
PERKALIAN MATRIKS DENGAN MPI
Salman Abdul Jabbaar Wiharja


Summary
Message Passing Interface (MPI) is a standardized and portable message-passing standard designed to function on parallel computing architectures. The MPI standard defines the syntax and semantics of library routines that are useful to a wide range of users writing portable message-passing programs in C, C++, and Fortran. There are several open-source MPI implementations, which fostered the development of a parallel software industry, and encouraged development of portable and scalable large-scale parallel applications. [1]
Description
Perkalian Matriks dengan MPI
Salman Abdul Jabbaar Wiharja
Studi Independen BISA AI Batch 3 (AI INFRA)
-----------------------------------------------------------------------------------------------------
A. Prerequisite
- Visual Studio Comunity 2022
- Microsoft MPI
B. Install Prerequisite
1. Download dan Install Microsoft MPI
Download di 'https://learn.microsoft.com/en-us/message-passing-interface/microsoft-mpi'

Dowload kedua filenya lalu install

2. Download Visual Studio Comunity 2022
Download di 'https://visualstudio.microsoft.com' Sesuaikan dengan Operating System yang digunakan. (saya menggunakan Windows)

Kemudian install Desktop Development with C++

C. Create New Project dengan Visual Studio
Launch Visual Studio Comunity 2022 kemudian buat project baru. pilih Create a new project

Pilih Console App lalu klik Next

Kemudian berinama project sesuai dengan yang kita inginkan lalu klil Create

D. Konfigurasi Visual Studio dengan MPI
1. Menambahkan Direktori Include C/C++
Buka
Project > MPI Properties > C/C++ > Additional Include Directories > “klik gambar panah bawah” > klik “<*edit*>” > New Line (Gambar Tambah) > Tambah Direktori Include 'C:\Program Files (x86)\Microsoft SDKs\MPI\Included' (x64 atau x86 tergantung prosessor kalian) > Select Folder > Oke > Apply

2. Menambahkan Direktori Library Linker
Buka
Project > MPI Properties > Linker > Additional Library Directories > “klik gambar panah bawah” > klik “<*edit*>” > New Line (Gambar Tambah) > Tambah Direktori Include 'C:\Program Files (x86)\Microsoft SDKs\MPI\Libd' (x64 atau x86 tergantung prosessor kalian) > Select Folder > Oke > Apply

3. Input Library file msmpi.lib
Buka
Project > MPI Properties > Linker > Input > Additional Dependencies > ketik msmpi.lib > Oke > Apply

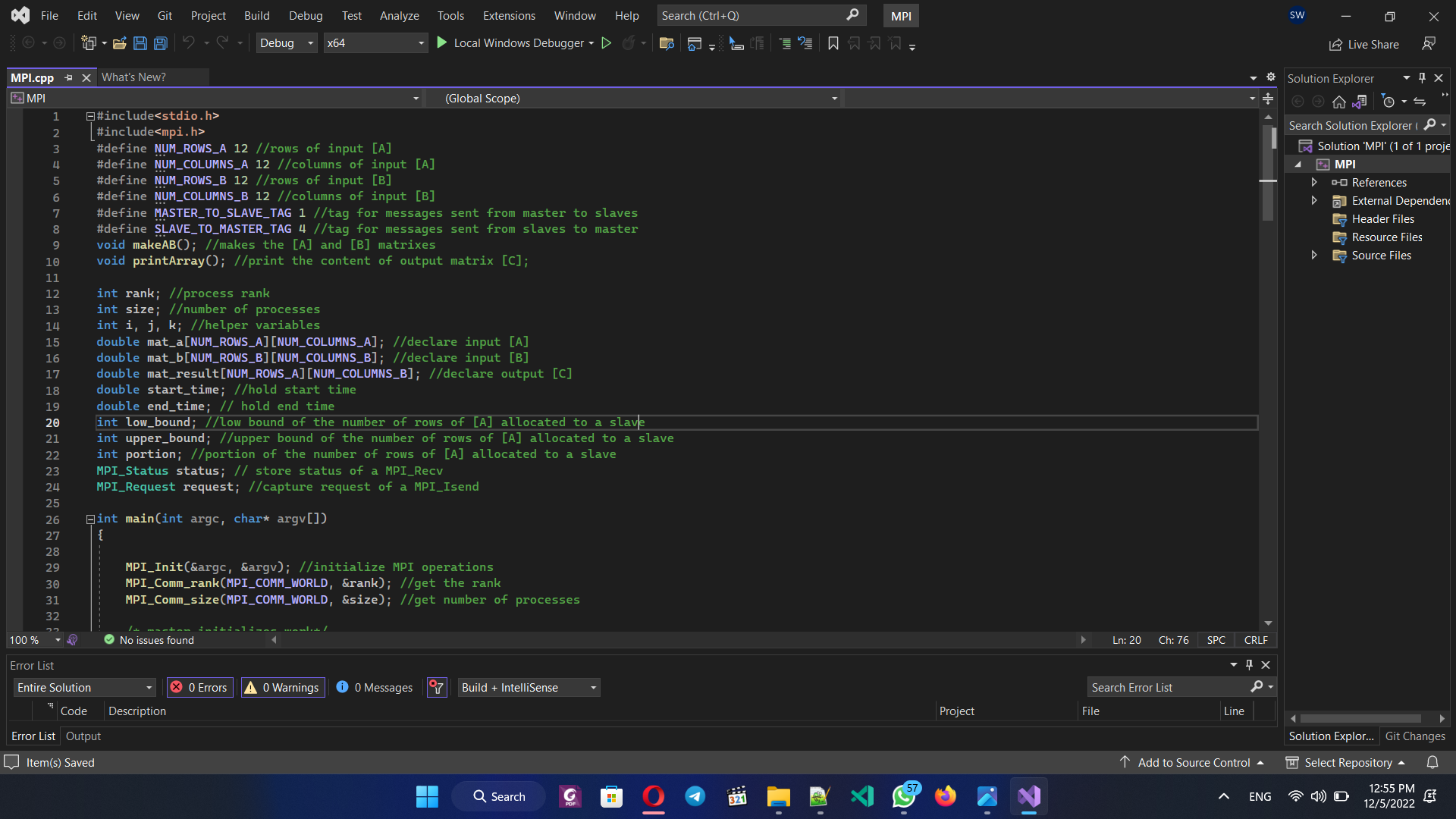
D. Program Matriks dengan MPI
Berikut program nya:
#include<stdio.h>
#include<mpi.h>
#define NUM_ROWS_A 12 //rows of input [A]
#define NUM_COLUMNS_A 12 //columns of input [A]
#define NUM_ROWS_B 12 //rows of input [B]
#define NUM_COLUMNS_B 12 //columns of input [B]
#define MASTER_TO_SLAVE_TAG 1 //tag for messages sent from master to slaves
#define SLAVE_TO_MASTER_TAG 4 //tag for messages sent from slaves to master
void makeAB(); //makes the [A] and [B] matrixes
void printArray(); //print the content of output matrix [C];
int rank; //process rank
int size; //number of processes
int i, j, k; //helper variables
double mat_a[NUM_ROWS_A][NUM_COLUMNS_A]; //declare input [A]
double mat_b[NUM_ROWS_B][NUM_COLUMNS_B]; //declare input [B]
double mat_result[NUM_ROWS_A][NUM_COLUMNS_B]; //declare output [C]
double start_time; //hold start time
double end_time; // hold end time
int low_bound; //low bound of the number of rows of [A] allocated to a slave
int upper_bound; //upper bound of the number of rows of [A] allocated to a slave
int portion; //portion of the number of rows of [A] allocated to a slave
MPI_Status status; // store status of a MPI_Recv
MPI_Request request; //capture request of a MPI_Isend
int main(int argc, char* argv[]){
MPI_Init(&argc, &argv); //initialize MPI operations
MPI_Comm_rank(MPI_COMM_WORLD, &rank); //get the rank
MPI_Comm_size(MPI_COMM_WORLD, &size); //get number of processes
/* master initializes work*/
if (rank == 0) {
makeAB();
start_time = MPI_Wtime();
for (i = 1; i < size; i++) {//for each slave other than the master
portion = (NUM_ROWS_A / (size - 1)); // calculate portion without master
low_bound = (i - 1) * portion;
if (((i + 1) == size) && ((NUM_ROWS_A % (size - 1)) != 0)) { //if rows of [A] cannot be equally divided among slaves
upper_bound = NUM_ROWS_A; //last slave gets all the remaining rows
} else {
upper_bound = low_bound + portion; //rows of [A] are equally divisable among slaves
}
//send the low bound first without blocking, to the intended slave
MPI_Isend(&low_bound, 1, MPI_INT, i, MASTER_TO_SLAVE_TAG, MPI_COMM_WORLD, &request);
//next send the upper bound without blocking, to the intended slave
MPI_Isend(&upper_bound, 1, MPI_INT, i, MASTER_TO_SLAVE_TAG + 1, MPI_COMM_WORLD, &request);
//finally send the allocated row portion of [A] without blocking, to the intended slave
MPI_Isend(&mat_a[low_bound][0], (upper_bound - low_bound) * NUM_COLUMNS_A, MPI_DOUBLE, i, MASTER_TO_SLAVE_TAG + 2, MPI_COMM_WORLD, &request);
}
}
//broadcast [B] to all the slaves
MPI_Bcast(&mat_b, NUM_ROWS_B * NUM_COLUMNS_B, MPI_DOUBLE, 0, MPI_COMM_WORLD);
/* work done by slaves*/
if (rank > 0) {
//receive low bound from the master
MPI_Recv(&low_bound, 1, MPI_INT, 0, MASTER_TO_SLAVE_TAG, MPI_COMM_WORLD, &status);
//next receive upper bound from the master
MPI_Recv(&upper_bound, 1, MPI_INT, 0, MASTER_TO_SLAVE_TAG + 1, MPI_COMM_WORLD, &status);
//finally receive row portion of [A] to be processed from the master
MPI_Recv(&mat_a[low_bound][0], (upper_bound - low_bound) * NUM_COLUMNS_A, MPI_DOUBLE, 0, MASTER_TO_SLAVE_TAG + 2, MPI_COMM_WORLD, &status);
for (i = low_bound; i < upper_bound; i++) {//iterate through a given set of rows of [A]
for (j = 0; j < NUM_COLUMNS_B; j++) {//iterate through columns of [B]
for (k = 0; k < NUM_ROWS_B; k++) {//iterate through rows of [B]
mat_result[i][j] += (mat_a[i][k] * mat_b[k][j]);
}
}
}
//send back the low bound first without blocking, to the master
MPI_Isend(&low_bound, 1, MPI_INT, 0, SLAVE_TO_MASTER_TAG, MPI_COMM_WORLD, &request);
//send the upper bound next without blocking, to the master
MPI_Isend(&upper_bound, 1, MPI_INT, 0, SLAVE_TO_MASTER_TAG + 1, MPI_COMM_WORLD, &request);
//finally send the processed portion of data without blocking, to the master
MPI_Isend(&mat_result[low_bound][0], (upper_bound - low_bound) * NUM_COLUMNS_B, MPI_DOUBLE, 0, SLAVE_TO_MASTER_TAG + 2, MPI_COMM_WORLD, &request);
}
/* master gathers processed work*/
if (rank == 0) {
for (i = 1; i < size; i++) {// untill all slaves have handed back the processed data
//receive low bound from a slave
MPI_Recv(&low_bound, 1, MPI_INT, i, SLAVE_TO_MASTER_TAG, MPI_COMM_WORLD, &status);
//receive upper bound from a slave
MPI_Recv(&upper_bound, 1, MPI_INT, i, SLAVE_TO_MASTER_TAG + 1, MPI_COMM_WORLD, &status);
//receive processed data from a slave
MPI_Recv(&mat_result[low_bound][0], (upper_bound - low_bound) * NUM_COLUMNS_B, MPI_DOUBLE, i, SLAVE_TO_MASTER_TAG + 2, MPI_COMM_WORLD, &status);
}
end_time = MPI_Wtime();
printf(" Running Time = %f ", end_time - start_time);
printArray();
}
MPI_Finalize(); //finalize MPI operations
return 0;
}
void makeAB(){
for (i = 0; i < NUM_ROWS_A; i++) {
for (j = 0; j < NUM_COLUMNS_A; j++) {
mat_a[i][j] = i + j;
}
}
for (i = 0; i < NUM_ROWS_B; i++) {
for (j = 0; j < NUM_COLUMNS_B; j++) {
mat_b[i][j] = i * j;
}
}
}
void printArray(){
for (i = 0; i < NUM_ROWS_A; i++) {
printf(" ");
for (j = 0; j < NUM_COLUMNS_A; j++)
printf("%8.2f ", mat_a[i][j]);
}
printf(" ");
for (i = 0; i < NUM_ROWS_B; i++) {
printf(" ");
for (j = 0; j < NUM_COLUMNS_B; j++)
printf("%8.2f ", mat_b[i][j]);
}
printf(" ");
for (i = 0; i < NUM_ROWS_A; i++) {
printf(" ");
for (j = 0; j < NUM_COLUMNS_B; j++)
printf("%8.2f ", mat_result[i][j]);
}
printf(" ");
}
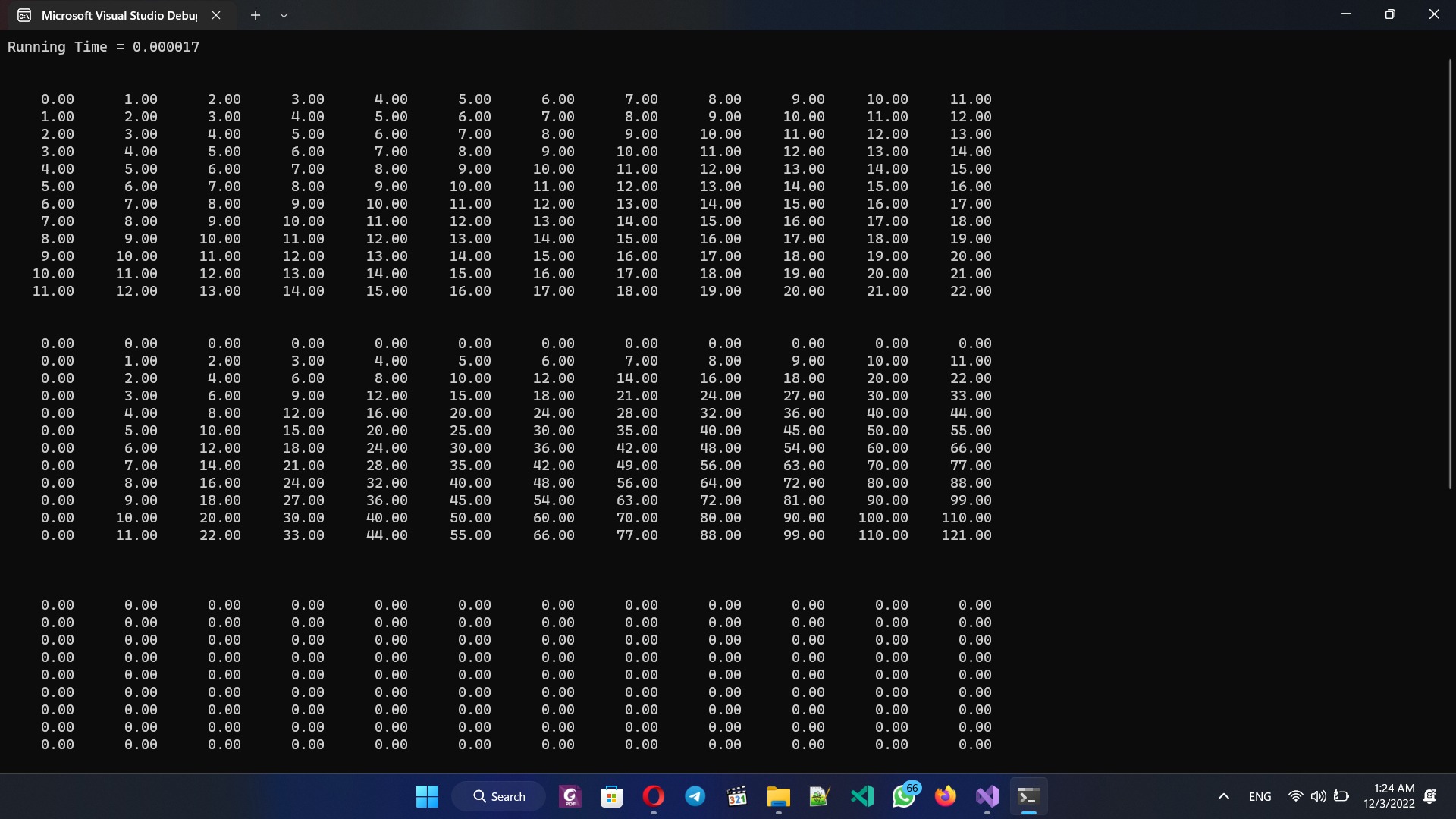
Untuk build dan run program bisa mengunakan tombol “segitiga hijau” dan berikut Output programnya:

Informasi Course Terkait
Kategori: Mobile ProgrammingCourse: High Performance Computing (HPC) dengan MPI



