
Sistem Rekomendasi Film menggunakan Neural Network
Nova Enjelina Pakpahan


Summary
Sistem rekomendasi film ini menggunakan Neural Networks bertujuan untuk memberikan rekomendasi film kepada pengguna berdasarkan preferensi mereka. Sistem ini dirancang untuk membantu pengguna menemukan film-film yang sesuai dengan minat dan selera mereka. Dengan menggunakan teknik Neural Networks, sistem mampu menganalisis informasi film seperti genre, sutradara, aktor, dan sinopsis untuk menghasilkan rekomendasi yang relevan. Pengguna dapat memberikan preferensi mereka, seperti genre film yang diminati atau beberapa film favorit yang telah ditonton, dan sistem akan menggunakan informasi tersebut sebagai dasar untuk menghasilkan rekomendasi film yang paling sesuai. Dengan demikian, sistem rekomendasi film ini bertujuan untuk meningkatkan pengalaman pengguna dalam menemukan film-film yang menarik dan sesuai dengan minat mereka.
Description
Untuk membuat sistem rekomendasi film ini, dapat dilakukan langkah-langkah berikut:
Pengumpulan Data
Untuk membangun sistem rekomendasi film menggunakan Neural Networks, langkah pertama adalah dengan mengumpulkan data film yang mencakup informasi seperti judul, genre, sutradara, aktor, sinopsis, dan atribut lainnya yang relevan. Ada beberapa cara yang dapat digunakan untuk mengumpulkan data ini:
- Basis Data Film: Basis data yang digunakan bisa menggunakan basis data film yang sudah tersedia, seperti IMDb, TMDb, atau situs sejenisnya. Basis data ini menyediakan informasi lengkap tentang film-film termasuk judul, genre, sutradara, aktor, sinopsis, dan atribut lainnya. Kita dapat mengunduh dataset yang tersedia secara publik atau menggunakan API (Application Programming Interface) yang disediakan oleh platform tersebut untuk mengakses data secara programatik.
- Platform Streaming: Platform streaming seperti Netflix, Amazon Prime Video, atau Hulu menyediakan data film yang dapat digunakan untuk sistem rekomendasi. Beberapa platform streaming memiliki API yang memungkinkan akses ke data film mereka, termasuk informasi tentang judul, genre, sutradara, aktor, sinopsis, dan atribut lainnya. Dengan menggunakan API ini, kita dapat mengumpulkan data secara otomatis dan menyimpannya untuk penggunaan dalam sistem rekomendasi.
- Web Scraping: Teknik web scraping dapat digunakan untuk mengumpulkan data film dari situs web yang menyediakan informasi tentang film. Dengan menggunakan library atau framework web scraping seperti BeautifulSoup atau Scrapy, kita dapat mengambil informasi film dari halaman web, termasuk judul, genre, sutradara, aktor, sinopsis, dan atribut lainnya.
Persiapan Data
Setelah mengumpulkan data film, langkah selanjutnya adalah melakukan persiapan data sebelum melatih model Neural Networks. Berikut adalah langkah yang perlu dilakukan:
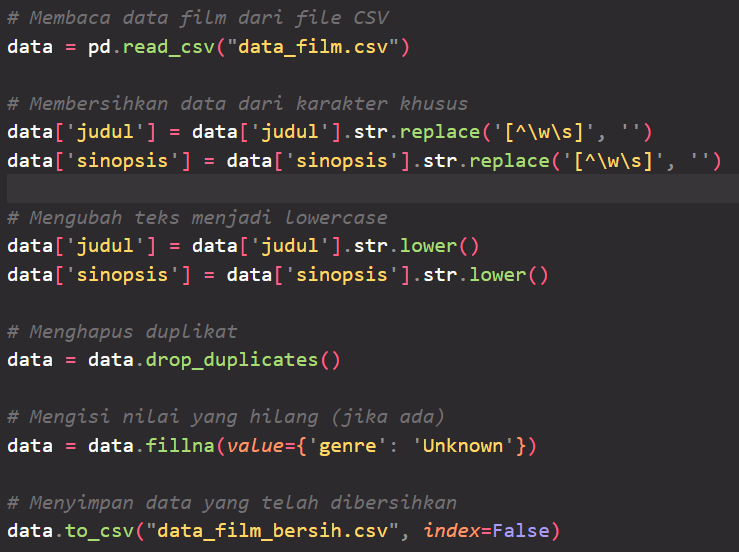
Pembersihan Data:
- Menghapus karakter khusus atau simbol yang tidak relevan dari data, seperti tanda baca atau emotikon.
- Mengubah teks menjadi lowercase untuk menghindari perbedaan penulisan yang tidak perlu.
- Menghapus duplikat jika ada entri yang sama dalam dataset.
- Mengisi atau menghapus nilai yang hilang (missing values) jika ada. Jika terdapat atribut yang penting dan memiliki banyak nilai yang hilang, dapat dilakukan teknik pengisian nilai yang sesuai seperti menggunakan nilai rata-rata atau modus.

. Pembagian Data:
Setelah melakukan pembersihan data, langkah selanjutnya adalah membagi data menjadi set latihan (training set) dan set pengujian (test set). Set latihan digunakan untuk melatih model Neural Networks, sedangkan set pengujian digunakan untuk menguji kinerja model yang telah dilatih. Biasanya, data dibagi dalam perbandingan 70:30 atau 80:20, di mana 70% atau 80% data digunakan sebagai set latihan dan sisanya digunakan sebagai set pengujian.

Representasi Data
Untuk melatih model Neural Networks pada sistem rekomendasi film, kita perlu mengonversi data film ke dalam representasi yang dapat diproses oleh model tersebut. Berikut adalah beberapa langkah untuk mengubah data film menjadi representasi yang sesuai:
1. Representasi Atribut Diskret (Categorical):
Judul film, genre, sutradara, aktor, dan atribut diskret lainnya dapat diubah menjadi representasi numerik menggunakan pendekatan seperti one-hot encoding. Kemudian one-hot encoding mengubah setiap nilai unik dalam atribut menjadi vektor biner dengan panjang yang sesuai, di mana hanya satu elemen vektor yang bernilai 1 untuk menunjukkan kehadiran atribut tersebut. Misalnya, jika terdapat 3 genre film (komedi, drama, aksi), maka atribut genre dapat diubah menjadi [1, 0, 0] untuk komedi, [0, 1, 0] untuk drama, dan [0, 0, 1] untuk aksi.
2. Representasi Sinopsis (Textual):
Sinopsis film, yang berbentuk teks, dapat direpresentasikan menggunakan teknik word embedding. Word embedding akan mengonversi kata-kata dalam sinopsis menjadi vektor numerik dengan dimensi tertentu. Teknik populer untuk word embedding seperti Word2Vec dan GloVe dapat digunakan dalam bagian ini. Word2Vec dan GloVe mempelajari representasi vektor kata berdasarkan konteks kata di dalam korpus teks yang luas. Dengan menggunakan model Word2Vec atau GloVe yang telah dilatih sebelumnya, setiap kata dalam sinopsis dapat direpresentasikan sebagai vektor numerik.

Pembangunan Model
Untuk membangun model Neural Networks pada sistem rekomendasi film, kita dapat menggunakan arsitektur Artificial Neural Network (ANN) dengan beberapa lapisan tersembunyi. Berikut adalah beberapa langkah untuk membangun model:
1. Penentuan Jumlah dan Ukuran Lapisan Tersembunyi:
Jumlah lapisan tersembunyi dan ukuran setiap lapisan tergantung pada kompleksitas masalah dan ketersediaan data. Jumlah lapisan tersembunyi yang umum digunakan adalah antara 1 hingga 3 lapisan. Ukuran lapisan tersembunyi biasanya merupakan bilangan bulat yang meningkat secara bertahap, misalnya, ukuran yang lebih kecil pada lapisan depan dan ukuran yang lebih besar pada lapisan belakang. Ukuran lapisan tersembunyi ini juga dapat diatur melalui eksperimen dan penyetelan (tuning) model untuk mencapai performa yang optimal.
2. Fungsi Aktivasi:
Fungsi aktivasi digunakan untuk memperkenalkan non-linearitas ke dalam model. Fungsi aktivasi yang umum digunakan adalah ReLU (Rectified Linear Unit) pada lapisan tersembunyi dan sigmoid atau softmax pada lapisan output, tergantung pada jenis masalah (regresi atau klasifikasi). ReLU merupakan fungsi yang mengaktifkan nilai positif menjadi nilainya sendiri dan mengubah nilai negatif menjadi nol, yaitu f(x) = max(0, x). Fungsi sigmoid digunakan untuk masalah biner (klasifikasi dua kelas) dan softmax digunakan untuk masalah multikelas (klasifikasi lebih dari dua kelas).
3. Regularisasi dan Penghindaran Overfitting:
Untuk mencegah overfitting, dapat menggunakan teknik seperti dropout dan normalisasi batch (batch normalization). Dropout adalah teknik di mana sebagian node (neuron) pada lapisan tersembunyi diabaikan secara acak selama proses pelatihan, sehingga mencegah kelebihan ketergantungan pada node tertentu.

Dalam contoh di atas, model Sequential diinisialisasi dan lapisan tersembunyi ditambahkan dengan fungsi aktivasi ReLU. Dropout digunakan untuk mencegah overfitting dan BatchNormalization digunakan untuk normalisasi batch. Lapisan output menggunakan fungsi aktivasi softmax untuk masalah klasifikasi multikelas. Model dikompilasi dengan fungsi loss categorical_crossentropy (untuk klasifikasi multikelas) dan optimizer adam.
Pelatihan Model
Untuk melatih model Neural Networks pada sistem rekomendasi film, kita dapat mengikuti langkah-langkah berikut:
1. Definisikan Fungsi Loss:
Langkah pertama dilakukan dengan memilih fungsi loss yang sesuai dengan jenis masalah yang sedang dihadapi. Misalnya, untuk klasifikasi multikelas, fungsi loss yang umum digunakan adalah categorical cross-entropy. Fungsi loss berfungsi untuk mengukur sejauh mana prediksi model mendekati nilai target yang sebenarnya.
2. Pilih Algoritma Optimasi:
Kemudian pilih algoritma optimasi yang akan digunakan untuk memperbarui bobot model berdasarkan nilai loss. Beberapa algoritma yang umum digunakan adalah Stochastic Gradient Descent (SGD), Adam, dan RMSprop. Selanjutnya, setel parameter-parameter algoritma optimasi, seperti learning rate, momentum, dan lainnya, sesuai dengan karakteristik data dan masalah yang dihadapi.
3. Tentukan Metrik Evaluasi:
Pilih metrik evaluasi yang relevan untuk memantau kinerja model selama pelatihan. Misalnya, untuk masalah klasifikasi, metrik seperti akurasi, presisi, recall, dan F1-score dapat digunakan. Metrik evaluasi membantu memahami seberapa baik model melakukan prediksi dan apakah model sedang memperoleh performa yang diharapkan.
4. Latih Model:
Dalam pelatihan model, atur jumlah epoch (iterasi) yang sesuai. Epoch mengindikasikan berapa kali seluruh dataset akan dilewati selama pelatihan. Atur ukuran batch yang sesuai. Batch adalah sejumlah sampel yang digunakan untuk menghitung nilai loss dan memperbarui bobot model dalam satu iterasi. Latih model dengan menjalankan iterasi berulang menggunakan data latihan. Dalam setiap epoch, hitung nilai loss menggunakan fungsi loss yang telah ditentukan. Lakukan proses backpropagation untuk memperbarui bobot model berdasarkan nilai loss yang dihasilkan. Evaluasi model menggunakan metrik evaluasi yang telah ditentukan pada set latihan ditentukan pada set latihan.

Dalam contoh di atas, model dikompilasi dengan fungsi loss categorical_crossentropy, algoritma optimasi Adam, dan metrik evaluasi akurasi. Model dilatih menggunakan metode fit dengan jumlah epoch 10 dan ukuran batch 32. Data latihan dan data validasi (untuk evaluasi model selama pelatihan) diberikan melalui argumen X_train, y_train, X_val, dan y_val. Penyetelan parameter seperti jumlah epoch, ukuran batch, dan algoritma optimasi dapat disesuaikan berdasarkan karakteristik data dan performa model yang diinginkan.
Evaluasi Model
Untuk mengevaluasi kinerja model pada set pengujian, dapat melakukan langkah-langkah berikut:
1. Menggunakan Model untuk Memprediksi:
Gunakan model yang telah dilatih untuk melakukan prediksi pada data pengujian. Jika menggunakan library seperti Keras, dapat menggunakan metode 'model.predict()' untuk memperoleh prediksi dari model.
2. Hitung Metrik Evaluasi:
Gunakan metrik evaluasi yang telah ditentukan sebelumnya, seperti akurasi, F1-score, atau metrik lain yang relevan dengan masalah yang dihadapi. Misalnya, untuk sistem rekomendasi film, kita dapat menggunakan metrik seperti precision, recall, atau Mean Average Precision (MAP) jika data pengujian dilengkapi dengan peringkat atau preferensi pengguna.
3. Analisis Hasil Evaluasi:
Pada bagian ini, analisis hasil evaluasi untuk memahami sejauh mana model memberikan rekomendasi film yang akurat. Perhatikan juga metrik evaluasi yang dihasilkan untuk memperoleh gambaran kinerja model secara keseluruhan. Lalu periksa apakah metrik evaluasi memenuhi tujuan yang telah ditentukan sebelumnya. Misalnya, apakah akurasi sudah mencapai tingkat yang diharapkan atau apakah F1-score sudah memadai. Selain itu, perhatikan juga perbedaan antara kinerja model pada set latihan dan set pengujian. Jika terdapat perbedaan yang signifikan, bisa jadi model mengalami overfitting pada data latihan.

Dalam contoh di atas, model dievaluasi menggunakan metode 'evaluate()' dengan menggunakan data pengujian (X_test dan y_test). Nilai loss dan akurasi model akan dicetak untuk memberikan informasi tentang kinerja model pada set pengujian. Selain itu, dapat juga melakukan analisis lebih lanjut seperti memvisualisasikan metrik evaluasi, membandingkan kinerja model dengan baseline, atau melakukan analisis kesalahan (misalnya, melihat prediksi yang salah) untuk memperbaiki model jika diperlukan.
Pemberian Rekomendasi
Setelah model dilatih dan dievaluasi, langkah selanjutnya adalah menggunakan model tersebut untuk memberikan rekomendasi film kepada pengguna. Berikut adalah detailnya:
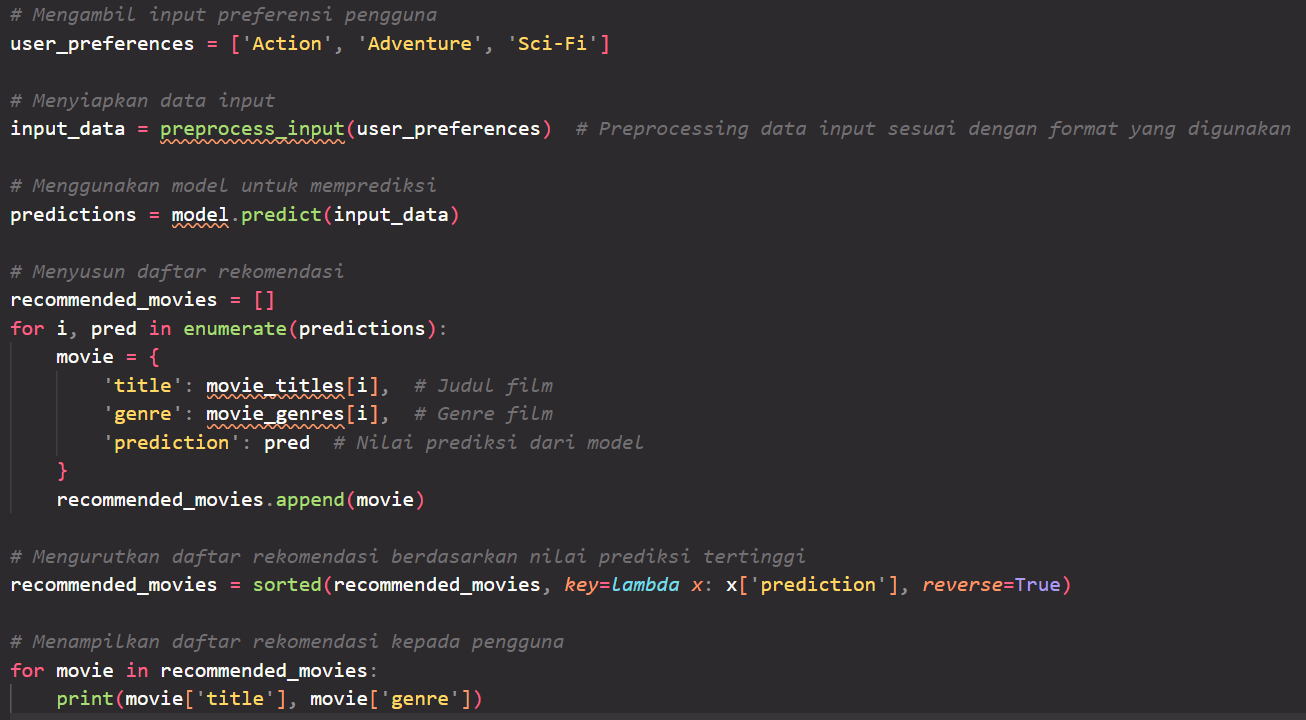
1. Input Preferensi Pengguna:
Dalam pemberian rekomendasi, hal awal yang perlu dilakukan adalah meminta pengguna untuk memberikan preferensi mereka, misalnya genre film yang diminati atau beberapa film favorit yang telah ditonton. Informasi ini digunakan sebagai input untuk mendapatkan rekomendasi yang sesuai dengan preferensi pengguna.
2. Menyiapkan Data Input:
Jika data input sudah diperoleh, konversikan input preferensi pengguna ke dalam representasi yang dapat diproses oleh model. Misalnya, jika menggunakan teknik seperti one-hot encoding untuk genre film, konversikan preferensi pengguna menjadi vektor one-hot encoding yang sesuai dengan fitur genre yang ada.
3. Gunakan Model untuk Memprediksi:
Gunakan model yang telah dilatih untuk melakukan prediksi pada data input preferensi pengguna. Jika menggunakan library seperti Keras, kita dapat menggunakan metode 'model.predict()' untuk memperoleh prediksi dari model.
4. Menyusun Daftar Rekomendasi:
Gunakan nilai prediksi yang dihasilkan oleh model untuk menyusun daftar film yang direkomendasikan. Jangan lupa prioritaskan film-film yang memiliki nilai prediksi tertinggi sebagai rekomendasi utama. Dapat juga mempertimbangkan untuk menerapkan beberapa aturan atau filter tambahan, seperti memastikan bahwa film-film yang direkomendasikan tidak termasuk dalam daftar film yang sudah ditonton oleh pengguna.

Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Speech Classification Menggunakan Deep Neural Network

