
Implementasi MPI pada Perkalian Matriks
Bagas Muharom

Summary
Message Passing Interface (MPI) adalah sebuah standar yang digunakan untuk melakukan komunikasi antara proses pada sistem komputasi paralel. MPI memungkinkan beberapa proses berjalan secara bersamaan pada banyak komputer yang terhubung dalam jaringan, dan saling berkomunikasi untuk menyelesaikan tugas-tugas yang diberikan. Dengan menggunakan MPI, program paralel dapat dibuat lebih efisien dan cepat, karena tugas yang dibagi menjadi beberapa proses dapat diselesaikan secara bersamaan.
Perkalian matriks dapat diimplementasikan dengan menggunakan program paralel untuk mempercepat waktu eksekusi. Metode program paralel dapat dilakukan dengan membagi tugas perkalian matriks ke dalam beberapa tugas kecil yang dapat dijalankan secara simultan pada beberapa prosesor atau komputer yang terhubung ke jaringan
Description
A. Pendahuluan
Program ini merupakan implementasi MPI pada HPC dalam kasus perkalian matriks menggunakan bahasa pemrograman C. Operasi perkalian matriks melibatkan dua buah matriks yang mempunyai kolom matriks pertama yang sama dengan baris matriks kedua. Operasi dilakukan pada baris matriks pertama dengan kolom matriks kedua yang tidak bergantung pada baris dan kolom yang lain sehingga perkalian matriks ini memiliki kesempatan untuk di implementasikannya komputasi paralel.
Penjalasan dan tahap-tahap dasar program:
- Program dijalankan menggunakan 4 prosessor.
- User memasukkan jumlah baris dan kolom dari kedua matriks. Dimasukkan matriks pertama 760x760 dan matriks kedua 760x760.
- Elemen-elemen matriks di random.
- Baris dari matriks pertama dibagi ratakan ke seluruh prosessor.
- Matriks kedua di broadcast ke seluruh prosessor.
- Operasi perkalian dilaksanakan pada masing-masing prosessor.
- Hasil operasi dikumpulkan ke root prosessor.
Material dan spesifikasi yang digunakan:
- Komputer Quad-core 3.10 GHz
- Linux Mint 21.1 Cinnamon
- OpenMPI 4.1.5
- Gcc compiler 11.3.0
B. Koding Program
1. Perkalian matriks sekuensial (tanpa komputasi paralel)
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(){
int m, n, p, q, i, j, k;
clock_t start_time, end_time;
double cpu_time_used;
printf("\n--- Perkalian Matriks --- \n");
// Input matriks A dan B
printf("\nMasukkan jumlah baris matriks A: ");
fflush(stdout);
scanf("%d", &m);
printf("Masukkan jumlah kolom matriks A: ");
fflush(stdout);
scanf("%d", &n);
fflush(stdout);
printf("Masukkan jumlah baris matriks B: ");
fflush(stdout);
scanf("%d", &p);
printf("Masukkan jumlah baris matriks B: ");
fflush(stdout);
scanf("%d", &q);
if (n != p) {
printf("Error: jumlah baris matriks A tidak sama dengan jumlah kolom matriks.\n");
return 1;
}
start_time = clock();
int A[m][n], B[p][q], C[m][q];
srand(time(NULL));
printf("\nMatrix A:\n");
for (i = 0; i < m; i++) {
for (j = 0; j < n; j++) {
A[i][j] = rand() % 10;
printf("%d\t", A[i][j]);
}
printf("\n");
}
printf("\nMatrix B:\n");
for (i = 0; i < p; i++) {
for (j = 0; j < q; j++) {
B[i][j] = rand() % 10;
printf("%d\t", B[i][j]);
}
printf("\n");
}
for (i = 0; i < m; i++) {
for (j = 0; j < q; j++) {
C[i][j] = 0;
for (k = 0; k < n; k++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
end_time = clock();
// Display the resulting matrix C
printf("\nMatrix C = A * B:\n");
for (i = 0; i < m; i++) {
for (j = 0; j < q; j++) {
printf("%d\t", C[i][j]);
}
printf("\n");
}
cpu_time_used = ((double) (end_time - start_time)) / CLOCKS_PER_SEC;
printf("Total waktu komputasi: %f detik\n", cpu_time_used);
return 0;
}
2. Perkalian Matriks Paralel
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(int argc, char** argv) {
MPI_Init(&argc, &argv); // Inisialisasi MPI
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int m, n, p, q, i, j, k;
double start_time, end_time, total_time;
if (rank == 0){
printf("\n--- Implementasi Perkalian Matriks menggunakan Message Passing Interface pada HPC --- \n");
printf("\n------------------------------------------------");
printf("\nJumlah baris matriks A = jumlah kolom matriks B\n");
printf("------------------------------------------------\n");
// Input matriks A dan B
printf("\nMasukkan jumlah baris matriks A: ");
fflush(stdout);
scanf("%d", &m);
printf("Masukkan jumlah kolom matriks A: ");
fflush(stdout);
scanf("%d", &n);
fflush(stdout);
printf("Masukkan jumlah baris matriks B: ");
fflush(stdout);
scanf("%d", &p);
printf("Masukkan jumlah baris matriks B: ");
fflush(stdout);
scanf("%d", &q);
if (n != p) {
printf("Error: jumlah baris matriks A tidak sama dengan jumlah kolom matriks B.\n");
return 1;
}
start_time = MPI_Wtime(); // mulai merekam waktu
// processor 0 melakukan broadcast variable m, n, p dan q
MPI_Bcast(&m, 1, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Bcast(&p, 1, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Bcast(&q, 1, MPI_INT, 0, MPI_COMM_WORLD);
}
else{
// processor 1, 2 dan 3 menerima broadcast
// variable m, n, p dan q
MPI_Bcast(&m, 1, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Bcast(&p, 1, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Bcast(&q, 1, MPI_INT, 0, MPI_COMM_WORLD);
}
// membagi baris matriks A untuk diproses lebih lanjut
// oleh semua processor
int baris_per_proses = m / size;
int A[m][n], B[p][q], C[m][q], A_lokal[baris_per_proses][n], C_lokal[baris_per_proses][q];
if (rank == 0){
srand(time(NULL));
for (i = 0; i < m; i++) { // membuat random elemen matriks A
for (j = 0; j < n; j++) {
A[i][j] = rand() % 10;
}
}
for (i = 0; i < p; i++) { // membuat random elemen matrik B
for (j = 0; j < q; j++) {
B[i][j] = rand() % 10;
}
}
}
// processor 0 membagi ratakan baris matriks A kepada semua processor
MPI_Scatter(A, baris_per_proses*n, MPI_INT, A_lokal, baris_per_proses*n, MPI_INT, 0, MPI_COMM_WORLD);
// processor 0 melakukan broadcast matriks B kesemua processor
MPI_Bcast(&B, p*q, MPI_INT, 0, MPI_COMM_WORLD);
// melakukan operasi perkalian matriks pada masing-masing processor
for (i = 0; i < baris_per_proses; i++) {
for (j = 0; j < q; j++) {
C_lokal[i][j] = 0;
for (k = 0; k < n; k++) {
C_lokal[i][j] += A_lokal[i][k] * B[k][j];
}
}
}
// processor 0 mengumpulkan semua matriks dari pekerjaan processor lain dan menjadikannya matriks C
MPI_Gather(C_lokal, baris_per_proses*q, MPI_INT, C, baris_per_proses*q, MPI_INT, 0, MPI_COMM_WORLD);
if (rank == 0){
end_time = MPI_Wtime(); // berhenti merekam waktu
total_time = end_time - start_time;
printf("\nMatriks A: \n"); // menampilkan matriks A, B dan C
for (i = 0; i < m; i++) {
for (j = 0; j < n; j++) {
printf("%d\t", A[i][j]);
}
printf("\n");
}
printf("\nMatriks B: \n");
for (i = 0; i < p; i++) {
for (j = 0; j < q; j++) {
printf("%d\t", B[i][j]);
}
printf("\n");
}
printf("\nMatriks C = A * B: \n");
for (i = 0; i < m; i++) {
for (j = 0; j < q; j++) {
printf("%d\t", C[i][j]);
}
printf("\n");
}
}
if (rank==0){
// menampilkan total waktu eksekusi program
printf("\nTotal waktu komputasi: %f detik\n\n", total_time);
}
MPI_Finalize(); //MPI berakhir
return 0;
}
C. Hasil Keluaran Program
1. Perkalian Matriks sekuensial


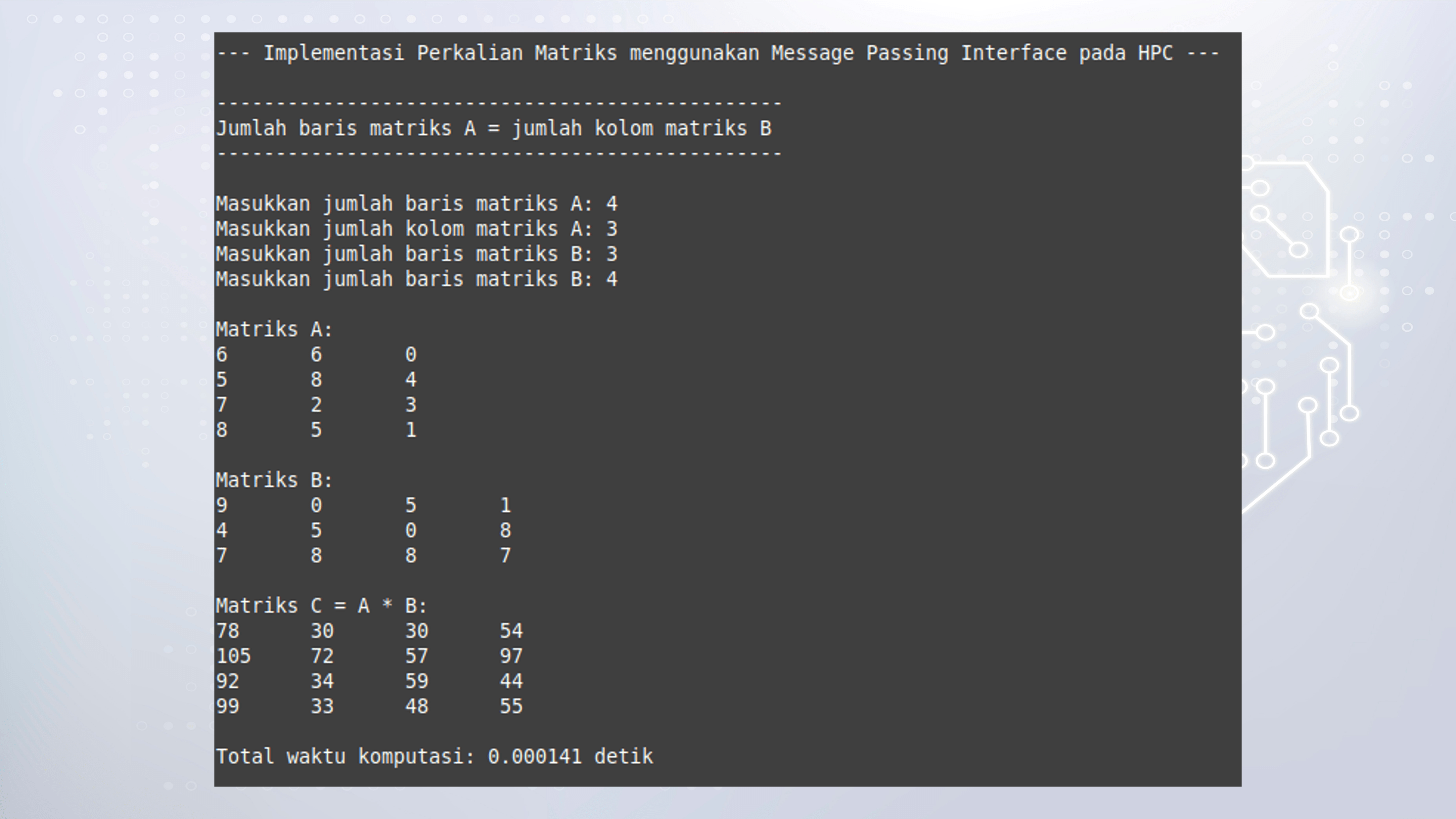
2. Perkalian Matriks Paralel


D. Evaluasi Performa
Performa diuji menggunakan dimensi matriks 760x760 dengan merekam waktu komputasi sekuensial dan komputasi paralel.
1. Speedup


2. Efisiensi


3. Cost


Informasi Course Terkait
Kategori: Artificial IntelligenceCourse: High Performance Computing (HPC) dengan MPI



