
Klasifikasi Rating Netflix dengan Random Forest
Rasya Alya Trismia


Summary
Menjelaskan tentang klasifikasi rating Netflix menggunakan algoritma Random Forest. Dataset yang digunakan berisi data dari acara TV dan film Netflix, termasuk informasi seperti judul, tipe konten, deskripsi, tahun rilis, sertifikasi usia, durasi, genre, negara produksi, skor IMDb, dan popularitas di TMDb. Klasifikasi dilakukan dengan memproses kolom 'imdb_score' untuk menghasilkan kategori rating baru. Data dibagi menjadi set pelatihan dan pengujian, dengan 80% data untuk pelatihan. Model Random Forest dilatih dan dievaluasi, menunjukkan akurasi tinggi sekitar 96.15%. Analisis termasuk pembuatan confusion matrix dan grafik distribusi kategori rating. Hasil ini memberikan wawasan mendalam tentang kinerja dan potensi model dalam klasifikasi konten Netflix.
Description
Pengertian Random Forest
Random Forest adalah algoritma machine learning yang efektif dan serbaguna, digunakan untuk tugas-tugas klasifikasi dan regresi. Ini merupakan metode ensemble yang menggabungkan beberapa pohon keputusan (decision trees) untuk menghasilkan hasil yang lebih stabil dan akurat. Setiap pohon dalam ‘forest’ dibuat dari sampel data yang dipilih secara acak, dan keputusan akhir diambil berdasarkan mayoritas suara dari semua pohon. Ini mengurangi risiko overfitting yang sering terjadi pada pohon keputusan tunggal. Algoritma ini juga penting dalam menangani data yang besar dan kompleks, memberikan wawasan yang baik mengenai fitur penting dan bagaimana mereka mempengaruhi hasil prediksi.
Dataset yang digunakan
Dataset yang digunakan pada klasifikasi data ini adalah data Netflix TV Shows and Movies (July, 2022). Dataset ini berisi informasi tentang berbagai judul acara TV dan film yang tersedia di Netflix. Berikut adalah kolom yang terdapat dalam dataset ini:
- “id”: ID unik untuk setiap judul.
- “title”: Judul dari acara TV atau film.
- “type”: Tipe konten, apakah itu acara TV (“SHOW”) atau film (“MOVIE”).
- “description”: Deskripsi dari acara TV atau film.
- “release_year”: Tahun rilis dari acara TV atau film.
- “age_certification”: Sertifikasi usia untuk acara TV atau film.
- “runtime”: Durasi dari acara TV atau film dalam menit.
- “genres”: Genre dari acara TV atau film, diberikan dalam format list.
- “production_countries”: Negara-negara di mana acara TV atau film diproduksi, diberikan dalam format list.
- “seasons”: Jumlah musim yang tersedia untuk acara TV.
- “imdb_id”: ID dari acara TV atau film di situs IMDb.
- “imdb_score”: Skor rating IMDb untuk acara TV atau film.
- “imdb_votes”: Jumlah suara yang diterima acara TV atau film di IMDb.
- “tmdb_popularity”: Popularitas acara TV atau film di situs TMDb (The Movie Database).
- “tmdb_score”: Skor rating TMDb untuk acara TV atau film.
Untuk klasifikasi rating Netflix menggunakan Random Forest dalam proyek ini, kolom ‘imdb_score’ menjadi fitur utama, di mana nilai skor IMDb digunakan untuk mengklasifikasikan konten menjadi kategori rating yang berbeda. Dataset ini dapat diakses pada link https://www.kaggle.com/datasets/victorsoeiro/netflix-tv-shows-and-movies
Langkah-langkah klasifikasi data menggunakan Random Forest:
Mengimpor library dan memuat dataset

Pustaka ‘pandas’ diimpor dan digunakan untuk memuat dataset dari file CSV bernama ‘titles.csv’ ke dalam DataFrame yang disebut ‘data’. Dengan menggunakan ‘data.head()’, lima baris pertama dari dataset ditampilkan.
Informasi data

Dengan menggunakan fungsi ‘info()’, diberikan ringkasan tentang dataset, termasuk jumlah baris, tipe data untuk setiap kolom, dan informasi tentang nilai yang hilang.
Pembuatan kolom target

Dengan menggunakan fungsi ‘apply()’, kolom ‘imdb_score’ diproses untuk menghasilkan kolom target baru yang bernama ‘rating_category’. Setiap nilai dalam ‘imdb_score’ dievaluasi; jika lebih dari 6.5, maka dikategorikan sebagai ‘High Rating’, jika tidak, maka ‘Low Rating’.
Pengisian nilai yang hilang

Nilai yang hilang pada kolom ‘release_year’, ‘runtime’, dan ‘imdb_score’ diisi dengan nilai median dari masing-masing kolom. Fungsi ‘fillna()’ digunakan untuk mengisi nilai yang hilang, dan argumen ‘inplace=True’ memastikan perubahan disimpan ke DataFrame.
Pemisahan fitur dan target

Fitur yang akan digunakan untuk klasifikasi dipilih, yaitu ‘release_year’, ‘runtime’, dan ‘imdb_score’. Variabel ‘X’ akan menyimpan fitur, sementara variabel ‘y’ menyimpan target.
Pembagian data pelatihan dan pengujian

Dengan menggunakan fungsi ‘train_test_split’, data dibagi menjadi set pelatihan dan pengujian. Sebanyak 80% data digunakan untuk pelatihan, sementara sisanya (20%) untuk pengujian.
Pelatihan model

Model klasifikasi Random Forest diinisialisasi dengan parameter ‘random_state’ yang ditetapkan ke 42 untuk reproducibility. Model kemudian dilatih dengan set pelatihan.
Prediksi dan evaluasi model

Setelah pelatihan, model digunakan untuk membuat prediksi pada set pengujian. Kemudian, akurasi dari prediksi dihitung dan laporan klasifikasi dicetak, yang mencakup metrik seperti precision, recall, F1-score, dan support. Akurasi yang didapatkan adalah sekitar 96.15%, menunjukkan bahwa model memiliki kemampuan prediksi yang tinggi. Precision atau presisi mengukur proporsi prediksi positif yang benar-benar adalah hasil positif sebenarnya. Dengan kata lain, dari semua item yang diklasifikasikan sebagai positif, berapa banyak yang benar-benar positif. Recall mengukur proporsi hasil positif sebenarnya yang berhasil diidentifikasi dengan benar oleh model. F1-score adalah rata-rata harmonik dari presisi dan recall. Karena merupakan rata-rata harmonik, F1-score memberikan bobot yang lebih rendah untuk nilai yang lebih rendah. Jadi, jika salah satu (presisi atau recall) bernilai rendah, F1-score akan mengambil nilai yang lebih rendah. Ini memastikan bahwa model hanya akan mendapatkan skor F1 yang tinggi jika kedua presisi dan recallnya tinggi. Sedangkan Support adalah jumlah sebenarnya dari kelas tertentu dalam set data (baik positif maupun negatif).
Visualisasi confusion matrix


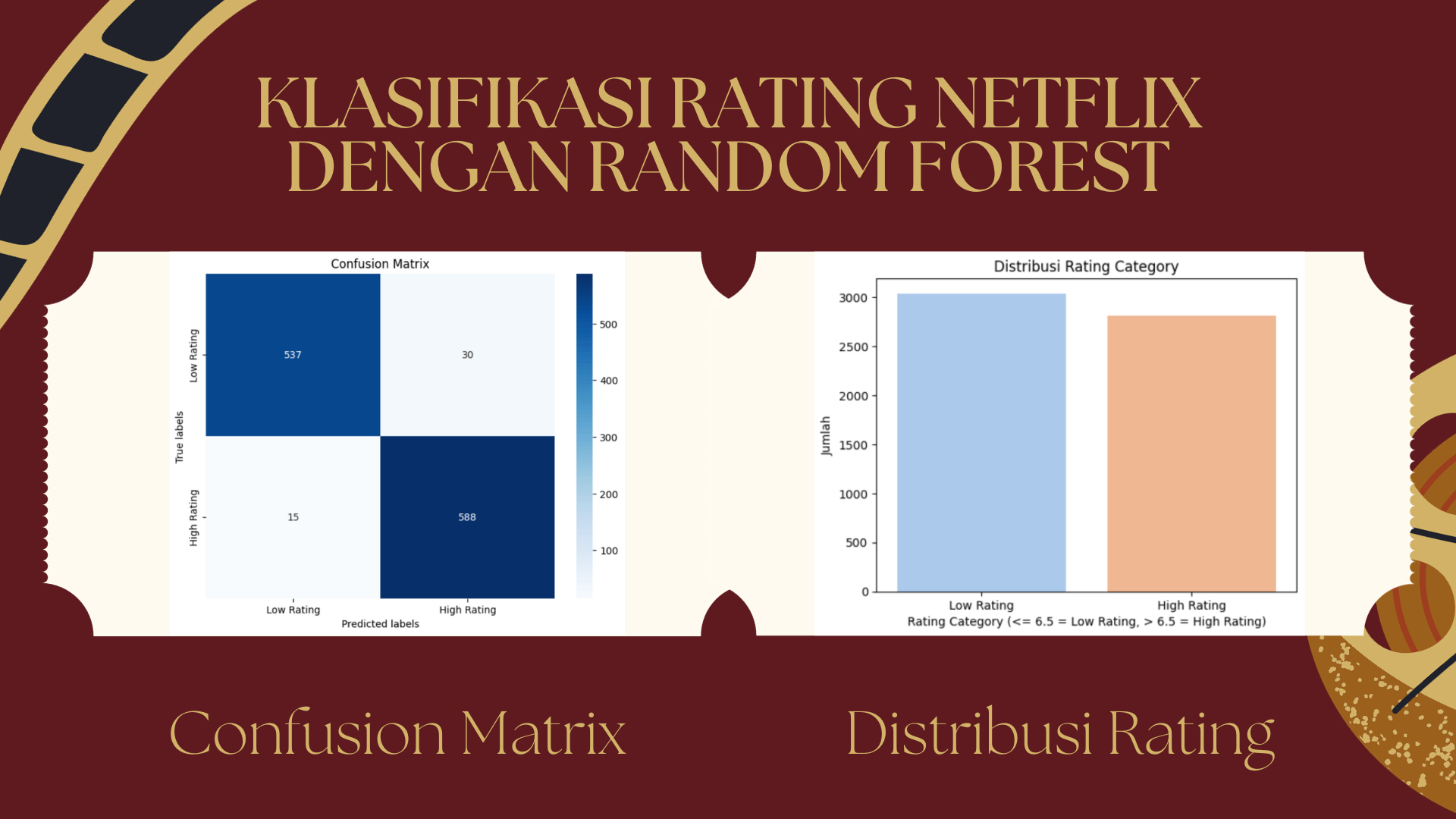
Matriks konfusi atau confusion matrix dibuat untuk memberikan visualisasi tentang prediksi yang benar dan salah dari model. Matriks ini ditampilkan dalam bentuk heatmap. Berdasarkan visualisasi confusion matrix tersebut, nilai True Positives (TP) adalah 537. Ini berarti model telah berhasil memprediksi 537 film atau acara TV yang sebenarnya memiliki ‘High Rating’ dengan tepat sebagai ‘High Rating’. Namun, ada 30 kasus, atau False Positives (FP), di mana model salah memprediksi film atau acara TV yang sebenarnya memiliki ‘Low Rating’ sebagai ‘High Rating’. Ini menunjukkan kesalahan tipe I, di mana model terlalu optimis dalam memprediksi kelas positif. Selanjutnya, ada 15 kasus False Negatives (FN), di mana model memprediksi film atau acara TV yang sebenarnya memiliki ‘High Rating’ sebagai ‘Low Rating’. Ini adalah kesalahan tipe II, yang menunjukkan bahwa model terlalu konservatif atau skeptis dalam memprediksi kelas positif. Terakhir, True Negatives (TN) berjumlah 588, yang menunjukkan bahwa model telah berhasil memprediksi 588 film atau acara TV yang sebenarnya memiliki ‘Low Rating’ dengan tepat sebagai ‘Low Rating’. Secara keseluruhan, model menunjukkan kinerja yang cukup baik dalam memprediksi kedua kelas, meskipun ada beberapa kesalahan yang perlu diperhatikan.
Pembuatan DataFrame hasil prediksi


DataFrame baru dibuat yang berisi label asli (‘Actual’) dan prediksi dari model (‘Predicted’) untuk setiap entri di data pengujian. DataFrame ini digabungkan dengan fitur asli dari data pengujian. Dihasilkan juga visualisasi grafik batang dari categorical distributions yang membandingkan data asli dengan ‘Actual’ dan prediksi dari model dengan label ‘Predicted’. Dapat dilihat bahwa keduanya memiliki hasil yang mirip karena akurasi model adalah 96.15%.
Visualisasi distribusi kategori rating


Untuk memberikan gambaran tentang seberapa banyak film atau acara TV yang memiliki ‘High Rating’ dibandingkan dengan ‘Low Rating’, dibuat bar plot yang menampilkan distribusi dari ‘rating_category’. Berdasarkan visualisasi yang dihasilkan, grafik batang menunjukkan bahwa kategori ‘Low Rating’ yang berwarna biru memiliki jumlah yang sedikit lebih tinggi daripada kategori ‘High Rating’, dengan sekitar 3000 lebih film atau acara TV yang diberi label sebagai ‘Low Rating’. Sementara itu, kategori ‘High Rating’ yang berwarna orange memiliki sekitar 2700 lebih film atau acara TV.
Kesimpulan
Dalam melakukan klasifikasi data dengan menggunakan machine learning berdasarkan dataset yang diambil dari Kaggle.com, yaitu data Netflix TV Shows and Movies, dilakukan beberapa langkah penting menggunakan Google Colab. Pertama, data diimpor dan dianalisis awal untuk memahami fitur-fitur dan struktur datanya. Selanjutnya, kolom ‘imdb_score’ digunakan untuk membuat kategori baru bernama ‘rating_category’, di mana film atau acara TV yang memiliki skor di atas 6.5 diklasifikasikan sebagai ‘High Rating’ dan sisanya sebagai ‘Low Rating’. Untuk meningkatkan kualitas data, nilai-nilai yang hilang pada fitur ‘release_year’, ‘runtime’, dan ‘imdb_score’ diisi dengan median masing-masing fitur tersebut. Setelah itu, fitur-fitur tersebut digunakan sebagai variabel independen dalam proses pelatihan model klasifikasi.
Model yang dipilih untuk klasifikasi adalah RandomForest, yang dikenal karena kinerja dan ketahanannya yang baik dalam berbagai jenis dataset. Setelah model dilatih, evaluasi kinerja dilakukan pada set data pengujian dan mendapatkan akurasi sekitar 96.15%, menunjukkan bahwa model memiliki kemampuan prediksi yang tinggi. Selain itu, Confusion Matrix digambarkan dalam bentuk heatmap untuk memberikan visualisasi lebih jelas tentang kinerja model dalam memprediksi kedua kategori rating. Untuk memberikan gambaran tentang distribusi data asli, dibuat sebuah bar plot atau grafik batang yang menunjukkan distribusi film atau acara TV dalam kategori ‘High Rating’ dan ‘Low Rating’. Dari visualisasi tersebut, terlihat bahwa kedua kategori memiliki distribusi yang hampir seimbang, dengan ‘Low Rating’ sedikit lebih banyak daripada ‘High Rating’.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Machine Learning For Beginner



