
Klasifikasi Text dengan NLP
Nova Enjelina Pakpahan



Summary
Portofolio ini adalah contoh penerapan mengklasifikasikan dokumen berita ke dalam kategori yang sesuai. Terdapat beberapa tahapan yang harus dilakukan dalam proyek ini. Tahap pertama adalah mengumpulkan dataset dokumen berita yang sudah dikategorikan. Dataset ini akan menjadi acuan untuk melatih dan menguji model klasifikasi yang akan dikembangkan. Dataset tersebut dapat diperoleh dari https://www.kaggle.com/datasets/amananandrai/ag-news-classification-dataset?resource=download.
Description
Dalam klasifikasi dokumen berita ini, terdapat beberapa langkah yang perlu dilakukan.
Pertama, perlu mengumpulkan dataset dokumen berita yang sudah dikategorikan. Dataset ini dapat ditemukan dari sumber terpercaya seperti Kaggle. Pastikan dataset memiliki kolom teks berita dan kolom kategori yang sesuai. Pada bagian ini, digunakan dataset yang diunduh melalui https://www.kaggle.com/datasets/amananandrai/ag-news-classification-dataset?resource=download.

Selanjutnya, dilakukan pemrosesan awal pada dataset. Pertama, perlu mengimpor pustaka NLTK dan modul-modul yang dibutuhkan. Kemudian, dataset dimuat ke dalam struktur data yang sesuai, misalnya dataframe. Selanjutnya, dapat dilakukan inspeksi dan eksplorasi dataset, seperti melihat jumlah sampel dalam setiap kategori.



Langkah berikutnya adalah melakukan preprocessing teks pada dataset. Pertama, dilakukan case folding dengan mengubah semua teks menjadi huruf kecil menggunakan fungsi lower(). Kemudian, dilakukan filtering dengan menghilangkan karakter khusus, tanda baca, dan simbol menggunakan metode regular expression atau fungsi str.replace(). Selanjutnya, dilakukan tokenizing dengan memecah teks menjadi kata-kata atau token menggunakan fungsi word_tokenize() dari NLTK. Setelah itu, dilakukan penghapusan stopwords dengan menghapus kata-kata yang umum dan tidak memberikan informasi penting menggunakan stopwords dari NLTK. Terakhir, dilakukan stemming atau lemmatization untuk mereduksi kata-kata ke bentuk dasar menggunakan teknik seperti stemming (misalnya, PorterStemmer dari NLTK) atau lemmatization (misalnya, WordNetLemmatizer dari NLTK).

Setelah melakukan preprocessing teks, perlu melakukan pembentukan fitur dengan mengonversi teks menjadi vektor numerik yang dapat digunakan oleh algoritma klasifikasi. Ada beberapa pendekatan yang dapat digunakan, seperti penghitungan frekuensi kata menggunakan CountVectorizer atau pembobotan TF-IDF (Term Frequency-Inverse Document Frequency) menggunakan TfidfVectorizer dari sklearn.feature_extraction.text.

Selanjutnya, dataset perlu dibagi menjadi subset train dan test menggunakan fungsi train_test_split() dari sklearn.model_selection. Subset train akan digunakan untuk melatih model klasifikasi.

Setelah itu, dapat dilakukan pememilihan algoritma klasifikasi yang sesuai, dan pada portofolio ini algoritma yang digunakan adalah Naive Bayes, yaitu Multinomial NB.

Untuk menyimpan hasil klasifikasi dalam file baru, dapat dilakukan langkah berikut:


Terakhir, dilakukan evaluasi performa model yang telah dilatih. Ini dilakukan dengan melakukan prediksi pada subset test menggunakan metode predict() atau predict_proba(). Selanjutnya, dihitung dan dilakukan analisis metrik evaluasi seperti akurasi, presisi, recall, dan F1-score menggunakan fungsi classification_report() dari sklearn.metrics.

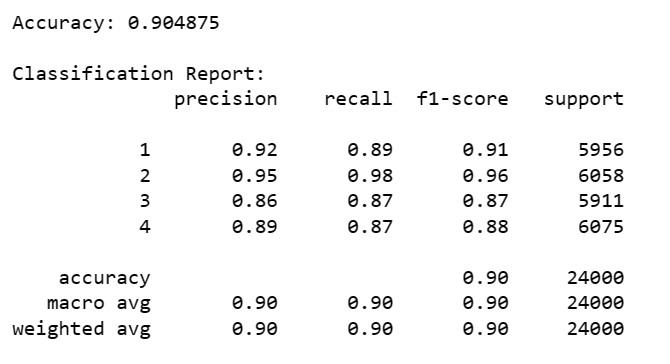
Berdasarkan hasil klasifikasi yang dilakukan, model klasifikasi dokumen berita memiliki tingkat akurasi sebesar 90.49%. Ini berarti model berhasil mengklasifikasikan sebagian besar dokumen dengan benar. Dalam Classification Report, precision mengukur sejauh mana dokumen yang diklasifikasikan sebagai kelas tertentu benar, recall mengukur sejauh mana model dapat mengidentifikasi dokumen yang sebenarnya termasuk dalam kelas tersebut, F1-score merupakan rata-rata harmonik dari precision dan recall, memberikan gambaran keseluruhan tentang kinerja model. Support adalah jumlah sampel dalam setiap kelas.

Classification Report menunjukkan, klasifikasi kelas 1 memiliki precision sebesar 0.92, recall sebesar 0.89, dan F1-score sebesar 0.91. Ini menunjukkan bahwa model mampu dengan baik mengidentifikasi dan mengklasifikasikan dokumen dalam kelas 1.
Klasifikasi kelas 2 memiliki precision sebesar 0.95, recall sebesar 0.98, dan F1-score sebesar 0.96. Ini menunjukkan bahwa model memiliki kinerja yang sangat baik dalam mengklasifikasikan dokumen dalam kelas 2.
Klasifikasi kelas 3 memiliki precision sebesar 0.86, recall sebesar 0.87, dan F1-score sebesar 0.87. Ini menunjukkan bahwa model mampu dengan baik mengidentifikasi dan mengklasifikasikan dokumen dalam kelas 3.
Klasifikasi kelas 4 memiliki precision sebesar 0.89, recall sebesar 0.87, dan F1-score sebesar 0.88. Ini menunjukkan bahwa model mampu dengan baik mengidentifikasi dan mengklasifikasikan dokumen dalam kelas 4.
Dengan demikian, berdasarkan hasil klasifikasi dan metrik evaluasi yang diberikan, dapat disimpulkan bahwa model klasifikasi dokumen berita yang dilakukan memiliki kinerja yang baik dalam mengklasifikasikan dokumen ke dalam kategori yang tepat.
Informasi Course Terkait
Kategori: Natural Language ProcessingCourse: Basic Text Processing



