
Classfication Credit Card Fraud Detection Using RF
WEGA AQVIRANDY


Summary
Summary
This portfolio discusses the classification of Credit Card Fraud Detection using machine learning algorithms. The dataset consists of credit card transactions, with class 0 representing non-fraudulent transactions and class 1 representing fraudulent transactions. the portfolio showcases a highly accurate credit card fraud detection model, with excellent performance in identifying non-fraudulent transactions and a good level of detection for fraudulent transactions. The overall accuracy of the model is 1.00, indicating that it correctly classified the majority of the credit card transactions. The macro-average F1-score, which considers the overall performance across both classes, is 0.93, demonstrating a high level of accuracy and effectiveness in detecting credit card fraud.
Description
Description
Classification Of “creditcard.csv” Using Random Forest Classifier
I will be using a dataset called "Credit Card Fraud Detection" obtained from Kaggle.com. The dataset consists of credit card transactions, where each transaction is labeled as either fraudulent or non-fraudulent. The classification is based on a set of explanatory attributes or predictor variables. To demonstrate this, we will start by loading the data into a Pandas Data Frame and then display the contents of the dataset.

Here is an example program to use VS Code and import the required modules, namely the pandas module and give it the alias pd. Next, we will read the "vertebrate.csv" data that has been downloaded from Kaggle:

The program above is used to display the data set that has been read, so that the reader can know the contents of the data set.
Next, we can separate features and labels (targets), feature normalization using StandardScaler, and split the data into training and testing sets.

By separating features and labels, we can use the features in “X” to train the model and predict the label values using "y", then, normalizing the features ensures that the scale or range of values of the features does not affect the performance of the model to be trained and help in the learning process,
the last one splitting the data into training("X_train" and "y_train") and testing sets ("X_test and" "y_test") with proportion of test data using test_size=0.2 and random_state=42 to set the seed so that data sharing can be reproduced to perform model performance evaluation on data that has never been seen before.
The next step is to apply a classifying algorithm, also known as a random forest classifier.

In this step, we initialize the Random Forest model using the “RandomForestClassifier” class and set “random_state=42” to produce reproducible results. Next, the model is trained using the training data set ("X_train" and “y_train”).

In this step, we use the pre-trained Random Forest model to make predictions on the test data (X_test). The result of this prediction is stored in the variable "y_pred"
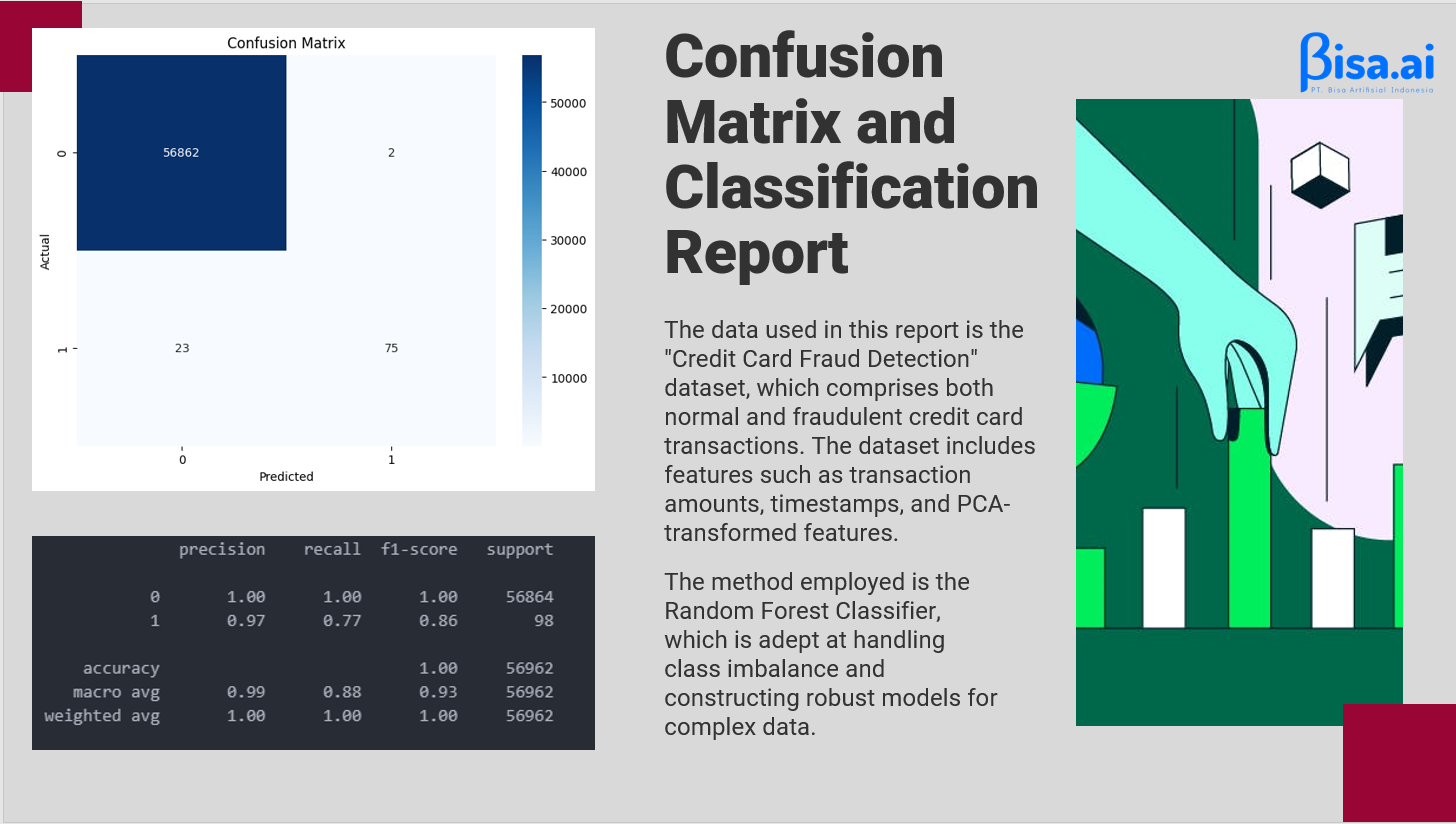
Next, we create a Confusion Matrix graph to visualize the prediction results and gain an understanding of the extent to which the model can correctly predict the true class and the false class.


The model correctly predicted 56862 instances as positive (Class 0) and predicted 2 instances as positive (Class 0) when they were actually negative (Class 0). The model incorrectly predicted 23 instances as negative (Class 1) when they were actually positive (Class 0) and correctly predicted 75 instances as negative (Class 1).
Next step is to evaluate the performance of the model using the classification report. Classification report is an evaluation metric that provides detailed information about the performance of the classification model, including precision, recall, f1-score, and support for each class.

The model achieved a precision of 1.00 for class 0 (non-fraudulent transactions), indicating that all predicted non-fraudulent transactions were indeed non-fraudulent. For class 1 (fraudulent transactions), the precision was 0.97, indicating that 97% of the predicted fraudulent transactions were correctly classified.
The recall for class 0 was 1.00, indicating that all actual non-fraudulent transactions were correctly identified. For class 1, the recall was 0.77, indicating that 77% of the actual fraudulent transactions were detected by the model
The F1-score for class 0 was 1.00, indicating a perfect balance between precision and recall. The F1-score for class 1 was 0.86, representing a harmonic mean between precision and recall.
Support: The support indicates the number of instances in each class. There were 56,864 instances of class 0 (non-fraudulent transactions) and 98 instances of class 1 (fraudulent transactions) in the dataset.
In conclusion, the portfolio demonstrates a highly accurate credit card fraud detection model, with excellent performance in identifying non-fraudulent transactions and a good level of detection for fraudulent transactions.
Note that this dataset has class imbalance, with most of the data being non-fraud. Therefore, care needs to be taken in evaluating the performance of the model.
Therefore, the next step is to consider techniques for managing class imbalance, and to conduct cross-validation to obtain a more reliable evaluation.

In this step, we apply an oversampling technique using the SMOTE (Synthetic Minority Over-sampling Technique) method. The aim is to handle the problem of class imbalance in the dataset, where the minority class (fraud) has a much smaller number of samples than the majority class (non-fraud).
Next step, we perform cross-validation using cross_val_score(). The goal is to get a more accurate and reliable estimate of the model's performance.

By using cross-validation, we can reduce the possibility of bias in model evaluation because each sample will be used as training and testing data in multiple iterations and themodel is evaluated using several different training and testing data folds. In this case, we used 5 folds.
Each Cross-Validation accuracy score represents the model's performance at each cross-validation fold. A high accuracy score indicates that the model has a good ability to classify the data.
The average accuracy of the cross-validation scores is 0.9998878880035174, which is very high. This shows that the Random Forest model that has been trained and evaluated using the oversampling technique with SMOTE has an excellent ability to detect fraud in credit card transactions.
With a high average accuracy and relatively small variation in accuracy scores, it can be concluded that this model is stable and consistent in classifying data that has been resampled with SMOTE.
Informasi Course Terkait
Kategori: Artificial IntelligenceCourse: Teknologi Kecerdasan Artifisial

