
Riya Widayanti
Riya widayanti

Summary
Melakukan analisis data Smartphone_Cleaned_V5.CSV yang diambil dari website https://www.kaggle.com/datasets. Dengan menggunakan model regresi liner yang didapat dari matriks korelasi dari 2 variabel yang dipilih dengan nilai paling besar didapat bahwa semakin tinggi ram capacity akan menghasilkan rating semakin tinggi. Namun pada nilai ram capacity terbesar yaitu 12 (dalam nilai variabel) maka rating menjadi tidak berpengaruh.
Memberi masukan bahwa industri smartphone dapat memproduksi untuk ram capacity yang sering digunakan untuk umum.
Description
Proposal
Sertifikasi Kompetensi Okupasi Associate Data Science Riya Widayanti
Fungsi Membaca Data
Proses awal dalam data science adalah proses mendapatkan data. Berdasarkan pengalaman dan ujicoba proses pengambilan data nya dari https://www.kaggle.com/datasets.
Diambil 2 data set untuk proses analisis yaitu, ada du acara:
- Download data set
- Simpan dalam google drive
- Atau diupload manual ke lokasi yang diinginkan lewat side bar icon
Selanjutnya proses maunting data untuk data google drive, dengan proses penyelarasan dengan pandas. Dengan perintah
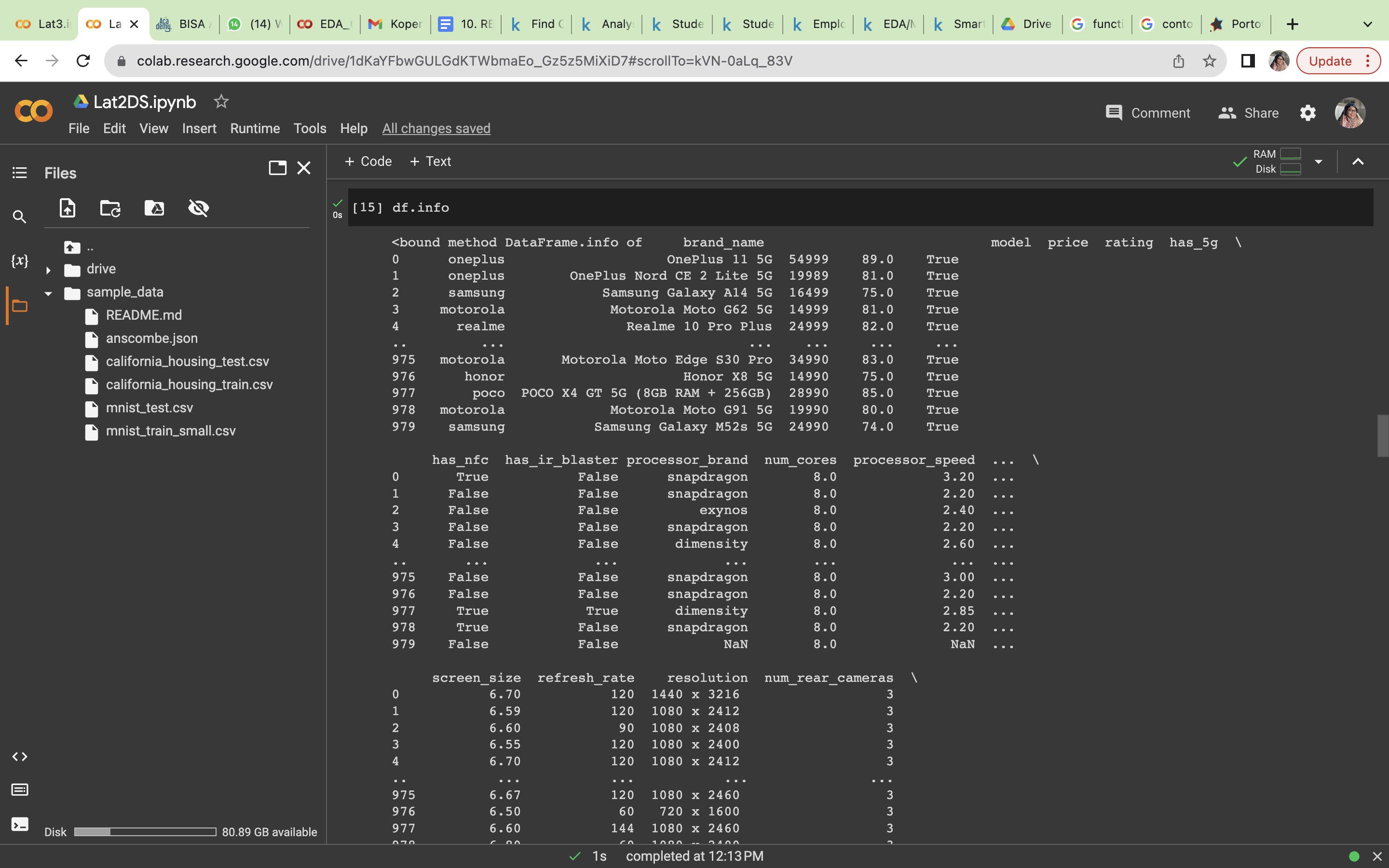
pemanggilan data dari google drive nama file yang digunakan adalah SMARTPHONE_CLEANED_V5.CSV
from google.colab import drive drive.mount('/content/drive')
import pandas as pd #lib pandas yang digunakan untuk membaca data, manipulasi data, dll
df = pd.read_csv("/content/drive/MyDrive/smartphone_cleaned_v5.csv")
Membersihkan Data
Proses ini dilakukan untuk memastikan data set yang digunakan bebas dari data kosong, “?”, atau nan
df_baris = df
# Menghapus baris yang memiliki nilai "?"
df_baris = df_baris[df_baris != '?'].dropna() df_baris
df=df_baris
Menyiapkan Data
Untuk melihat isi data dan struktur data yang ada dalam data set.
Membuat dan menyimpan Model
Untuk memudahkan membuat model dilakukan matrik korelasi dengan
import pandas as pda
import seaborn as sns
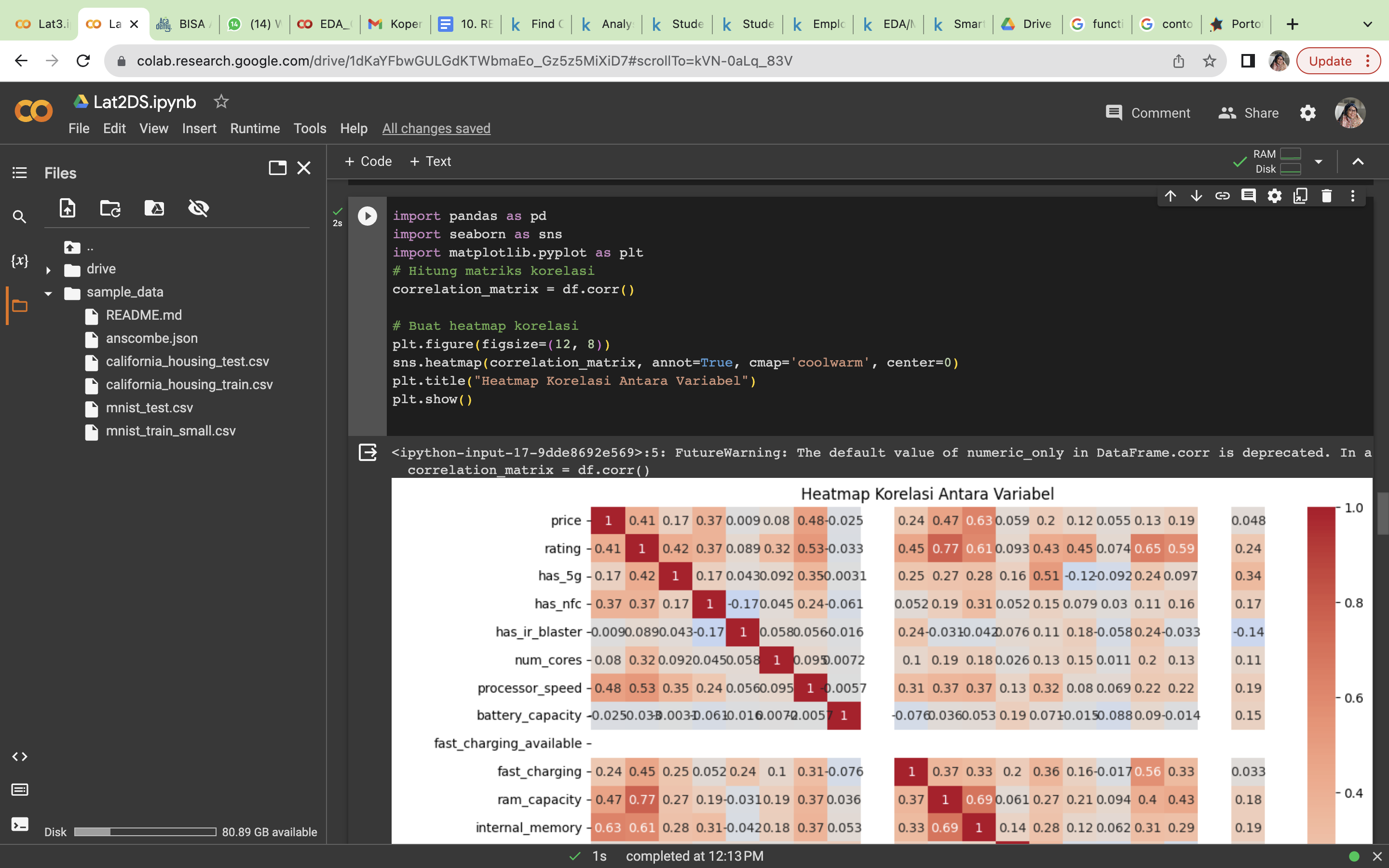
import matplotlib.pyplot as plt # Hitung matriks korelasi correlation_matrix = df.corr()
# Buat heatmap korelasi
plt.figure(figsize=(12, 8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0) plt.title("Heatmap Korelasi Antara Variabel")
plt.show()
Hasil dari proses pembuatan matrix korelasi adalah sebagai berikut:
Menyatakan kolom (filed data) dari variabel data yang memiliki nilai. Dalam hal ini dipilih nilai korelasi tertinggi yaitu variabel rating dan ram_capacity
Selanjutnya duelakukan ploting gambar dari korelasi dua variable yang memiliki angka terbesar yaitu
Variabel ram_capacity dan variabel rating
import matplotlib.pyplot as plt
plt.scatter(df['ram_capacity'], df['rating']) plt.xlabel("Ram Capacity") plt.ylabel("Rating")
plt.show()
Penjelasan hasil yang didapat
Adapun hasil dari ploting dua variabel dihasilkan
Selanjutnya dilakukan pemodelan data dengan model regresi linier, dengan statemen sebagai berikut:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
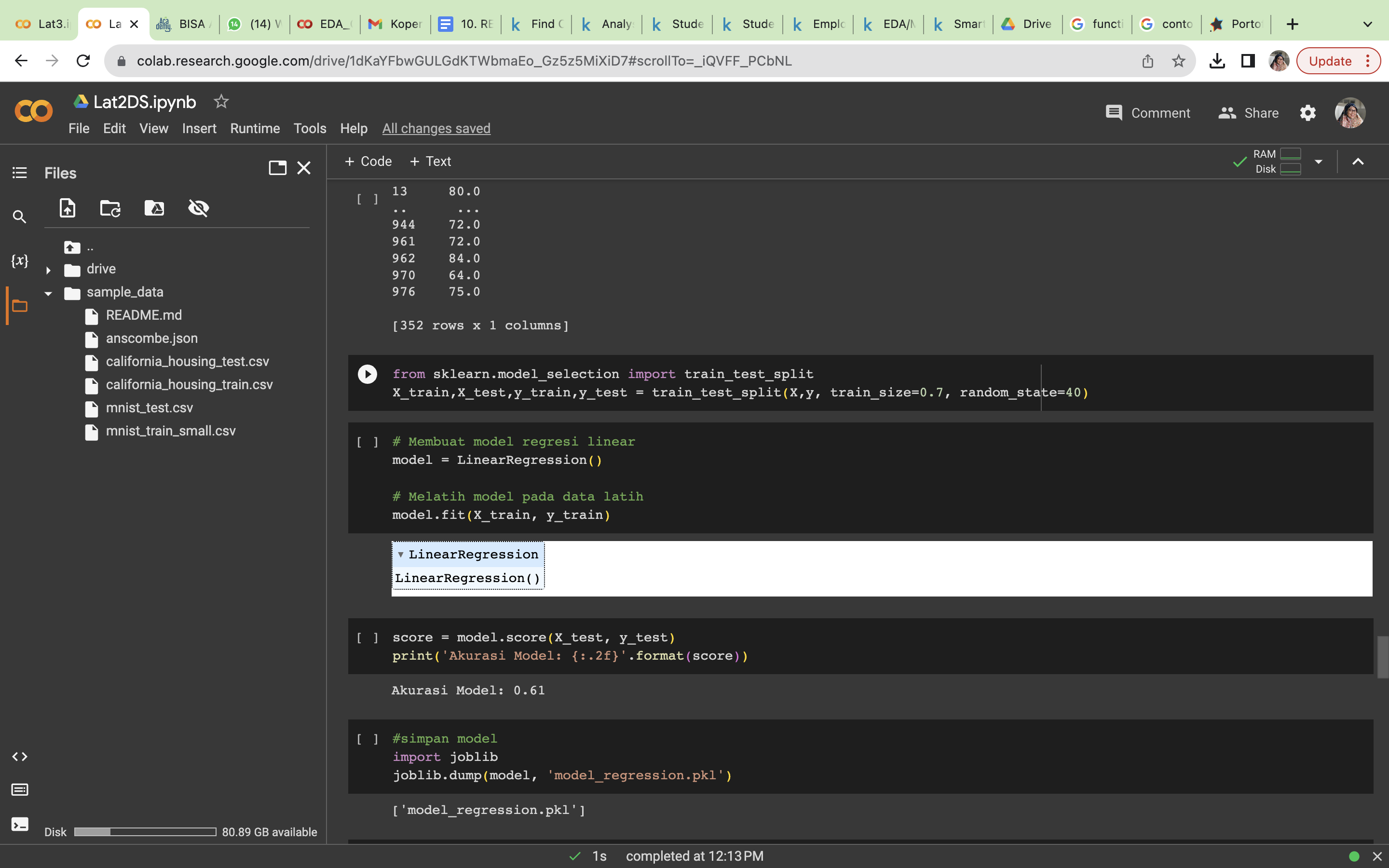
from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y, train_size=0.7, random_state=40)
# Membuat model regresi linear
model = LinearRegression()
# Melatih model pada data latih
model.fit(X_train, y_train)
score = model.score(X_test, y_test) print('Akurasi Model: {:.2f}'.format(score))
Semakin tinggi nilai variabel RAM CAPACITY maka semakin tinggi pula rating yang diberikan, hal ini berkaitan dengan fungsi kapasitas Ram dalam kecepatan aplikasi di smartphone. Namun pada titik RAM terbesar tidak memberikan pola yang sama.
Hal ini memberikan masukan pada industri smart phone bahwa memproduksi RAM yang tidak terlalu besar namun pada tingkat RAM yang umum.
Setelah dilakukan pemodelan data dengan regresi linier dengan keakuasi data sebesar 0.61. Berdasarkan dari hasil keakurasi model tersebut, perlu diuji dengan model lain.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Persiapan Sertifikasi Kompetensi Okupasi Associate Data Scientist



