
Klasifikasi Dataset Titanic Dengan Random Forest
Nadhira Jasmine Nurrahma


Summary
Deskripsi
Dataset ini berisi informasi berupa data penumpang dari kapal RMS Titanic yang mencakup aspek-aspek seperti identitas penumpang (PassengerId), status kelangsungan hidup (Survived), kelas tiket (Pclass), nama (Name), jenis kelamin (Sex), umur (Age), jumlah saudara kandung atau pasangan (SibSp), jumlah orang tua atau anak (Parch), nomor tiket (Ticket), tarif tiket (Fare), nomor kabin (Cabin), dan pelabuhan keberangkatan (Embarked). Dataset ini digunakan untuk menganalisis hubungan antara karakteristik penumpang dan peluang kelangsungan hidup, serta untuk menguji menggunakan metode klasifikasi dalam machine learning dan data science.
Tujuan dan Manfaat
Klasifikasi ini bertujuan untuk memprediksi kelangsungan hidup penumpang berdasarkan berbagai faktor seperti umur, jenis kelamin, dan kelas tiket menggunakan teknik-teknik machine learning. Manfaat utamanya adalah meningkatkan pemahaman tentang teknik analisis data dan machine learning, serta memberikan wawasan tentang faktor-faktor yang mempengaruhi keselamatan dalam situasi bencana.
Description
Pengertian Random Forest
Random Forest adalah algoritma machine learning yang termasuk dalam kategori ensemble learning. Algoritma ini bekerja dengan cara menggabungkan sejumlah besar pohon keputusan (decision trees) untuk menghasilkan hasil yang lebih akurat dan stabil. Setiap pohon dalam 'hutan' dibangun dari sampel data yang diambil secara acak dari dataset dan pada akhir proses, output dari semua pohon digabungkan untuk memberikan prediksi akhir. Keunggulan Random Forest adalah dapat mengurangi overfitting yang biasanya terjadi pada model pohon keputusan tunggal dan memiliki kinerja yang baik pada dataset yang besar dan kompleks. Algoritma ini efektif dalam berbagai jenis tugas prediktif, klasifikasi maupun regresi.
Penggunaan Dataset
Dataset yang digunakan pada klasifikasi data ini adalah data Titanic yang bersumber pada link ini : https://www.kaggle.com/datasets/brendan45774/test-file.
Pada dataset tested.csv ini terdapat attribut yaitu, PassengerId: ID untuk setiap penumpang, Survived: Menandakan apakah penumpang selamat (1) atau tidak (0), Pclass: Kelas kabin penumpang (1, 2, atau 3), Name: Nama penumpang, Sex: Jenis kelamin penumpang, Age: Usia penumpang, SibSp: Jumlah saudara kandung atau pasangan di kapal, Parch: Jumlah orangtua atau anak di kapal, Ticket: Nomor tiket penumpang, Fare: Tarif yang dibayar oleh penumpang, Cabin: Nomor kabin penumpang, Embarked: Pelabuhan keberangkatan (C = Cherbourg; Q = Queenstown; S = Southampton), survival_category: Kategori yang menandakan apakah penumpang 'Selamat' atau 'Tidak Selamat', yang kita buat berdasarkan kolom Survived.
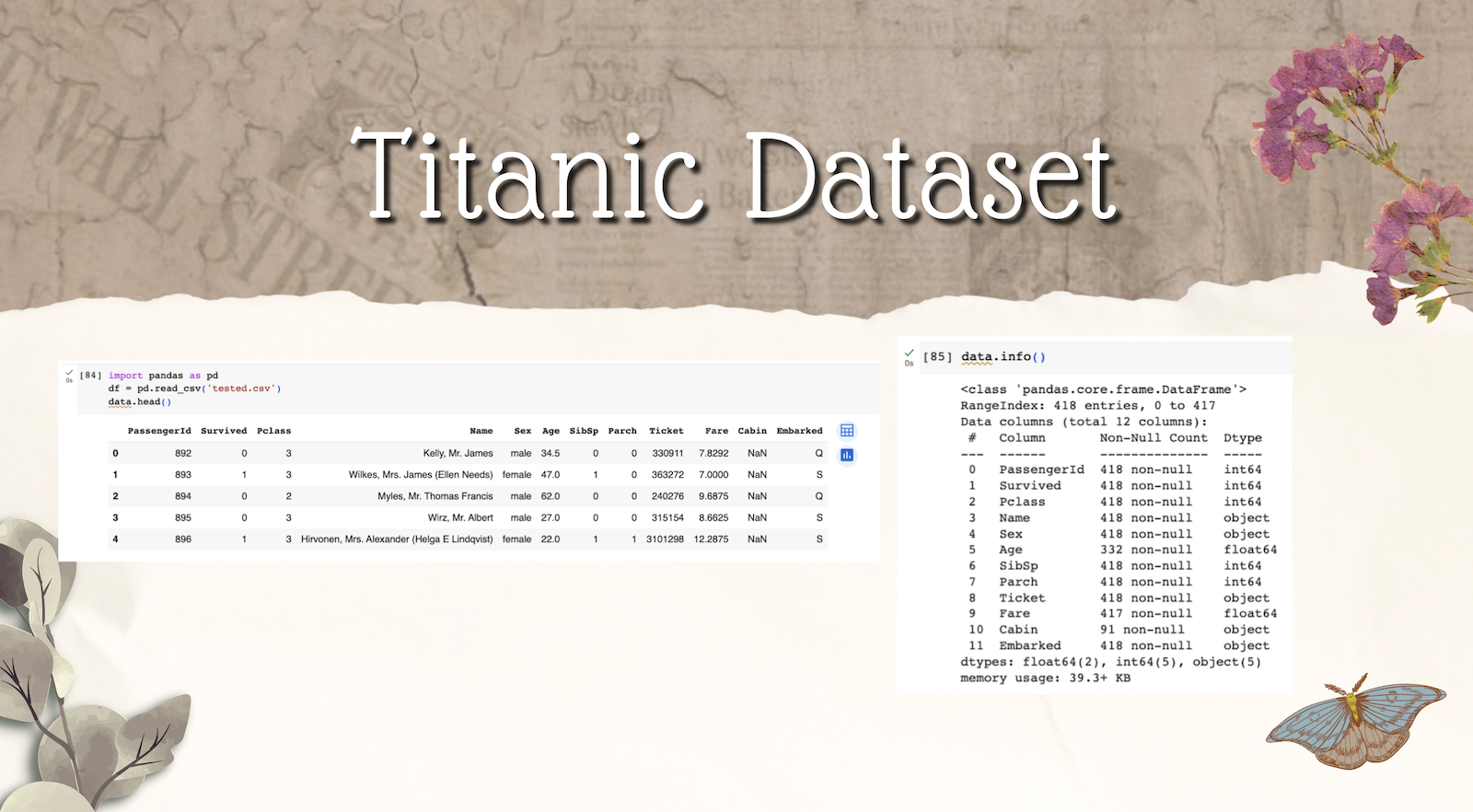
1. Import Library Untuk Memuat Dan Menampilkan Dataset

Langkah pertama ‘pandas’ diimport dan digunakan untuk memuat dataset dari file csv ‘tested.csv’ ke dalam DataFrame ‘data’ dan ‘data.head()’, untuk menampilkan lima baris pertama dari dataset.
2. Menampilkan Informasi Data dan Mengimport Pustaka

Terdapat data.info() untuk melihat informasi tentang dataset, termasuk jumlah kolom, baris, tipe data untuk setiap kolom, dan jumlah nilai yang hilang.

Selanjutnya, mengimpor fungsi train_test_split untuk membagi dataset menjadi set latihan dan pengujian, mengimpor RandomForestClassifier, sebuah algoritma klasifikasi, mengimpor metrics evaluasi accuracy_score, classification_report, dan confusion_matrix untuk menilai kinerja model dan mengimpor matplotlib dan seaborn untuk visualisasi.
3. Membuat Kolom Kategori Keselamatan

Menggunakan kolom Survived untuk membuat kolom baru kategori_keselamatan. Jika penumpang selamat (Survived = 1), kolom tersebut akan berisi 'Selamat'. Jika tidak, maka akan berisi 'Tidak Selamat'.
4. Mengisi Nilai Yang Hilang

Mengisi nilai yang hilang pada kolom ‘Age’ dan ‘Fare’ dengan nilai median dari masing-masing kolom. Fungsi fillna digunakan untuk mengisi nilai yang hilang dan parameter inplace=True untuk memastikan bahwa perubahan diterapkan langsung ke DataFrame.
5. Pemisahan Data Pelatihan Dan Pengujian

Menentukan fitur yang akan digunakan untuk klasifikasi yaitu ‘Pclass’, ‘Age’, ‘SibSp’, ‘Parch’, Fare’. Kemudian, membagi data menjadi fitur (X) dan target (y). Selanjutnya, menggunakan train_test_split untuk membagi data menjadi set latihan dan pengujian.
6. Pelatihan Model Klasifikasi

Membuat instance dari RandomForestClassifier yang diinisialisasi dengan ‘random_state’ dan dilatih dengan set data latihan.
7. Prediksi dan Evaluasi Model

Setelah model telah dilatih menggunakan model untuk memprediksi label dari data uji (X_uji). accuracy_score(y_uji, y_prediksi) digunakan untuk menghitung akurasi dari prediksi dengan membandingkan label sebenarnya (y_uji) dan label yang diprediksi (y_prediksi). Sehingga laporan_klasifikasi = classification_report(y_uji, y_prediksi) yang akan menghasilkan laporan klasifikasi yang terdiri presisi, recall, support dan skor F1 untuk setiap kelas. Print untuk menampilkan hasil akurasi dan laporan klasifikasi.
8. Visualisasi Confusion Matrix

Matriks Confusion menampilkan representasi visualisasi kinerja model. Matriks ini menampilkan jumlah prediksi selamat untuk setiap kelas. plt.figure(figsize=(8, 6)) menentukan ukuran gambar untuk visualisasi dan sns.heatmap(...) menggunakan Seaborn untuk membuat visualisasi heatmap dari matriks confusion. annot=True menampilkan angka di dalam setiap sel heatmap. fmt='g' memformat angka di dalam sel heatmap. cmap='Blues' memberikan warna heatmap. xticklabels dan yticklabels menentukan label sumbu x dan y untuk heatmap. Berdasarkan data diatas hasilnya yaitu, Bagian kiri atas: True Positive (TP) ada 12 orang berarti Penumpang yang sebenarnya selamat dan model memprediksi mereka selamat. Bagian kanan atas: False Negative (FN) ada 22 orang berarti Penumpang yang sebenarnya selamat tetapi model memprediksi mereka tidak selamat. Bagian kiri bawah: False Positive (FP) ada 12 orang berarti Penumpang yang sebenarnya tidak selamat tetapi model memprediksi mereka selamat. Bagian kanan bawah: True Negative (TN) ada 38 orang berarti Penumpang yang sebenarnya tidak selamat dan model memprediksi mereka tidak selamat.
9. Membuat DataFrame Hasil Prediksi

Bertujuan untuk membuat DataFrame baru yang menampilkan label sebenarnya (y_test) dan label yang telah diprediksi oleh model (y_pred) untuk observasi data pengujian. Fungsi pd.DataFrame dari pustaka pandas untuk membuat DataFrame ini dengan dua kolom: True Labels yang menampilkan label sebenarnya dan Predicted Labels yang menampilkan label yang diprediksi.
10. Visualisasi Data Penumpang Berdasarkan Keselamatan


Pada pengklasifikasian kategori keselamatan, terdapat sns.countplot berfungsi dari pustaka visualisasi data Seaborn untuk membuat bar plot. Parameter x="kategori_keselamatan" menunjukkan menghitung dan memvisualisasikan distribusi berdasarkan kolom "kategori_keselamatan". Parameter data=df menampilkan sumber data untuk visualisasi berasal dari DataFrame df. palette="deep" menentukan warna yang digunakan pada bar plot. plt.title("Distribusi Penumpang Berdasarkan Keselamatan") untuk memberikan judul grafik dan plt.xlabel("Kategori Keselamatan") dan plt.ylabel("Jumlah Penumpang" berfungsi untuk memberikan label pada sumbu x dan y grafik. Sumbu x menunjukkan kategori keselamatan (apakah penumpang selamat atau tidak), sementara sumbu y menunjukkan jumlah penumpang dalam setiap kategori tersebut. plt.show() menampilkan grafik yang telah dibuat. Sehingga, pada visualisasi distribusi penumpang berdasarkan keselamatan menunjukan hasil lebih banyak yang ‘Tidak Selamat’ dengan jumlah penumpang 250 lebih dan yang ‘Selamat’ hanya 150 orang.
Kesimpulan
Dataset Titanic bersumber dari Kaggle untuk klasifikasi data, melibatkan atribut kunci seperti ID penumpang, status kelangsungan hidup, kelas kabin, nama, jenis kelamin, usia, jumlah saudara kandung atau pasangan, jumlah orangtua atau anak, nomor tiket, tarif, nomor kabin, dan pelabuhan keberangkatan. Proses analisisnya dimulai dengan import dan tampilan data menggunakan pandas, dilanjutkan dengan menampilkan informasi dataset dan mengimport pustaka yang relevan. Kemudian, dilakukan pembuatan kolom 'kategori_keselamatan' dari kolom 'Survived' dan pengisian nilai yang hilang pada kolom 'Age' dan 'Fare'. Proses selanjutnya adalah pemisahan data menjadi set pelatihan dan pengujian, menentukan fitur untuk klasifikasi, dan pelatihan model menggunakan RandomForestClassifier. Model berhasil mencapai akurasi sekitar 59.52%, dengan visualisasi Confusion Matrix dan bar plot yang memberikan insight distribusi prediksi keselamatan penumpang. Tahap evaluasi meliputi prediksi dan penghitungan akurasi model, pembuatan laporan klasifikasi, dan visualisasi hasil melalui Confusion Matrix dan DataFrame hasil prediksi. Selain itu, dilakukan visualisasi distribusi penumpang berdasarkan keselamatan, menunjukkan dominasi penumpang yang 'Tidak Selamat' dibandingkan dengan yang 'Selamat'. Sehingga pada klasifikasi ini memberikan gambaran terkait proses analisis data yang meliputi semua aspek dari pengolahan data, pelatihan model, evaluasi, hingga visualisasi hasil.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Machine Learning For Beginner



