
Heart Disease Dataset Classification
Chrisantonius
Summary
Dataset heart.csv ini berisikan informasi Orang dengan penyakit kardiovaskular atau yang memiliki risiko kardiovaskular tinggi (karena adanya satu atau lebih faktor risiko seperti hipertensi, diabetes, hiperlipidemia, atau penyakit yang sudah ada) dan dengan informasi tersebut dapat dilakukan deteksi dan penanganan dini di mana model machine learning dapat sangat membantu dalam permasalahan tersebut.
Description
LIBRARIES
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
DATA
Dataset heart.csv ini berisikan informasi Orang dengan penyakit kardiovaskular atau yang memiliki risiko kardiovaskular tinggi (karena adanya satu atau lebih faktor risiko seperti hipertensi, diabetes, hiperlipidemia, atau penyakit yang sudah ada) dan dengan informasi tersebut dapat dilakukan deteksi dan penanganan dini di mana model machine learning dapat sangat membantu dalam permasalahan tersebut.
df = pd.read_csv('heart.csv')
df.head()
| age | sex | cp | trestbps | chol | fbs | restecg | thalach | exang | oldpeak | slope | ca | thal | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 63 | 1 | 3 | 145 | 233 | 1 | 0 | 150 | 0 | 2.3 | 0 | 0 | 1 | 1 |
| 1 | 37 | 1 | 2 | 130 | 250 | 0 | 1 | 187 | 0 | 3.5 | 0 | 0 | 2 | 1 |
| 2 | 41 | 0 | 1 | 130 | 204 | 0 | 0 | 172 | 0 | 1.4 | 2 | 0 | 2 | 1 |
| 3 | 56 | 1 | 1 | 120 | 236 | 0 | 1 | 178 | 0 | 0.8 | 2 | 0 | 2 | 1 |
| 4 | 57 | 0 | 0 | 120 | 354 | 0 | 1 | 163 | 1 | 0.6 | 2 | 0 | 2 | 1 |
df.shape
(303, 14)
dari fungsi .info() dapat diketahui informasi jumlah kolom dan data type dari masing-masing kolom pada dataset heart, tidak terdapat nilai null value dari masing-masing kolom
df.info()

df.describe()

EDA
pada tahap ini diketahui untuk kolom target terdapat value 0 yang berjumlah 138 data dan 1 berjumlah 165 data
df['target'].value_counts()
1 165
0 138
Name: target, dtype: int64
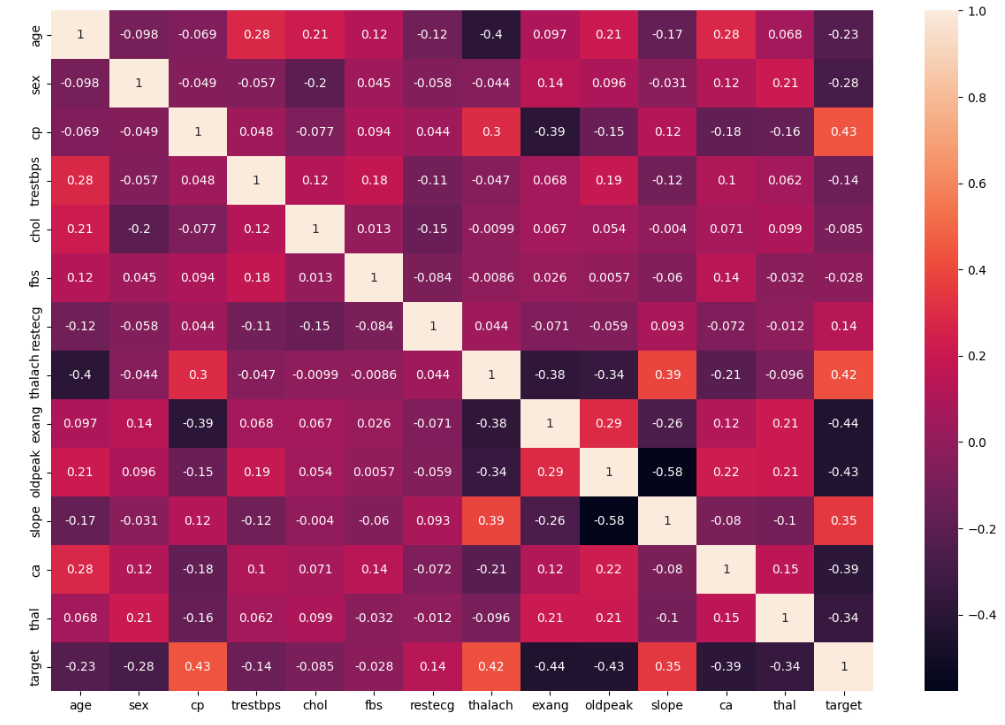
Melakukan pengecekkan korelasi antar variable divisualisasikan dengan diagram heatmap
plt.figure(figsize=(15,10)) sns.heatmap(df.corr(), annot=True)

PREPROCESSING
melakukan drop pada chol dan fbs karena hasil uji korelasi menunjukan kedua kolom tersebut tidak memiliki nilai korelasi terhadap kolom target dibuktikan dengan nilai korelasi chol-0.085 dan fbs -0.028

melakukan split kepada data dengan proporsi 70% data training dan 30% sebagai data testing
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10)

from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, mean_absolute_error,classification_report, confusion_matrix, roc_auc_score, roc_curve
knn_model = KNeighborsClassifier(n_neighbors=20, metric="minkowski")
knn_model.fit(X_train, y_train)
preds = knn_model.predict(X_test)

SVM (Support Vector Machine) adalah algoritma machine learning untuk klasifikasi dan regresi, dan library SVC pada Python adalah implementasi dari algoritma SVM yang memungkinkan kita untuk membuat model SVM untuk klasifikasi
from sklearn.svm import SVC
clf = SVC(random_state=0) clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)

XGBoost (Extreme Gradient Boosting) adalah algoritma ensemble yang digunakan untuk regresi dan klasifikasi
from xgboost import XGBClassifier xgb=XGBClassifier().fit(X_train,y_train)
xgb_y_pred=xgb.predict(X_test)

Kesimpulan
Dari 3 metode yang digunakan k-NN, SVM, dan XGBoost menunjukkan nilai akurasi dengan metode menggunakan XGBoost memiliki tingkat akurasi yang lebih baik dibandingkan 2 metode lainnya. XGBoost memiliki tingkat akurasi 81% dengan nilai MAE sebesar 0.18, nilai MAE ini juga menunjukkan prediksi model hampir sempurna sesuai dengan nilai sebenarnya karena nilainya mendekati 0.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Persiapan Sertifikasi Internasional CDSP (Certified Data Science Practitioner)

