
Emotion Speech Feature Extraction
Ghazi Taqiyya Al Anshari

Summary
Dalam penerapan machine learning untuk pengenalan suara penting untuk melakukan ekstraksi data audio yang kita miliki. Hal tersebut karena model machine learning tidak dapat memproses data mentah dalam bentuk audio. Oleh karena itu, kemampuan untuk mengekstraksi fitur ucapan sangat penting sebelum mendalami speech recognition. Disini saya berhasil melakukan ekstraksi pada kumpulan data audio yang mengandung beberapa jenis emosi. Dengan hasil ekstraksi ini, sangat mungkin untuk digunakan dalam machine learning khususnya untuk emotion recognition.
Description
Mengapa Perlu Mengekstraksi Fitur Audio untuk Machine Learning?
Pernah berfikir bagaimana membuat sebuah model machine learning dengan data audio? apakah bisa data audio langsung dilatih dalam model machine learning? jawabannya tentu saja tidak bisa. Model machine learning hanya bisa mengolah data-data numerik saja. Lalu, bagaimana perusahaan-perusahaan diluar sana membuat aplikasi untuk mendeteksi suara? bukankah mereka membuat model menggunakan data audio yang mereka miliki?. Mereka dapat membuat model-model tersebut menggunakan kumpulan data audio yang telah mereka ekstraksi fitur-fiturnya. Fitur-fitur tersebut berupa kumpulan data angka yang kemudian bisa digunakan untuk melatih model yang mereka miliki. Sederhananya itulah perlunya kita mengekstraksi data audio sebelum memasukkannya kedalam model machine learning.
Fitur-Fitur Audio
Disini saya melakukan ekstraksi fitur dari beberapa data audio yang berasal dari Course Speech Feature Extraction BISA AI Academy. Data audio tersebut berisi ucapan dengan beberapa emosi seperti marah, bahagis, dan sedih. Beberapa fitur yang berhasil dari audio tersebut antara lain
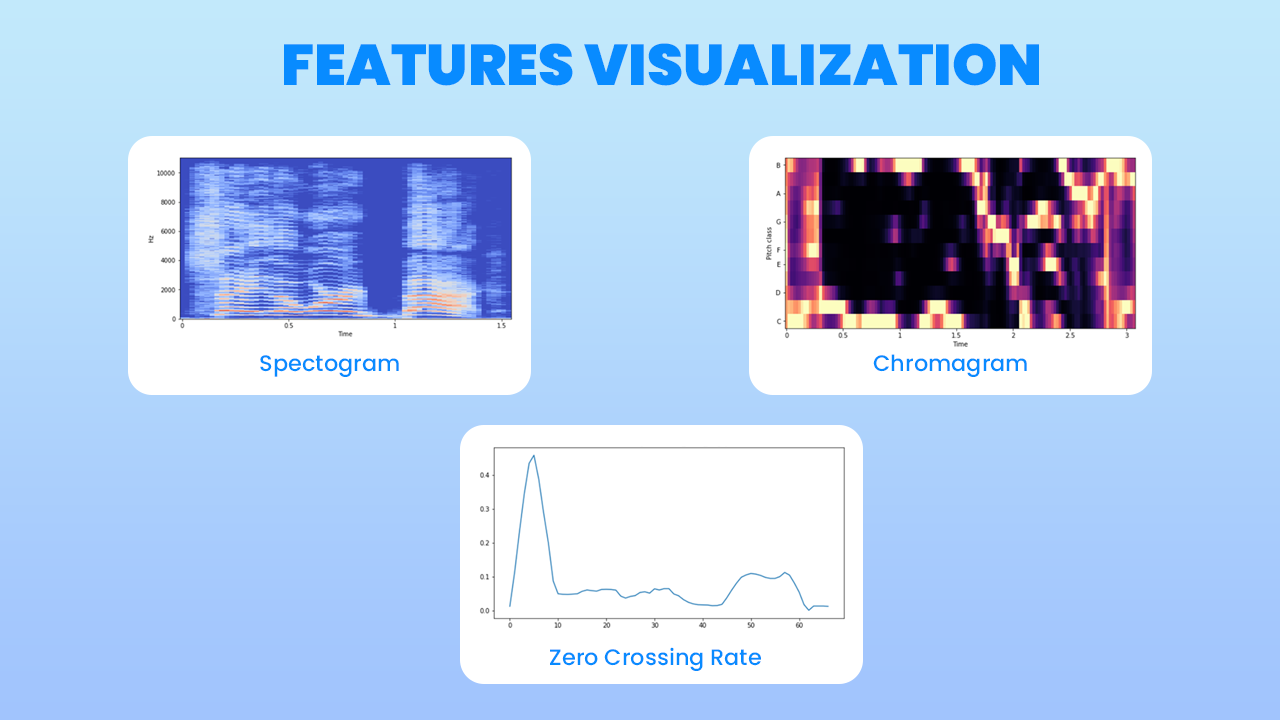
- Chromagram : chroma feature atau chromagram berkaitan erat dengan dua belas kelas nada yang berbeda. Fitur berbasis Chroma, yang juga disebut sebagai "profil kelas nada", adalah alat yang ampuh untuk menganalisis musik yang nadanya dapat dikategorikan secara bermakna (sering kali menjadi dua belas kategori) dan yang penyetelannya mendekati skala nada yang sama.
- Zero Crossing Rate (ZCR) : tingkat di mana sinyal berubah dari positif ke nol ke negatif atau dari negatif ke nol ke positif. Nilainya telah banyak digunakan baik dalam pengenalan suara dan pengambilan informasi musik, menjadi fitur utama untuk mengklasifikasikan suara perkusi.
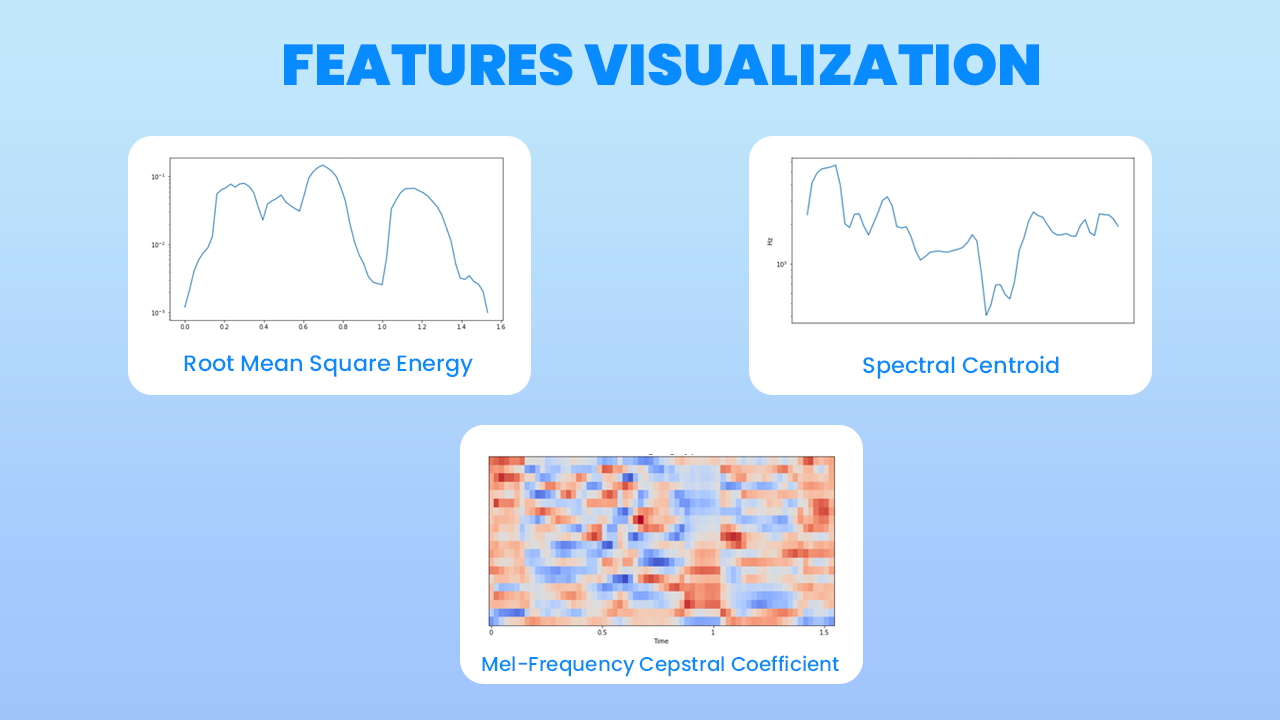
- Root Mean Square Energy (RMSE) : energi sinyal sesuai dengan besaran total sinyal. Untuk sinyal audio, itu kira-kira sesuai dengan seberapa keras sinyalnya.
- Spectral Centroid : ukuran yang digunakan dalam pemrosesan sinyal digital untuk mengkarakterisasi spektrum. Ini menunjukkan di mana pusat massa spektrum berada. Secara persepsi, ini memiliki hubungan yang kuat dengan kesan kecerahan suara.
- Mel-Frequency Cepstral Coefficient (MFCC) : pada dasarnya mencakup windowing sinyal, menerapkan DFT, mengambil log besarnya, dan kemudian membelokkan frekuensi pada skala Mel, diikuti dengan menerapkan kebalikan DCT
Tools
Beberapa tools yang saya gunakan dalam proses ekstraksi meliputi
- Bahasa pemrograman Python
- Library Librosa
Hasil
Hasil dataset fitur-fitur tersebut dapat diakses pada laman saya di platform Kaggle pada link dibawah ini.
Dataset : https://www.kaggle.com/datasets/taqiyyaghazi/emotion-speech-features-for-speech-recognition
Informasi Course Terkait
Kategori: Speech ProcessingCourse: Feature Extraction Speech



