
Tweet Sentiment Analysis with Naive Bayes method
ERNA ROSALINA
Summary
Kemajuan teknologi dan komunikasi saat ini mempengaruhi penggunaan media sosial. Twitter merupakan salah satu jejaring sosial yang ramai dipergunakan untuk berinteraksi dan menuangkan opini. Pada awal 2020 opini masyarakat ramai di utarakan dalam kemunculan virus baru di Indonesia yang bernama covid-19. Demi memutus penyebaran virus Pemerintah melakukan Kebijakan social distancing atau jaga jarak antar sesama. Selain itu, disusul dengan PSBB (Pembatasan Sosial Berskala Besar) dan PPKM (Pemberlakuan Pembatasan Kegiatan Masyarakat). Kebijakan yang muncul telah direspon oleh masyarakat dengan berbagai opini di jejaring twitter. Opini tersebut akan dianalisa oleh peneliti, dengan mengimplementasikan Text Mining menggunakan metode Naïve Bayes Classifier sebagai pengklasifikasian text. Tahapan pemprosessan pada penelitian dilakukan dengan cleaning, tokenisasi, stopword removal, dan stemming. Selanjutnya tahap klasifikasi dilakukan proses Analisis Sentimen tweet yang berkategori positif atau negatif. Evaluasi model menggunakan K-Fold Cross-Validation dengan perhitungan k = 4 didapatkan hasil akuarasi rata - rata 74.25 %.
Description
Tweet Sentiment Analysis with Naive Bayes method
Data Scraping Twitter 2021
- To install Twint using the pip command,

- Add Library and extract tweet data

Data collection was taken from Twitter by sreping data using twint. The data taken is in the form of unstructured text. In this case Data was taken from the keywords PSBB or PPKM. The tweet period is from November 1, 2020, to March 30, 2020. Data collection was carried out randomly on the tweets of the Indonesian people on Twitter. The data taken was 400 tweets related to the implementation of the Indonesian Government's policy regarding "social distancing". The libraries is very much needed in the data retrieval process, the libraries used are in the form of twint. After the process of scraping the data obtained will be automatically saved in Excel in .csv format.
Validation Labeling Manually
| The data that has been taken, then cleaned manually by taking the contents of the tweet and manually categorizing positive and negative classes, where 1 is negative, 2 is positive. Labeling is carried out by 3 anatators who assess the contents of the tweet whether it contains hate speech or not.
|

LIBRARY

- library nltk (Natural Language Toolkit) is used for a wide range of natural language processing (NLP) tasks. Here are some common use cases where you can use the NLTK library in Pythontokenization, stemming, lemmatization, grammatical analysis, sentiment analysis, and others.
- library Sastrawi The "Sastrawi" library is a popular library for stemming Bahasa Indonesia words in Python. Stemming involves reducing words to their base or root form by removing suffixes and prefixes. This process is useful for text preprocessing in Indonesian text analysis and natural language processing (NLP) tasks.

- Library Pandas a popular library in the Python programming language used for data manipulation and analysis. Pandas provides an efficient and flexible data structure for working with tabular data (such as tables in a database or spreadsheet). The basic components of Pandas are series and data frames.
- Library numpy NumPy (Numerical Python) is a fundamental library in the Python ecosystem for numerical and mathematical computations. It provides support for working with arrays, matrices, mathematical functions, and more. NumPy forms the foundation for many other scientific and data manipulation libraries in Python
- Library re The re (regular expression) library in Python is used to manipulate and search text based on certain patterns called regular expressions
Reed Data

Calling Data on Google Drive and is continued by declaring negative and positive classes and calling data using pd from pandas to display data frames.

The Fleiss's Kappa calculations produce high accuracy indicating that the anatator process is quite good. and after that vote anantator get result negative 230 tweet and positive 170 tweet. about PPKM and PSBB.
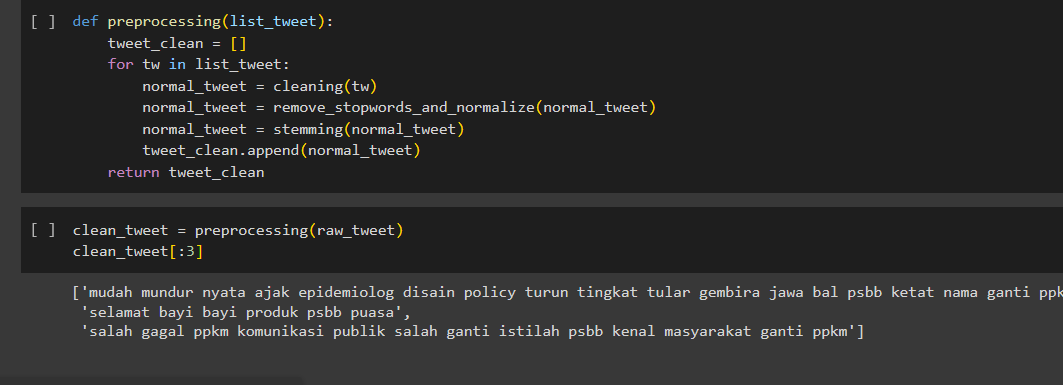
Preprocessing

Data cleaning is an important step in the data analysis process that involves identifying and correcting errors, inconsistencies, and inaccuracies in your dataset to ensure that it's accurate, reliable, and suitable for analysis. Data cleaning tasks can vary depending on the nature of the data and the specific issues present. Here are some common data cleaning tasks: deleted lowercase, url, username, hastag, and punctuation.

Remove Stopword and tokenisasi
Stopword Removal: NLTK includes a list of common stopwords (words that are often removed because they carry little meaning) for various languages. Removing stopwords can help improve the quality of text analysis.
Useful tokenization as a word separator. In addition, removing stopwords is done to remove the meaning of the same word. The tokenization process was carried out using the library from nltk, the stopword removal was carried out using a dictionary from previous research, the stopword dictionary was obtained from references to research conducted by Tala regarding stemming. Furthermore, the dictionary stands for Hakim's research on machine learning approaches. Alay dictionary obtained from research by Aliyah et al regarding the Colloquial Indonesian Lexicon

Stemming is done using literary literature to remove affixes to a word or spelled out as a change to a standard word.

The Result of Preprocessing.

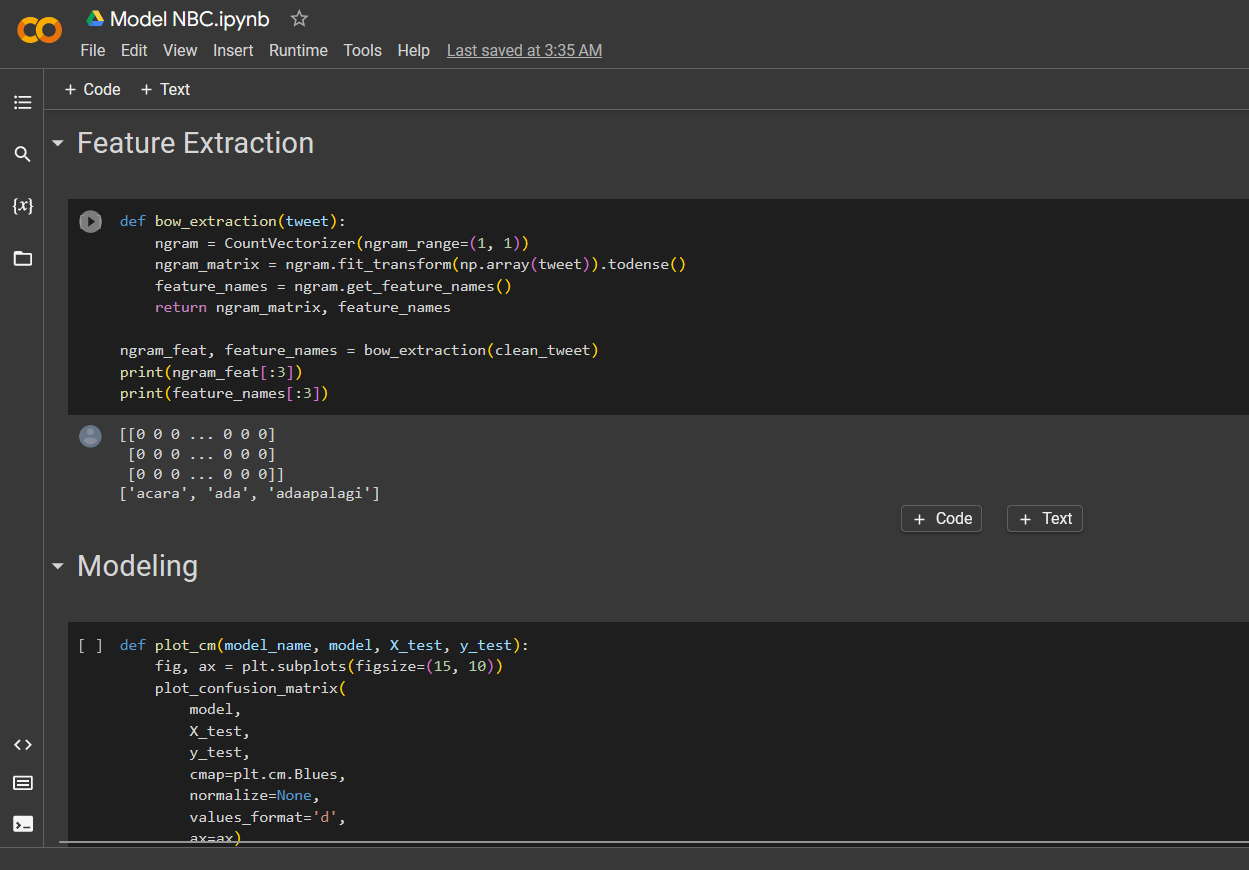
Feature Extraction

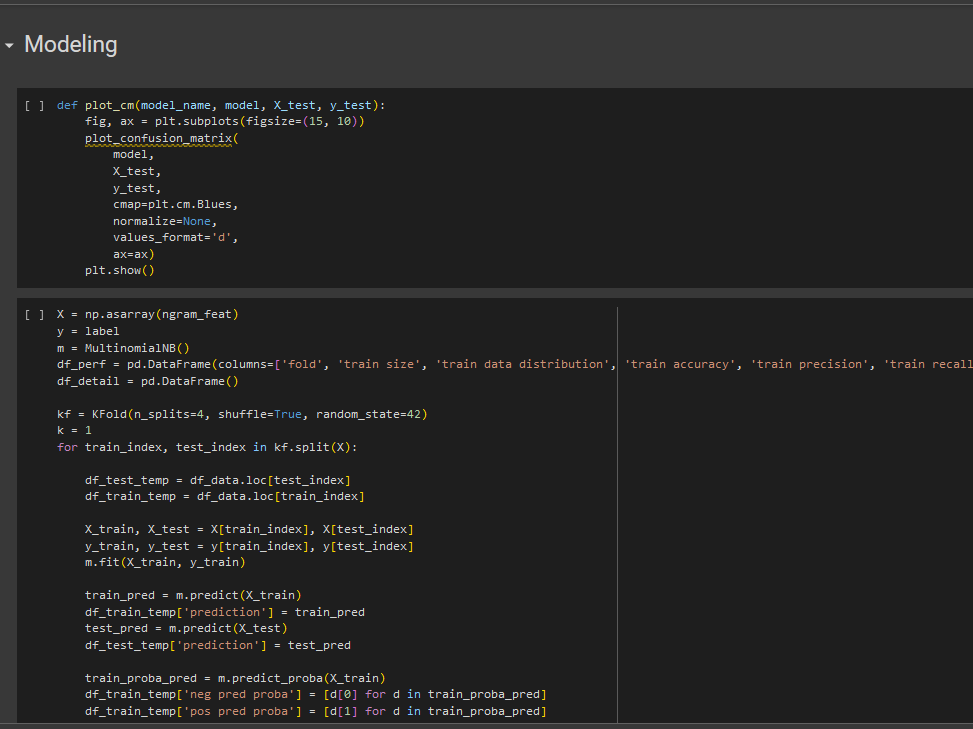
Modeling

Naive Bayes is a classification method based on Bayes' theorem, and it assumes that each feature (attribute) in the data is statistically independent of the others. MultinomialNB is specifically used when the data follows a multinomial distribution, as is the case in text classification tasks where each feature corresponds to the frequency of words in a document.

The results of this study are in the form of the accuracy value of the Naïve Bayes method as well as predictions of public opinion sentiment on social media Twitter regarding the government's social distancing policy, namely PSBB or PPKM. The testing phase is carried out with 400 data as a dataset, which will be split randomly in the program to obtain training and test data with a ratio of 300 and 100 where this test is obtained from the evaluation of the k = 4 fold model.

The calculation results from the accuracy value of the model made using the Naïve Bayes Classifier with k-fold cross validation with the accuracy calculation obtained from the confusion matrix component
From the test table above, it can be seen that in the fourth fold, the highest accuracy was obtained with an acquisition of 78%. With the average results of the 4 tests obtained an accuracy of 74.25%. So it can be concluded that the use of the Naïve Bayes model is considered quite good in sentiment analysis regarding government policies regarding social distancing directives with the PSBB or PPKM keyword tweets.
Based on the data used in this study, namely 400 data that has been selected for tweet data that is not spam, the positive class results are lower than the negative class. because there are still many violations committed by the community and they are considered indecisive, ineffective and keep repeating, making the community feel bored with the current situation. Meanwhile, positive sentiment was found that the community supported Government policies, be it PSBB or PPKM to reduce cases of the spread of the corona virus in Indonesia
Informasi Course Terkait
Kategori: Artificial IntelligenceCourse: Persiapan Ujian Sertifikasi Internasional DSBIZ - AIBIZ
