
Prediksi Heart Disease dengan Decision Tree
ajrul azwar


Summary
Summary
Klasifikasi adalah proses pengelompokkan data untuk menentukan hasil prediksi dengan menggunakan metode Decision Tree (pohon keputusan). Algoritma Decision Tree yang merupakan salah satu metode dalam bidang machine learning dan termasuk metode supervised learning.
Description
Description
Pada portofolio ini, saya akan melakukan klasifikasi data heart disease untuk menentukan kondisi Kesehatan jantung dengan metode Decision Tree (pohon keputusan). Keuntungan dari Decision Tree adalah interpretabilitasnya yang baik, karena keputusan yang diambil dapat dijelaskan dalam bentuk aturan sederhana. Decision Tree juga dapat menangani data dengan baik dalam bentuk kategorikal dan numerik. Data heart disease dapat dibagi menjadi dua jenis, yaitu data yang bersifat numerik dan data yang bersifat kategorikal. Data numerik dapat berupa informasi seperti usia, tekanan darah, kadar kolestrol, dll, sedangkan data kategorikal dapat berupa informasi seperti jenis kelamin, anggota tubuh dan sebagainya.
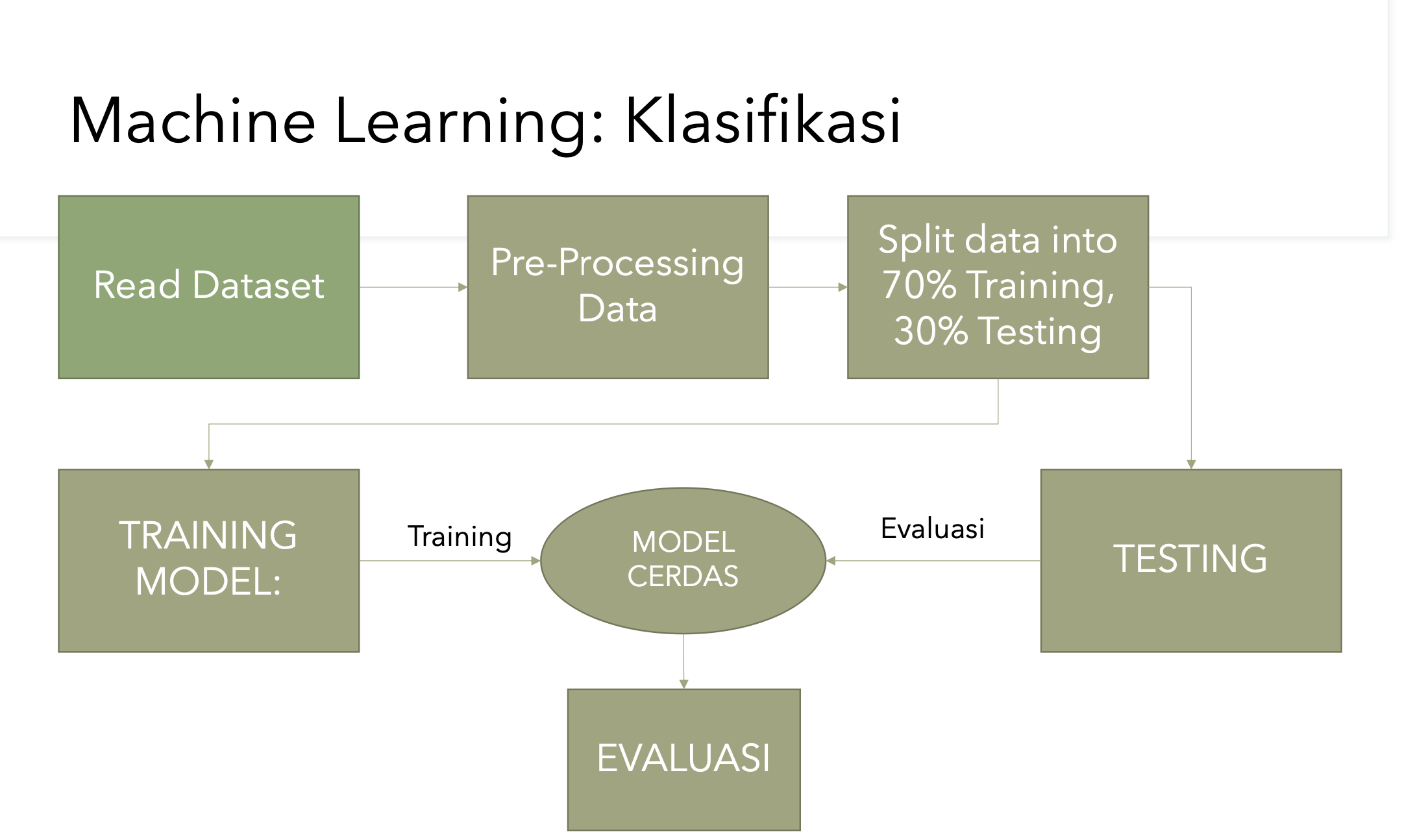
Berikut adalah tahapan dalam melakukan proses klasifikasi :

Mounting drive
untuk melakukan klasifikasi adalah menggambil dataset heart disease pada website Kaggle.com dan kemudian diupload ke google drive dan melakukan proses klasifikasi dengan menggunakan google collabs, dan pastikan sudah dilakukan pre-processing atas data-data error seperti missing values.

Import library dan read dataset
Berikutnya adalah mengimport library yang dibutuhkan untuk membaca data yaitu pandas dan menghubungkan dataset yang akan kita analisa, selanjutnya membaca dataset untuk memastikan dataset sudah terhubung dengan library pandas.

filtering data
Filtering data dilakukan jika ingin membatasi data pasien dengan range umur yang diinginkan, dalam kasus ini kita ingin melihat data pasien dengan usia > 30 tahun dan < 50 tahun.

Pemisahan variable
Berikutnya adalah pemisahan variable dependen dan independent, dikarena variable dependen yang akan kita uji adalah “target”, maka variable lainnya dijadikan variable indenpenden yang terdiri dari data kolom ke-1 sampai dengan kolom ke 13.

Split data
Berikutnya adalah pemisahan data training dengan data testing dengan menggunakan fungsi train_test_split pada library sklearn, Langkah ini berfungsi untuk menentukan akurasi dari hasil prediksi apakah mempunyai penyakit jantung atau tidak. Split data ini membagi data training dan data test sebesar 70% berbanding 30%.

Proses klasifikasi
Klasifikasi menggunakan Decission Tree, untuk menentukan apakah prediksi bahwa y train yang dihasilkan berdasarkan data test dan model yang sudah dibuat apakah menghasil nilai x test yang akurat.

Hasil akurasi
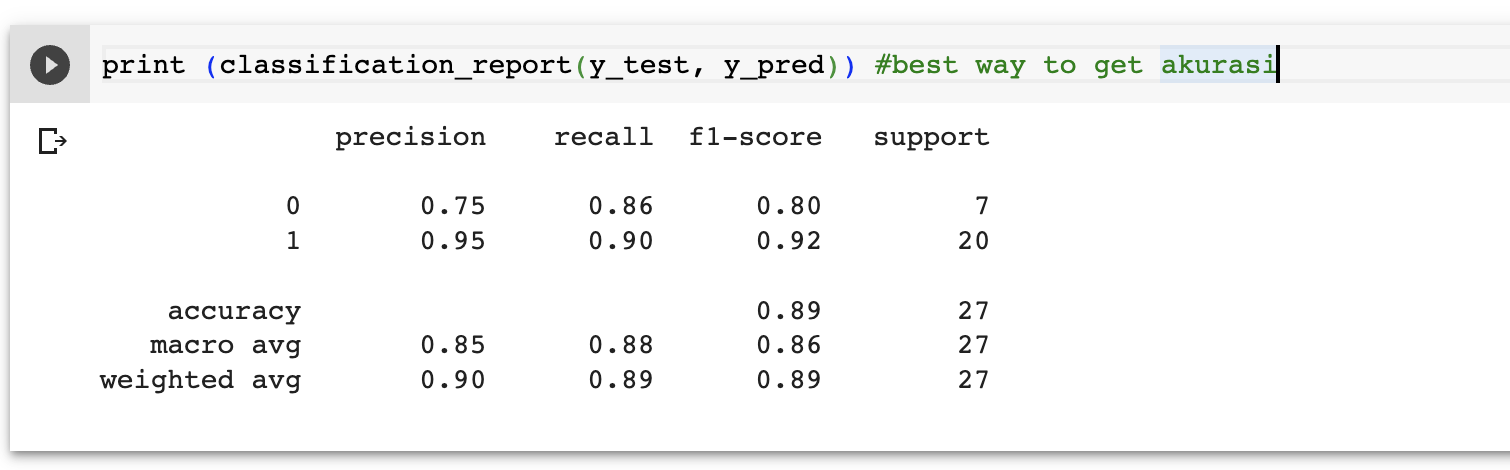
Langkah terakhir adalah untuk melihat hasil akurasi data data train dan data test. Untuk melihat hasil akurasi, saya akan mencoba melihat kedalam 3 bentuk fungsi akurasi yang ada pada library sklearn, yaitu fungsi accuracy_score, confusion_matrix dan classification_report.
Hasil akurasi dengan accuracy_score (0.8888)

Hasil akurasi dengan confusion_matrix

Hasil akurasi dengan classification_report

Kesimpulan
Berdasarkan klasifikasi yang telah dilakukan, didapati nilai akurasi yang dihasilkan adalah 0.8 atau 80% dan dapat disimpulkan bahwa seseorang akan terkena penyakit jantung sebesar 80% apabila memenuhi beberapa nilai indikator didalam dataset heart disease. Hasil ini digunakan untuk menguji data terbatas dan pemodelan terbatas, agar pemodelan ini tidak disalahgunakan untuk penerapan dilapangan, pemodelan ini perlu diuji lebih dalam untuk penggunaan teknik yang lebih optimal guna menghasilkan desain atau pemodelan dan solusi yang layak. Keterbatasan klasifikasi dalam kasus ini adalah bahwa saya belum menerapkan teknik yang lebih optimal apa pun untuk meningkatkan parameter model, namun saya percaya bahwa dengan penerapan yang lebih optimal, kinerja solusi yang diusulkan akan dapat ditingkatkan ketingkat berikutnya.
Dalam penerapan Etika Data Science terdapat tiga unsur penting, yaitu :
PRIVASI
mengacu pada perlindungan data pribadi individu dalam dataset. Pemrosesan data kesehatan seperti dataset heart memuat informasi pribadi pasien yang harus dijaga kerahasiaannya. Penting untuk mematuhi peraturan privasi data seperti GDPR (General Data Protection Regulation) atau peraturan privasi kesehatan lainnya untuk memastikan data sensitif aman dari penyalahgunaan atau akses yang tidak sah.
BIAS
mengacu pada kecenderungan atau distorsi dalam data atau algoritma yang dapat menyebabkan ketidakadilan dalam pengambilan keputusan atau analisis. Dataset heart harus diperiksa secara cermat untuk memastikan tidak adanya bias yang merugikan terhadap kelompok tertentu, seperti kesenjangan pengobatan berdasarkan jenis kelamin atau ras. Upaya untuk mengidentifikasi dan mengurangi bias harus dilakukan untuk mendapatkan hasil analisis yang obyektif dan adil.
TRANSPARANSI
aspek etika yang menuntut keterbukaan dan kemampuan untuk menjelaskan secara jelas bagaimana data dikumpulkan, diproses, dan bagaimana model dihasilkan. Dalam konteks dataset heart, penting untuk menjelaskan dengan transparan asal-usul data medis, variabel apa saja yang digunakan, serta metode atau algoritma apa yang digunakan dalam analisis. Transparansi membantu membangun kepercayaan dan memungkinkan orang lain untuk mereplikasi atau memverifikasi hasil analisis.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Persiapan Sertifikasi Internasional DEBIZ (Data Ethic for Business Professionals)



