
Analisis Data terhadap Data Konsumsi Mie Instan
Anik Hanifatul Azizah
Summary
Exploratory Data Analysis dilakukan pada sebuah dataset berkaitan dengan konsumsi mie instan di dunia. Dataset ini terdiri dari 12 kolom data yang memuat tipe data integer,float dan object. Dataset ini mendeskripsikan jumlah populasi, pendapatan perkapita penduduk, nama daerah, negara dan benua, serta jumlah konsumsi masyarakat terhadap mie instan pada setiap tahunnya.
Dari dataset yang disajikan diharapkan dapat membuat beberapa hasil kesimpulan dan dapat diketahui beberapa hal yang berkaitan dengan tingkat konsumtif masyarakat umum. Pada laporan portofolio kali ini dilakukan beberapa proses analisis data, mulai dari import dataset ke dalam drive google collabs, melakukan data cleaning, mempersiapkan data, melakukan pemodelan dan visualisasi data. Hasil yang diperoleh menggambarkan beberapa kesimpulan yang menarik. Distribusi data menggambarkan hubungan antar variabel yang cukup signifikan. Hasil lain diperoleh beberapa visualisasi dan pemodelan yang dapat dipergunakan sebagai bahan pengembangan penelitian berkaitan dengan data analytics ke depannya.
Description
Analisis Data terhadap Data Konsumsi Mie Instan di Dunia
Persiapan Ujian Sertifikasi Data Science
Ringkasan
Exploratory Data Analysis dilakukan pada sebuah dataset berkaitan dengan konsumsi mie instan di dunia. Dataset ini terdiri dari 12 kolom data yang memuat tipe data integer,float dan object. Dataset ini mendeskripsikan jumlah populasi, pendapatan perkapita penduduk, nama daerah, negara dan benua, serta jumlah konsumsi masyarakat terhadap mie instan pada setiap tahunnya.
Dari dataset yang disajikan diharapkan dapat membuat beberapa hasil kesimpulan dan dapat diketahui beberapa hal yang berkaitan dengan tingkat konsumtif masyarakat umum. Pada laporan portofolio kali ini dilakukan beberapa proses analisis data, mulai dari import dataset ke dalam drive google collabs, melakukan data cleaning, mempersiapkan data, melakukan pemodelan dan visualisasi data. Hasil yang diperoleh menggambarkan beberapa kesimpulan yang menarik. Distribusi data menggambarkan hubungan antar variabel yang cukup signifikan. Hasil lain diperoleh beberapa visualisasi dan pemodelan yang dapat dipergunakan sebagai bahan pengembangan penelitian berkaitan dengan data analytics ke depannya.
Proses Analisis Data
- Data Loading
Hal yang pertama kali dilakukan adalah mengimport dataset ke dalam gdrive, karena disini menggunakan Google Collabs untuk pemrosesan data ini. Import dataset ini menggunakan fungsi import dan melakukan mount pada drive. Jika proses mount berhasil akan tampil dataset yang telah loading ke dalam Google collabs.



Langkah selanjutnya adalah menampilkan data teratas dalam dataset. Untuk menampilkan dataset teratas ini digunakan fungsi display, dan ditentukan berapa rows data yang ditampilkan, misalnya 10 rows, dimulai dari index 0. Maka akan tampak seperti pada gambar dibawah ini.


Selanjutnya dilakukan proses untuk mengetahui jumlah baris dan kolom. Terlihat hasil yang ditampilkan bahwa dataset terdiri dari 53 baris dan 12 kolom.

Dijalankan fungsi define kolom untuk menampilkan kolom apa saja yang terdapat dalam dataset. Hal ini dilakukan untuk memahami dataset yang ada.

Selanjutnya, dapat dilakukan juga pengecekan terhadap tipe data apa saja yang terdapat dalam dataset. Fungsi dtypes akan enampilkan tipe data pada setiap kolom dalam dataset. Maka diketahui dari hasil fungsi dtypes bahwa dataset ini memuat tipe object, float dan integer.

- Data Cleaning and Data preparation
Setelah mengetahui dengan jelas bentuk data dan berhasil melakukan data loading, maka proses selanjutnya adalah data cleaning.
Proses data cleaning diawali dengan mencari missing value pada data.

Terlihat dari hasil pencarian missing value, terdapat 4 kolom variabel yang memiliki kemungkinan mengandung null values. Sebanyak 3,77% missing value / null values pada data yang harus dilakukan cleaning

Lalu di dilakukan pengecekan posisi kolom yang mengandung missing value dengan menggunakan fungsi isnull.

Berdasarkan hasil tersebut dapat diketahui bahwa pada baris ke-42 terdapat 3 nilai null, yaitu pada kolom "2018", "2019", dan "2020". Karena memiliki banyak nilai null, lebih baik baris tersebut dihapus.
Proses menghapus data yang mengandung null values

Ketika dilakukan pengecekan apakah Null values masih ada, maka terlihat data tersebut telah terhapus

Proses data cleaning dilanjutkan lagi dengan menghapus baris yang memiliki null values

Proses data cleaning selanjutnya adalah menampilkan seluruh kolom. Dari langkah ini, terlihat bahwa terdapat duplikasi isi data pada kolom Country/Region dan Country/Territory. Maka kolom tersebut akan dihapus salah satunya, yakni Country/Territory. Penggunaan fungsi ini dilakukan untuk mengatasi data redundancy. Dan setelah ditampilkan maka redundancy kolom telah terhapus

- Visualization and Model
Tahapan berikutnya adalah melakukan Visualisasi data dan pemodelan. Proses visualisasi disini diawali dengan mengidentifikasi descriptive statistic.
Descriptive statictics ini diidentifikasi untuk menjelaskan atau memberikan gambaran mengenai karakteristik dari serangkaian data.

Langkah selanjutnya adalah mencoba untuk melakukan analisis univariate. Analisis Univariate digunakan untuk menggambarkan kumpulan data yang berupa frekuensi, nilai dengan frekuensi terbanyak, nilai minimum dan nilai maksimum dari variabel penelitian. Hasil dari analisis univariat ditampilkan dalam bentuk diagram plot grid.


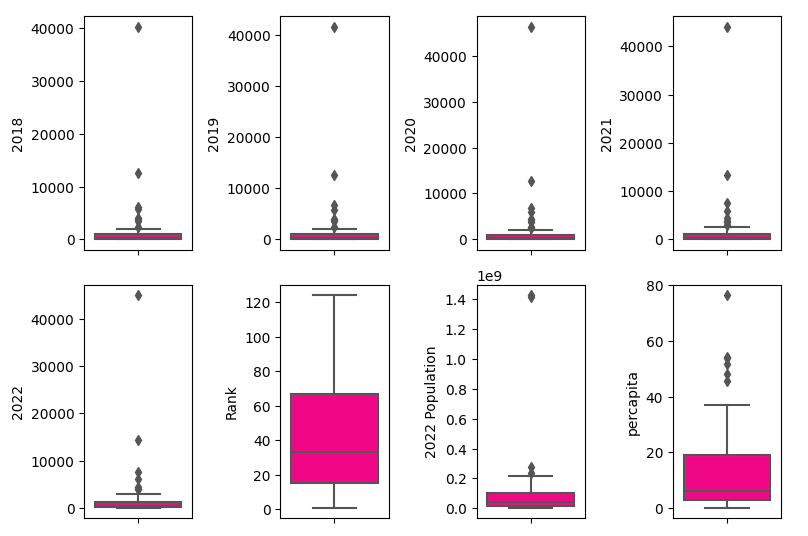
Dari analisis ini dapat terlihat bahwa data terdistribusi normal, terdapat sedikit outliers di sebelah kanan namun tidak terlalu besar.
Selain menggunakan diagram plot grid, visualisasi data dapat dilakukan juga dengan menggunakan boxplot, dijalankan dengan fungsi berikut ini.


Hal yang ingin dilakukan selanjutnya adalah mencari model tren jumlah konsumsi mie instan dari tahun ke tahun di seluruh dunia.
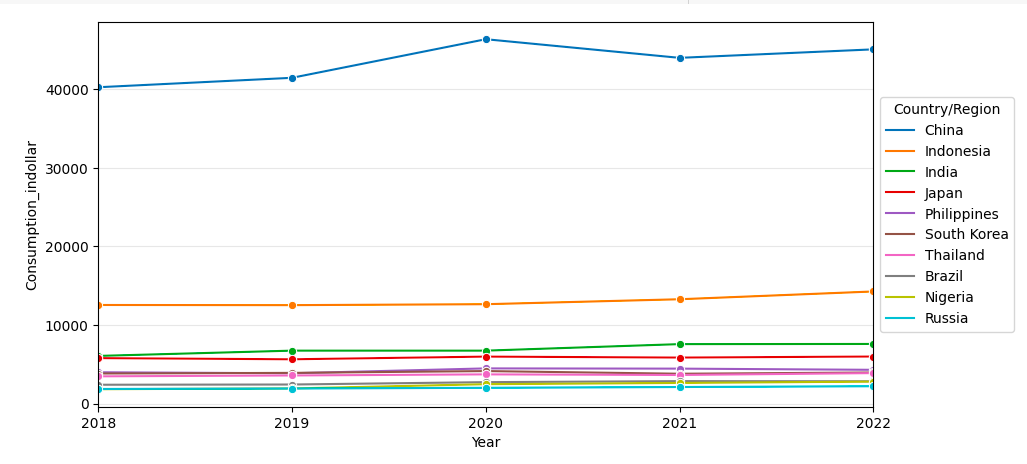
Fungsi yang dapat dijalankan adalah lineplot, dengan menampilkan di axis x periode tahun dan pada axis y jumlah konsumsi mie instan.

Maka hasilnya adalah sebagai berikut:
Terlihat bahwa konsumsi mie instan mengalami kenaikan dari tahun ke tahun.

Selanjutnya dilakukan analisis untuk menampilkan distribusi konsumsi mie instan di dunia berdasarkan benua / continent. Fungsi yang dijalankan adalah membaca index group-by-continent. Lalu digambarkan dalam diagram pie chart dengan disertai warna yang menampilkan perbedaan distribusi total konsumsi mie instan di masing-masing benua.

Maka hasil yang didapatkan adalah diagram pie chart berikut ini.


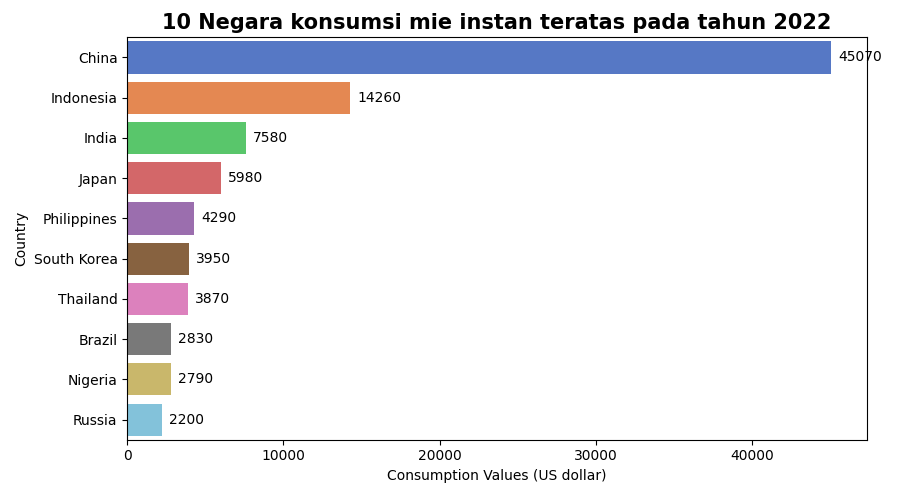
Selanjutnya dilakukan bivariate analysis untuk menemukan beberapa distribusi data berdasarkan suatu variabel tertentu. Pertama akan dicoba menampilkan distribusi data 10 jumlah konsumsi mie instan terbanyak berdasarkan negara.

Hasilnya dapat terlihat pada diagram bar berikut ini:

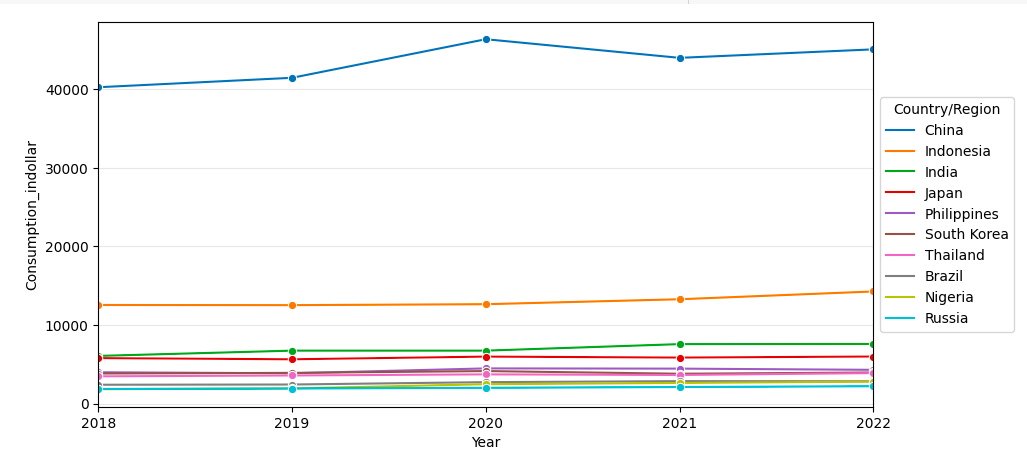
Setelah diketahui tren konsumsi mie instan di 10 negara tersebut, kita dapat mengecek pula tren setiap tahunnya di negara tersebut. Proses ini dilakukan dengan cara merge data per tahun dari masing-masing negara dengan fungsi melt.



Hasil dari menjalankan fungsi melt tersebut kemudian digambarkan menggunakan lineplot agar terlihat plot datanya. Maka hasilnya adalah sebagai berikut.

Visualisasi lain yang dapat dilakukan adalah mencari distribusi data banyaknya konsumsi mie instan berdasarkan percapita, dibatasi di 10 negara teratas seperti visualisasi sebelumnya.


Proses selanjutnya adalah menampilkan scatter plot hubungan antara Rank dan 2022 Population.

Lalu dapat dilakukan juga identifikasi menggunakan scatter plot untuk menampilkan hubungan antara 2022 consumption dan percapita

Selanjutnya, dari hasil visualisasi ingin diketahui korelasi model antar variabel. Pertama dilakukan analisis untuk mengetahui hubungan antara variabel jumlah konsumsi mie instan dan populasi.

Maka didapat hasil heatmap berikut.
Dari heatmap diketahui di garis warna hijau korelasi kuat antara jumlah populasi dan konsumsi mie instan per 2022, yaitu sebesar 0,78%. Lalu hal lain yang dapat disimpulkan adalah tidak adanya korelasi antara Benua dan populasi, terlihat dari heatmap berwarna ungu tua.

Fungsi korelasi lain yang dapat dijalankan adalah mencari nilai pearson correlation. Dengan memanggil library scipy.stats.pearsonr sebagai berikut ini.

Pearson correlation menunjukkan nilai 0,78, berarti 2 variabel tersebut memiliki korelasi yang kuat. P-value menunjukkan 1,84 berarti probabilitas hipothesis diterima dari hubungan kedua variabel tersebut cukup besar.
Kesimpulan
Dari beberapa proses analisis data yang telah dilakukan terhadap dataset terkait konsumsi mie instan didapat beberapa kesimpulan sebagai berikut:
- Konsumsi mie instan mengalami kenaikan dari tahun ke tahun di negara-negara di dunia
- Konsumsi mie instan terbesar berada pada benua asia
- 10 negara konsumsi mie instan terbanyak, 3 peringkat teratas ditempati oleh China, Indonesia dan India
- Negara-negara di dunia memiliki konsumsi tinggi terhadap makanan mie instan dikarenakan proses penyajiannya yang mudah dan cepat.
Dari proses analisis data yang telah dilakukan, dataset ini dapat diidentifikasi korelasi antar variabel, namun tidak terdapat variabel yang mempunyai hubungan sebab-akibat yang terlalu kuat. Sebagai bahan pengembangan ke depan, dataset masih dapat diperkaya dengan variabel lain, dan juga dapat dilakukan proses analisis lain sehingga knowledge yang didapat akan lebih beragam.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Persiapan Sertifikasi Kompetensi Okupasi Associate Data Scientist

