
Speech Emotion Recognition using CNN
Ricky Indra Gunawan


Summary
Pengklasifikasi Deteksi Emosi Bicara
Speech Emotion Recognition, disingkat SER, adalah tindakan mencoba mengenali emosi manusia dan keadaan afektif dari ucapan. Ini memanfaatkan fakta bahwa suara sering kali mencerminkan emosi yang mendasari melalui tone dan pitch. Ini juga merupakan fenomena yang digunakan hewan seperti anjing dan kuda untuk dapat memahami emosi manusia.
Description
Pertama-tama kita perlu mengetahui tentang apa itu Speech Emotion Recognition (SER) dan mengapa Speech Emotion Recognition itu penting.
Apa itu Speech Emotion Recognition ?
- Speech Emotion Recognition, disingkat SER, adalah tindakan mencoba mengenali emosi manusia dan keadaan afektif dari ucapan. Ini memanfaatkan fakta bahwa suara sering kali mencerminkan emosi yang mendasari melalui tone dan pitch. Ini juga merupakan fenomena yang digunakan hewan seperti anjing dan kuda untuk dapat memahami emosi manusia.
Mengapa kita membutuhkan Speech Emotion Recognition ?
Pengenalan emosi adalah bagian dari pengenalan suara yang semakin populer dan kebutuhannya meningkat pesat. Meskipun ada metode untuk mengenali emosi menggunakan teknik pembelajaran mesin, proyek ini mencoba menggunakan pembelajaran mendalam untuk mengenali emosi dari data.
SER (Speech Emotion Recognition) digunakan di call center untuk mengklasifikasikan panggilan menurut emosi dan dapat digunakan sebagai parameter kinerja untuk analisis percakapan sehingga mengidentifikasi pelanggan yang tidak puas, kepuasan pelanggan, dan sebagainya. untuk membantu perusahaan meningkatkan layanan mereka
Dapat juga digunakan sistem in-car board berdasarkan informasi kondisi mental pengemudi yang dapat diberikan kepada sistem untuk menginisiasi keselamatannya mencegah terjadinya kecelakaan
Dataset yang digunakan
Langkah Pengerjaan
Langkah pertama yaitu import library yang dibutuhkan dan sambungkan Google Colab dengan Google Drive.


Setelah itu, lakukan data preparation.
- Saya membuat kerangka data yang menyimpan semua emosi data dalam dataframe dengan pathnya.
- Saya akan menggunakan dataframe ini untuk mengekstraksi fitur untuk pelatihan model.

Setelah itu, coba lakukan Data Visualization dan Exploratory Data Analysis

Data yang diperoleh telah balance.
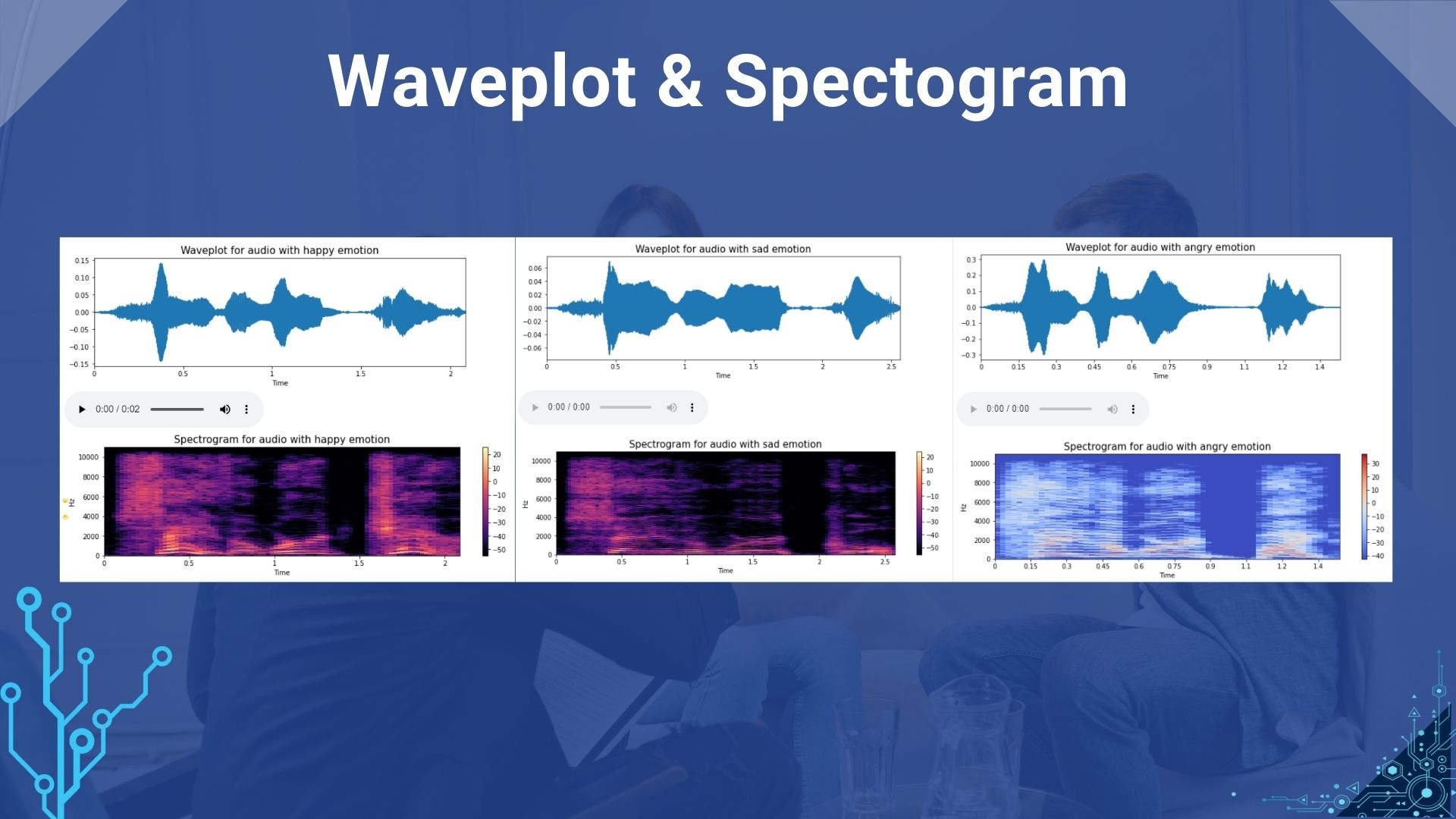
Kita juga dapat memplot waveplot dan spektogram untuk sinyal audio
- Waveplots - Waveplot memberi tahu kita kenyaringan audio pada waktu tertentu.
- Spektogram - Spektogram adalah representasi visual dari spektrum frekuensi suara atau sinyal lain karena bervariasi dengan waktu. Ini adalah representasi frekuensi yang berubah sehubungan dengan waktu untuk sinyal audio/musik yang diberikan.

Data Augmentation
- Data Augmentation adalah proses di mana kita membuat sampel data sintetik baru dengan menambahkan gangguan kecil pada set pelatihan awal kita.
- Untuk menghasilkan data sintaksis untuk audio, kita dapat menerapkan noise injection, pergeseran waktu, perubahan pitch dan kecepatan.
- Tujuannya adalah untuk membuat model kita tidak berubah terhadap gangguan tersebut dan meningkatkan kemampuannya untuk menggeneralisasi.
- Agar ini berfungsi, menambahkan gangguan harus mempertahankan label yang sama dengan sampel pelatihan asli.
Ekstraksi Fitur
- Ekstraksi fitur adalah bagian yang sangat penting dalam menganalisis dan menemukan hubungan antara berbagai hal. Seperti yang telah kita ketahui bahwa data yang disediakan audio tidak dapat dipahami oleh model secara langsung sehingga kita perlu mengubahnya menjadi format yang dapat dimengerti yang digunakan ekstraksi fitur.
Sinyal audio adalah sinyal tiga dimensi di mana tiga sumbu mewakili waktu, amplitudo, dan frekuensi.
Seperti yang dinyatakan di sana dengan bantuan laju sampel dan data sampel, seseorang dapat melakukan beberapa transformasi untuk mengekstraksi fitur berharga darinya.
Pada proyek kali ini, saya menggunakan 5 fitur, yaitu sebagai berikut.
- Zero Crossing Rate
- Chroma_stft
- MFCC
- Nilai RMS (Root Mean Square)
- MelSpectogram untuk melatih model.

Sampai sekarang kita telah mengekstraksi data, sekarang kita perlu menormalkan dan membagi data kami untuk pelatihan dan pengujian.

Kemudian pada tahap modelling dan training


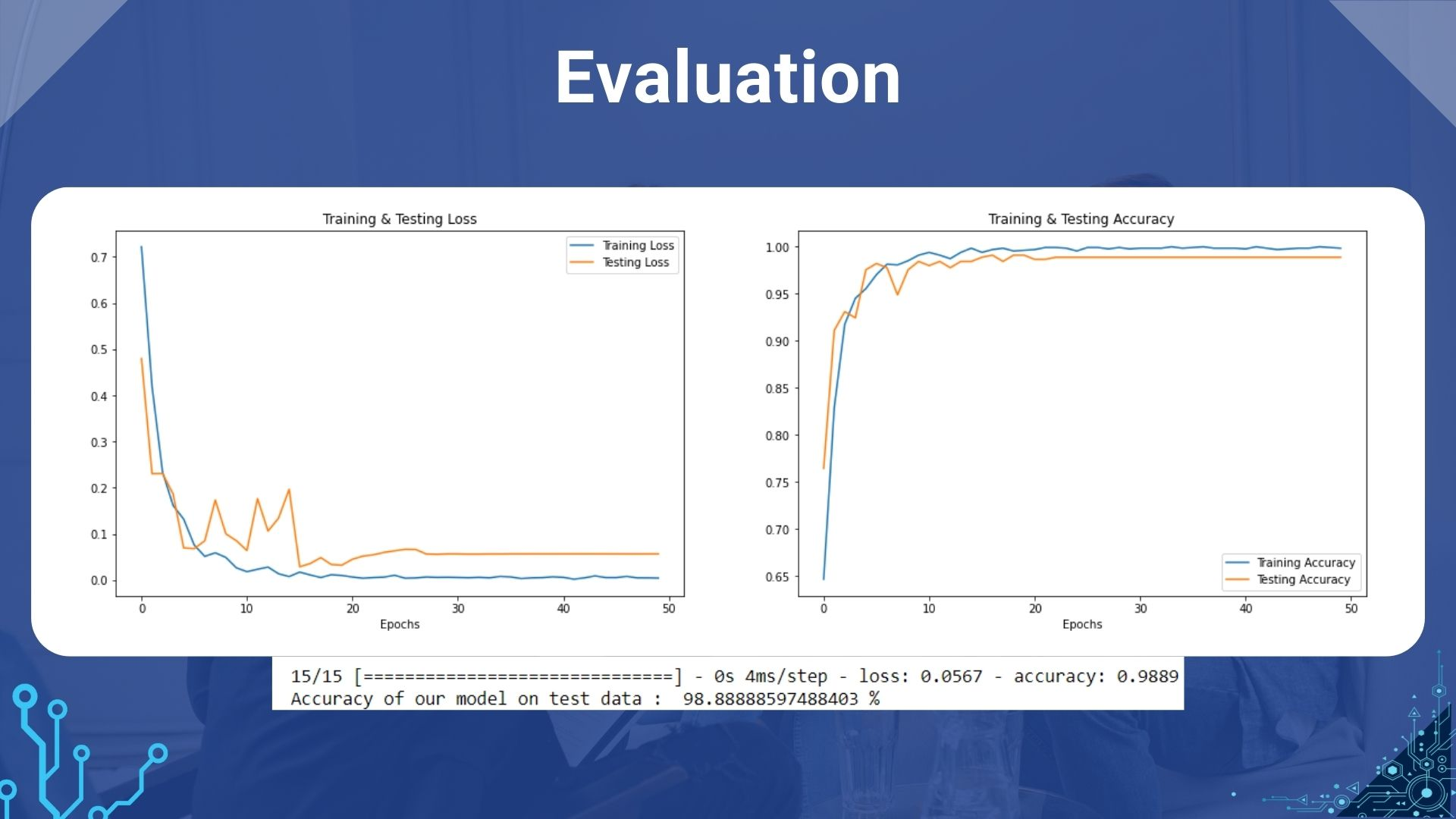
Diperoleh 99.93% training accuracy dan 99.93% validation accuracy pada epoch terakhir.
Setelah itu, dilakukan evaluasi model.

Berikut confusion matrix hasil evaluasi model.

Berikut evaluasi model dengan menggunakan metric lainnya, seperti precision, recall, dan f1-score.

Informasi Course Terkait
Kategori: Speech ProcessingCourse: Speech Classification Menggunakan Deep Neural Network

