
Komparasi Sentiment Analyzer NLP Method ML dan DL
Naufal Fawwazi


Summary
Portofolio ini berisikan project implementasi Deep Learning dan Machine Learning pada materi Natural Language Processing. Dataset yang digunakan diambil dari Kaggle yang merupakan data mengenai review makanan yang ada pada platform amazon dari yang mempunyai rating bintang 1 hingga 5. Adapula library yang diperlukan pada project ini yaitu numpy, pandas, matplotlib, dan seaborn.
Description
Saya menggunakan Google Colab sebagai media pemrograman bahasa Python untuk mengerjakan Tugas Akhir pada course ini. Adapun Sentimen Analyzer pertama saya menggunakan VADER model – Bag of words approach, sedangkan untuk Sentimen Analyzer yang kedua saya menggunakan Roberta Pretrained Model.
Disini saya membuat sentimen analyzer menggunakan machine learning method dan deep learning method, kemudian saya akan membandingkan performa atas kedua performa yang telah saya coba. Adapun dataset yang saya gunakan mengenai review makanan yang ada pada platform amazon dari yang mempunyai rating bintang 1 hingga 5. Sebelum melakukan proses koding, saya mengunggah dataset saya ke dalam project Google Colab pada tab file.
Langkah awal yang saya lakukan adalah mengimport library-library yang dibutuhkan pada project ini

Kemudian saya melakukan pembacaan dataset Reviews.csv yang ditampung ke dalam variabel df menggunakan method read_csv dari library pandas, serta menampilkan 5 data teratas menggunakan method head

Lalu saya mencoba mengambil data pertama pada kolom text

Melihat ukuran dari dataset dengan detail baris dan kolom

Supaya sentiment analyzer berjalan dengan lancar, saya mereduksi jumlah baris dari dataset menjadi hanya sebanyak 500 baris teratas

Kemudian disini saya mencoba menampilkan 5 data teratas dari dataset yang telah dipangkas, tidak terlihat adanya perbedaan karena yang dipangkas adalah dataset bagian bawah

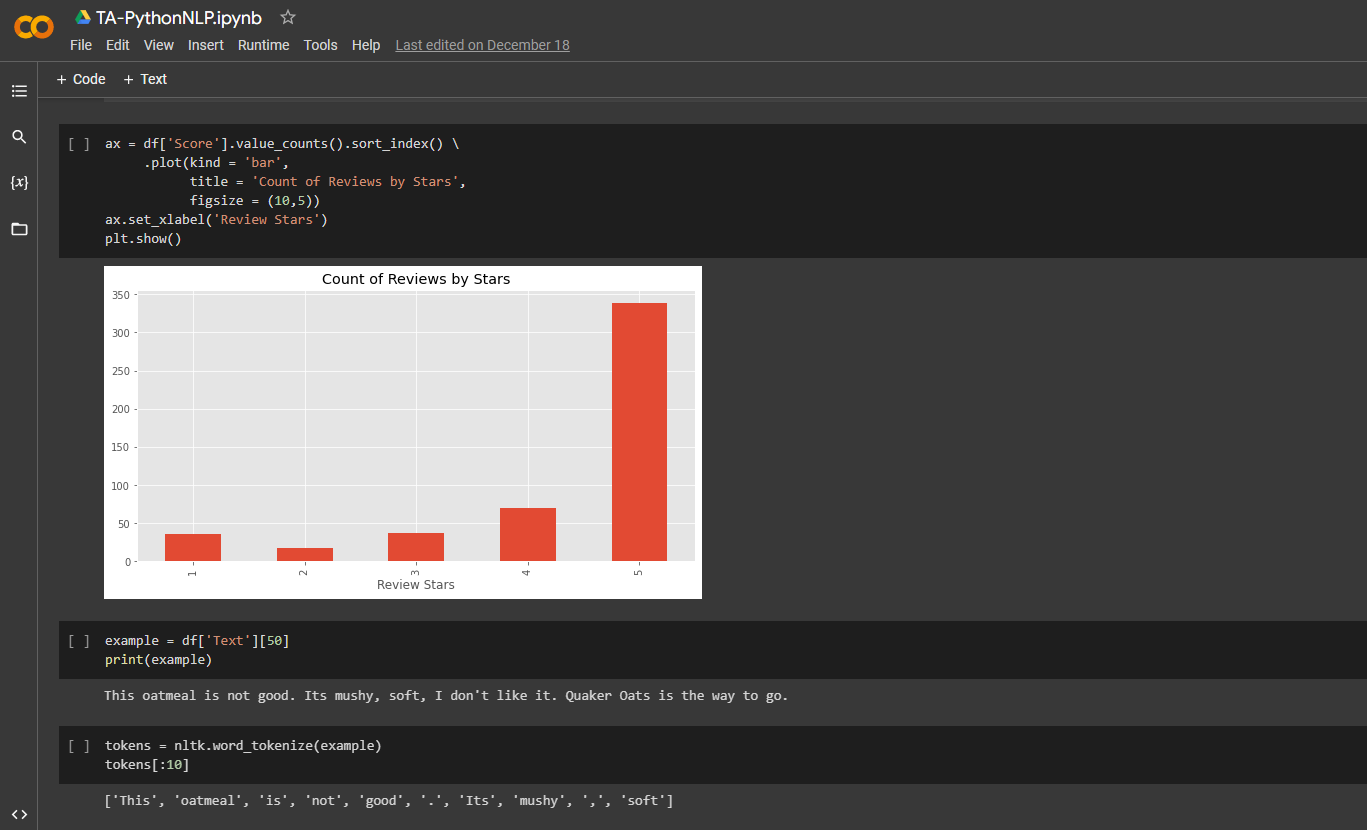
Selanjutnya saya mencoba untuk memvisualisasikan jumlah reviews berdasarkan rating menggunakan library matplotlib.pyplot

Setelah itu saya mencoba beberapa sintaks dasar NLTK, yang pertama adalah menampilkan salah satu reviewer dari kolom text

Melakukan tokenisasi serta menampilkan 10 token pertama

Melakukan pos tag dari hasil tokenisasi yang telah dilakukan sebelumnya, serta menampilkan 10 tag awal

Dan disini saya juga mencoba melakukan pos tag, namun pos tag ini dilakukan per kalimat

Selanjutnya, saya melakukan VADER Sentiment Scoring. Langkah pertama yang saya lakukan yaitu mengimport library yang dibutuhkan untuk melakukan VADER Sentiment Scoring

Lalu saya memeriksa apakah objek sentiment intensity analyzer telah tersedia

Kemudian saya mencoba fitur polarity scores pada kalimat yang saya tampung dalam variabel example

Dari scoring pada model vader yang telah dibuat, kalimat tersebut lebih condong ke arah kalimat netral. Disini saya mencoba untuk melakukan polarity scoring pada seluruh dataset

Setelah itu saya melakukan rename kolom index dari hasil vader model menjadi kolom Id agar dapat digabungkan dengan dataset semula

Sekarang saya sudah memiliki sentiment score dan metadata hasil dari Vader Model. Lalu saya mencoba untuk menampilkan 5 data teratas

Kemudian saya memvisualisasikan hasil dari model VADER ke dalam bentuk barplot menggunakan library dari matplotlib.pyplot serta seaborn

Selanjutnya saya akan membuat 3 macam bar plot berdasarkan score positif, netral, dan negative hasil dari Vader Model yang telah dibuat sebelumnya

Disini dapat dilihat bahwa dengan menggunakan Vader Model:
- Semakin tinggi rating nya maka semakin banyak komentar positif
- Komentar netral cenderung setara atau stabil di semua rating
- Semakin tinggi rating nya maka semakin sedikit komentar negatif
Selanjutnya, saya melakukan Roberta Pretrained Model. Langkah pertama yang saya lakukan yaitu mengimport library yang dibutuhkan untuk melakukan Roberta Pretrained Model

Kemudian saya menginisiasi model dari roberta base sentiment

Menampilkan polarity score pada kalimat dalam variabel example berdasarkan VADER model

Menampilkan polarity score pada kalimat dalam variabel example berdasarkan Roberta model

Disini dapat dlihat bahwa berdasarkan VADER model kalimat “This oatmeal is not good. Its mushy, soft, I don't like it. Quaker Oats is the way to go.” cenderung merupakan kalimat neutral, sedangkan menurut Roberta model kalimat tersebut bermakna negatif. Yang mana apabila kita amati berdasarkan pemikiran manusia, tentu kita akan menilai bahwa kalimat tersebut bermuatan negative. Jadi bisa kita asumsikan bahwa Roberta model mendekati persepsi manusia akan sentiment dalam sebuah kalimat.
Langkah selanjutnya adalah membuat fungsi untuk menghitung polarity score dengan Roberta

Lalu jalankan fungsi tersebut untuk menghitung polarity score menggunakan Roberta Model di seluruh dataset dan menghindari lokasi-lokasi error yang terjadi

Setelah itu melakukan Transpose pada dataframe hasil dari perhitungan polarity score dengan Roberta Model serta mengganti nama kolom index menjadi Id agar bisa digabungkan dengan dataframe sebelumnya (yang terdapat hasil polarity score dari VADER model)

Kemudian saya coba menampilkan 5 data teratas dari dataframe yang telah di transpose

Dan langkah terakhir adalah saya akan membandingkan hasil polarity score dari VADER model dan Roberta model dengan menggunakan pair plot


Kesimpulan dari hasil perbandingan tersebut dapat dikatakan bahwa VADER model kurang ‘percaya diri’ dalam semua prediksinya dibandingkan dengan Roberta Model yang benar-benar memisahkan antara skor positif, netral, dan negative untuk masing-masing nilai prediksi dari rentang bintang review. Sehingga didapatkan kesimpulan bahwa Roberta Model lebih baik daripada VADER model dalam kaitannya dengan sentiment analysis untuk review produk pada rentang rating pada e-commerce.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Dasar Pemrograman Natural Language Programming dengan Python

