan penggunaan Jupyter Notebook. Dengan tujuan untuk mengembangkan model pembelajaran mesin yang mampu mengklasifikasikan jenis kaca secara akurat. Tugas klasifikasi melibatkan pelatihan model pada kumpulan data yang berisi fitur-fitur yang terkait dengan berbagai jenis kaca dan menggunakannya untuk memprediksi jenis kaca berdasarkan data masukan baru.
Description
Pada portofolio ini saya menggunakan dataset yang saya ambil dari Kaggle di sini
- Load Library
Mari mulai dengan memuat library yang akan digunakan pada Jupyter Notebook
- Load dan Explore Bentuk Dataset
Dataset terdiri dari 214 observasi
- Merangkum Data
- Statistik deskriptif
Mari rangkum dulu distribusi variabel numeriknya.
Fitur-fiturnya tidak berada pada skala yang sama. Misalnya Si memiliki nilai mean sebesar 72,65 sedangkan Fe memiliki nilai mean sebesar 0,057. Fitur harus berada pada skala yang sama agar algoritme seperti regresi logistik (penurunan gradien) dapat menyatu dengan lancar. Mari periksa distribusi jenis kacanya.
Kumpulan datanya sangat tidak seimbang. Contoh tipe 1 dan 2 mencakup lebih dari 67 % tipe kaca - Data visualization
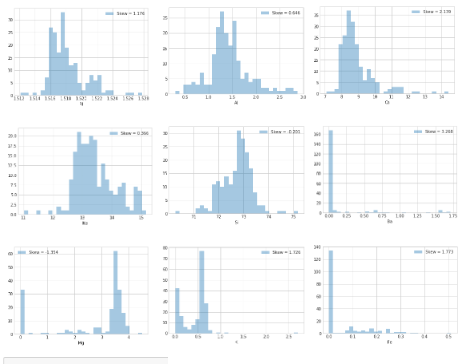
- Plot univariat
Tidak ada satu pun fitur yang terdistribusi secara normal. Fitur Fe, Ba, Ca dan K menunjukkan koefisien kemiringan tertinggi. Selain itu, sebaran Kalium (K) dan Barium (Ba) nampaknya banyak mengandung outlier. Mari identifikasi indeks observasi yang mengandung outlier menggunakan Turkey's method.
Terdapat sekitar 14 observasi dengan banyak outlier. Hal ini dapat membahayakan efisiensi algoritma pembelajaran. Selanjutnya adalah memastikan untuk menghilangkannya di bagian berikutnya.
Mari periksa diagram kotak untuk beberapa distribusi.
Silikon memiliki nilai rata-rata yang jauh lebih unggul dibandingkan konstituen lainnya seperti yang telah dilihat di bagian sebelumnya. Itu normal karena bahan dasar kaca sebagian besar adalah silika. - Multivariate plots
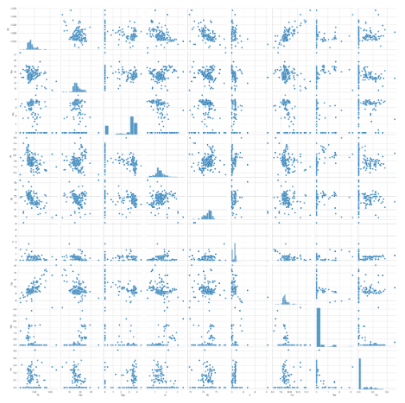
Sekarang mari lanjutkan dengan menggambar plot berpasangan untuk memeriksa secara visual korelasi antar fitur.
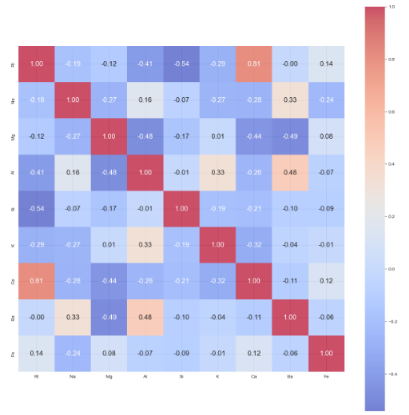
Mari lanjutkan dan periksa korelasinya dengan heatmap.
Tampaknya ada korelasi positif yang kuat antara RI dan Ca. Ini bisa menjadi petunjuk untuk melakukan analisis komponen Utama untuk mendekorelasi beberapa fitur masukan.
- Plot univariat
- Statistik deskriptif
- Prepare Data
- Pembersihan Data

Dataset ini bersih dan tidak ada nilai yang hilang di dalamnya. - Mencaridan menghilangkan banyak outlier
Mari hilangkan pengamatan yang mengandung banyak outlier dengan fungsi yang buat di bagian sebelumnya.
Menghapus observasi dengan banyak outlier (lebih dari 2) memberi 200 observasi untuk dipelajari. Sekarang mari lihat seperti apa distribusinya.
- Pembersihan Data
- Kumpulan data dengan validasi terpisah

- Transformasi data
Mari periksa apakah transformasi Box-Cox dapat berkontribusi pada normalisasi beberapa fitur. Perlu ditekankan bahwa semua transformasi hanya boleh dilakukan pada set pelatihan untuk menghindari pengintaian data. Jika tidak, estimasi kesalahan pengujian akan menjadi bias.































Transformasi Box-Cox tampaknya berhasil mengurangi ketimpangan distribusi fitur yang berbeda. Namun, hal ini tidak mengarah pada normalisasi distribusi fitur. Trial and error menunjukkan bahwa hal tersebut tidak membawa pada peningkatan kinerja algoritma yang digunakan. Selanjutnya, mari jelajahi teknik reduksi dimensi.

- Evaluasi Algoritma
- Pengurangan dimensi
- XGBoost
Tampaknya tidak ada fitur utama yang mendominasi pentingnya masalah dalam pemodelan XGBoost. - PCA
Mari lanjutkan dan lakukan PCA pada fitur-fitur untuk mendekorelasi fitur-fitur yang bergantung linier dan kemudian mari memplot varians yang dijelaskan secara kumulatif.
Tampaknya sekitar 99% varians dapat dijelaskan dengan 5 komponen utama pertama. Namun memasukkan fitur PCA ke algoritma pembelajaran tidak memberikan kontribusi pada kinerja yang lebih baik. Hal ini mungkin disebabkan oleh non-linear yang tidak dapat ditangkap oleh PCA.
- XGBoost
- Pengurangan dimensi
- Membandingkan Algoritma
Sekarang saatnya membandingkan performa berbagai algoritma Machine Learning. Saya akan menggunakan validasi silang 10 kali lipat untuk menilai kinerja setiap model dengan metrik sebagai akurasi klasifikasi. Pipeline yang mencakup Standarisasi dan PCA digunakan untuk menghindari kebocoran data. Standarisasi tidak dilakukan untuk tree-based methods.
Hasil pengamatan: Performa terbaik diraih oleh RF. Namun, RF juga menghasilkan distribusi yang luas. Layak untuk melanjutkan penelitian dengan menyetel RF.
Regresi Logistik berkinerja buruk. Hal ini mungkin disebabkan oleh fakta bahwa data tidak terdistribusi secara normal karena algoritma ini bekerja dengan baik ketika data terdistribusi secara normal.
- Meningkatkan Akurasi
- Penyetelan Algoritma
- Tuning Random Forests
Untuk hutan acak, kita dapat menyetel jumlah pohon yang tumbuh (n_estimators), kedalaman pohon (maks_kedalaman), kriteria pemisahan (gini atau entropi) dan seterusnya.... Mari kita mulai menyetelnya.
- Tuning Random Forests
- Penyetelan Algoritma
- Diagnosis Kinerja Algoritma Terbaik
- Diagnosis overfitting dengan memplot kurva pembelajaran dan validasi
- Penyetelan lebih lanjut







Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Machine Learning For Beginner

