
EDA dan Modeling Profil Karyawan dengan PySpark
Fitria Adyati Mardha



Summary
Data yang digunakan merupakan dataset data_profil yang berasal dari dataset open source Kagle berikut: Dataset
Pada data tersebut, tahapan yang akan dilakukan adalah EDA (Exploratory Data Analysis) dan Modeling menggunakan PySpark.
Pengolahan data kali ini menggunakan Google Colab.
Description
Data yang digunakan merupakan dataset data_profil yang berasal dari dataset open source Kagle berikut: Dataset
Pada data tersebut, tahapan yang akan dilakukan adalah EDA (Exploratory Data Analysis) dan Modeling menggunakan PySpark.
Pengolahan data kali ini menggunakan Google Colab.
Pendahuluan
1. Install PySpark

Diatas adalah kode untuk menginstal pyspark pada python.
2. Create Spark Session
SparkSession adalah titik masuk ke fungsionalitas Spark yang mendasarinya untuk membuat Spark RDD, DataFrame, dan DataSet secara terprogram. SparkSession akan dibuat menggunakan SparkSession.builder().

3. Masukkan dataset yang sudah di download ke dalam Google Drive pada folder dataset

Jika pada Google Drive belum memiliki folder “dataset” maka create folder terlebih dahulu. Jika sudah, maka gunakan folder tersebut.
4. Menghubungkan Google Colab dengan Google Drive

Hal ini dilakukan agar Google Colab dapat membaca dataset yang berada di Google Drive.
5. Membaca Data yang berada di Google Drive

EDA (Exploratory Data Analysis)
EDA adalah proses eksplorasi data dimana pendekatan menganalisis kumpulan data untuk merangkum karakteristik utamanya.
1. Melihat Tipe Data setiap Kolom

Dari output diatas, didapatkan bahwa untuk kolom id dan umur memiliki tipe data integer sedangkan kolom jenis_kelamin dan divisi memiliki tipe data string.
2. Melihat Nama Kolom, Jumlah Kolom, dan Jumlah Baris

3. Melihat Statistik Data untuk Setiap Kolom

Dari output diatas, dapat dilihat statistik data yaitu jumlah baris, mean (rata - rata), stddev (standar deviasi), min (nilai terkecil), dan max (terbesar) dari setiap kolomnya.
4. Menampilkan Kolom yang Diinginkan

Pada output diatas, ditampilkan 2 kolom yaitu ‘divisi’ dan ‘umur’ sesuai dengan yang diminta pada code.
5. Membuat Kolom Baru yang Berisikan Kolom Lama namun DItamabahkan dengan Suatu Nilai

Pada Ouput diatas, terdapat kolom baru bernama ‘umur + 1’ dimana berisikan nilai nilai dari kolom lama yaitu ‘umur’ namun ditambahkan nilainya dengan 1
6. Membuat Kolom Baru menjadi Permanen

7. Mengubah Nama Kolom

Pada Putput diatas, terdapat kolom ‘gender’ yang sebelumnya bernama ‘jenis kelamin’.
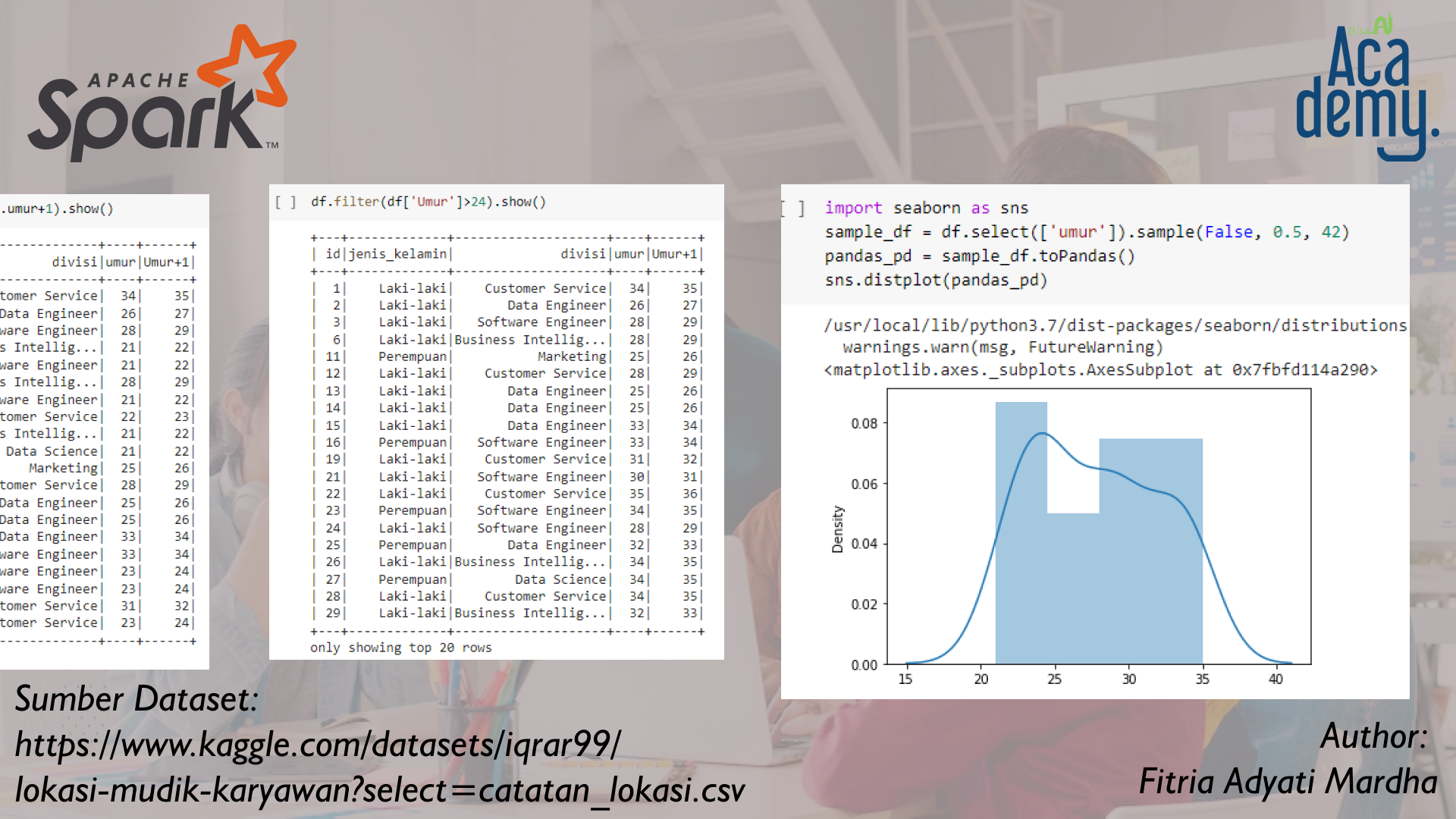
10. Memfilter Suatu Kolom

Pada Output diatas, tabel hanya berisikan data dengan umur diatas 24 tahun. Itu karena pada code diminta untuk menampilkan data dengan ketentuan hanya karyawan yang berada diatas 24 tahun saja.
11. Visualisasi Data Pada Kolom

Pada output diatas terdapat visualisasi data dengan distplot dari kolom umur. Dari data diatas dapat diketahui bahwa karyawan terbanyak berada pada rentang umur 24 - 25 tahun.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Big Data Analytics dengan PySpark



