
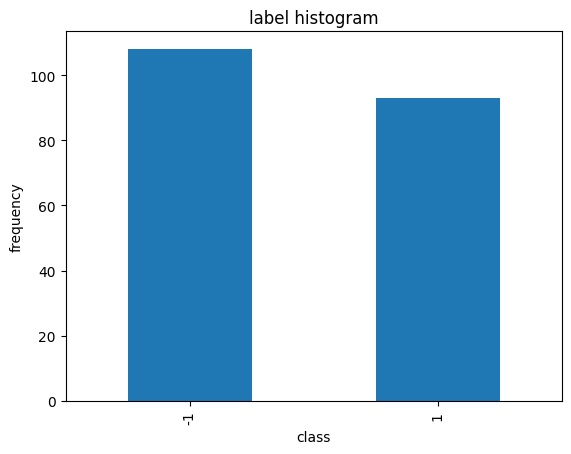
Text Analytics (Sentiment Analysis)
Khoiriya Latifah


Summary
Text Analytics (Sentiment Analysis Using Twitter Data Crawling)
This sentiment analysis utilizes Twitter data crawling. The data is obtained from the Twitter API. This case discusses the processing of unstructured text data with simple steps, namely preprocessing involving several stages, Text Vectorization, and the Model using LSTM.
We used LSTM Model cause Sequential and Time-Series Data: LSTMs are particularly effective for sequential and time-series data, where the order and context of data points matter. This makes them well-suited for tasks like language modeling, sentiment analysis,
LSTMs have shown exceptional performance in various natural language processing tasks, achieving state-of-the-art results in tasks like sentiment analysis
Description
Text Analytics (Sentiment Analysis Using Twitter Data Crawling)
The steps to perform unstructured data text preprocessing :
• Case Folding
The process of converting text into "uppercase" and "lowercase" letters.
• Stopword Removal
Eliminating words that are considered not significantly impactful in the text data.
• Stemming/ Lemmatization
The process of transforming words into their root forms.
Example: membuat -> buat, menulis -> tulis, etc.
• Slangword Handling
Addressing non-formal words, everyday words, abbreviations, or colloquialisms present in the text by transforming them into formal word forms.
Example: Yg -> yang, krn -> karena, etc.
def formaldanstop(t):
t = word_tokenize(t)
for i,x in enumerate(t):
if x in SlangS.keys():
t[i] = SlangS[x]
return ''.join(' '.join(x for x in t if x not in stops))
id_stopword_dict = pd.read_csv('/content/drive/My Drive/dataset/stopwordbahasa.csv', header=None)
id_stopword_dict = id_stopword_dict.rename(columns={0: 'stopword'})
stopwords_new = pd.DataFrame(['sih','nya', 'iya', 'nih', 'biar', 'tau', 'kayak', 'banget'], columns=['stopword'])
id_stopword_dict = pd.concat([id_stopword_dict,stopwords_new]).reset_index()
id_stopword_dict = pd.DataFrame(id_stopword_dict['stopword'])
import nltk
nltk.download('punkt')
from nltk import word_tokenize
factory = StemmerFactory()
stemmer = factory.create_stemmer()
text_preproc1 = []
for x in text:
pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*(),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+')
x = re.sub(pattern,' ',x) #remove urls if any
#Convert to lower case
x = x.lower()
#unnecessary
x = re.sub(r'pic.twitter.com.[w]+', '', x) # Remove every pic
x = re.sub('((www.[^s]+)|(https?://[^s]+)|(http?://[^s]+))',' ',x)
x = re.sub('[^0-9a-zA-Z]+', ' ', x)
#Convert www.* or https?://*
x = re.sub('((www.[^s]+)|(https?://[^s]+))','',x)
#remove symbols
x = re.sub(r'[^.,a-zA-Z0-9 .]',' ',x)
x = x.replace(',',' ').replace('.',' ')
#Remove additional white spaces
x = re.sub('[s]+', ' ', x)
from wordcloud import WordCloud, STOPWORDS
comment_words = ''
stopwords = set(stops)
for val in text_preproc2:
# typecaste each val to string
val = str(val)
# split the value
tokens = val.split()
# Converts each token into lowercase
for i in range(len(tokens)):
tokens[i] = tokens[i].lower()
comment_words += " ".join(tokens)+" "
wordcloud = WordCloud(width = 800, height = 800,
background_color ='white', stopwords = stopwords,
min_font_size = 10).generate(comment_words)
# plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0)
plt.show()
from Sastrawi.StopWordRemover.StopWordRemoverFactory import StopWordRemoverFactory
from Sastrawi.Stemmer.StemmerFactory import StemmerFactory
stopword = StopWordRemoverFactory().create_stop_word_remover()
stemmer = StemmerFactory().create_stemmer()
clean_text = []
for i,kalimat in enumerate(text_preproc2):
stop = stopword.remove(kalimat)
stem = stemmer.stem(stop)
if i%100 ==0:
print('loading kalimat ke:',i,'dari',len(text_preproc2))
clean_text.append(stem)

- Feature Extraction
The process of converting words and sentences into representative vector forms. Some commonly used methods include TF-IDF, word embedding, skip gram, etc. In this case used TF-IDF Method.
Count Vectorisation
This is a way of vectorizing texts that considers the count of each word in a document/documents. In count vectorization, a word with more counts is considered more significant. However, only giving counts does not guarantee that the feature of the document is well expressed with this type of vectorization. There could be certain words that appear repetitively but do not have much significance.
TF-IDF (Term Frequency — Inverse Document Frequency)
TF-IDF is a measure that can quantify the importance or relevance of words in a document amongst a collection of documents. TF-IDF is expressed as below.
Among multiple documents, the number of documents that contain the word i, frequency of word i in each document and the total number of documents are considered in TF-IDF.

# TOKENISASI
max_features = 7600
tokenizer = Tokenizer(num_words=max_features, split=' ')
tokenizer.fit_on_texts(data['Tweets'].values)
x = tokenizer.texts_to_sequences(data['Tweets'].values)
X = pad_sequences(x)
X
import tensorflow as tf
from keras.utils.data_utils import pad_sequences
from tensorflow.keras.utils import pad_sequences
tf.keras.utils.pad_sequences
#TEXT PREPROCESSING
max_review_length = 1000
X_train = tf.keras.utils.pad_sequences(X_train, maxlen=max_review_length)
X_test = tf.keras.utils.pad_sequences(X_test, maxlen=max_review_length)
CREATE MODEL MACHINE LEARNING USING LSTM
# CREATE THE MODEL
embedding_vecor_length = 500
model = Sequential()
model.add(Embedding(top_words, embedding_vecor_length, input_length=max_review_length))
model.add(LSTM(64))
model.add(Dense(2, activation='sigmoid'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['categorical_accuracy'])
print(model.summary())
model.fit(X_train, dummy_y_train, validation_data=(X_test, dummy_y_test), epochs=3, batch_size=25, verbose=1)
The model utilizes LSTM layers to process textual data. We can adjust the size of the LSTM layers, activation functions, and other parameters according to our needs. Furthermore, we need to ensure that we input the preprocessing data and input data in the format required by the model.
We used LSTM Model cause Sequential and Time-Series Data: LSTMs are particularly effective for sequential and time-series data, where the order and context of data points matter. This makes them well-suited for tasks like language modeling, sentiment analysis,
LSTMs have shown exceptional performance in various natural language processing tasks, achieving state-of-the-art results in tasks like sentiment analysis.
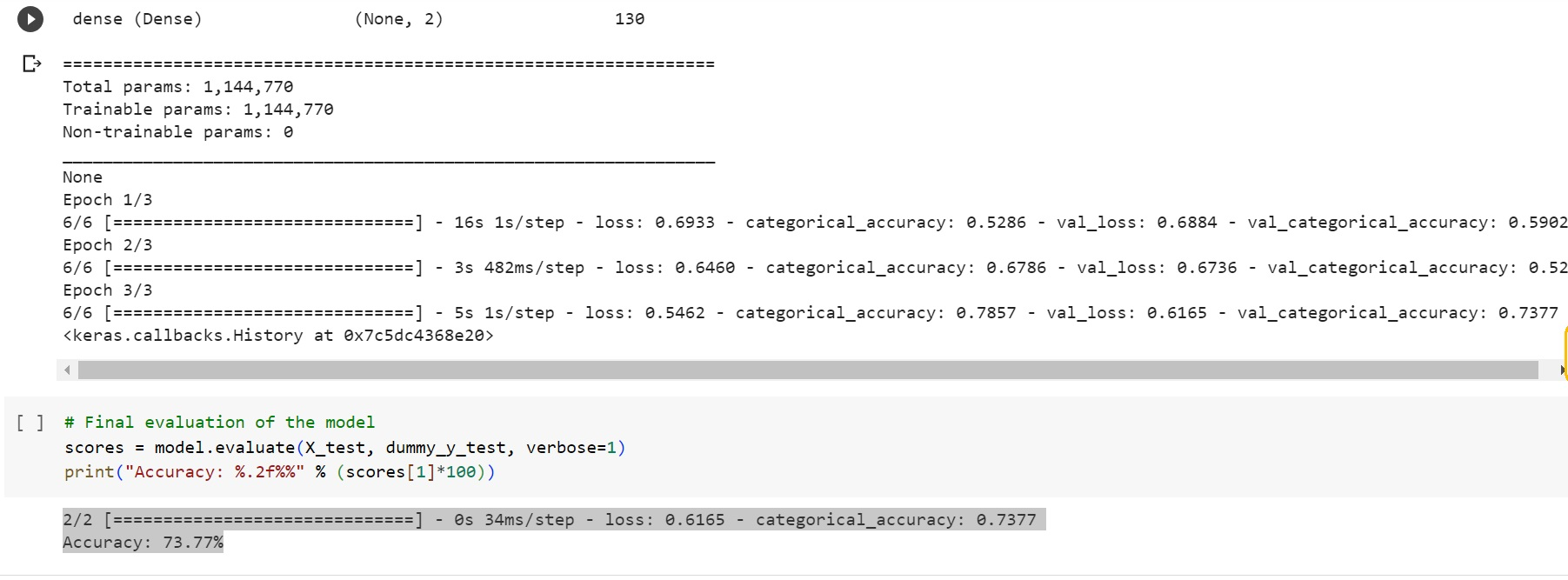
# MODEL EVALUATION
scores = model.evaluate(X_test, dummy_y_test, verbose=1)
print("Accuracy: %.2f%%" % (scores[1]*100))
2/2 [==============================] - 0s 34ms/step - loss: 0.6165 - categorical_accuracy: 0.7377
Accuracy: 73.77%
This model has an accuracy of only 0.7 due to the unstructured dataset, leading to the removal of a significant amount of data during the data cleaning phase because of duplicates.
Informasi Course Terkait
Kategori: Artificial IntelligenceCourse: Statistika dan Probabilitas
