
Classification With SVM & Decision Tree
Sonia Layra Ega Yanti

Summary
Classification is a technique in data mining. Where it is often used on data sets that are large enough to help solve a problem. Support Vector Machine or SVM is one of the algorithms in supervised machine learning which is used for classification and regression. The goal of SVM is to divide the dataset into classes to find the maximum marginal hyperplane. Decision Tree is one of the algorithms in supervised machine learning which is used for classification and regression. Purpose Decision Tree is a predictive modeling tool that can be applied across many aspects of decisions.
In this portfolio, we will discuss the implementation of the SVM algorithm and Decision Tree. By using a dataset from Kaggle, namely Data for Admission in the University. Data is required to take university admissions for higher studies.
Link dataset : Data for Admission in the University
Description
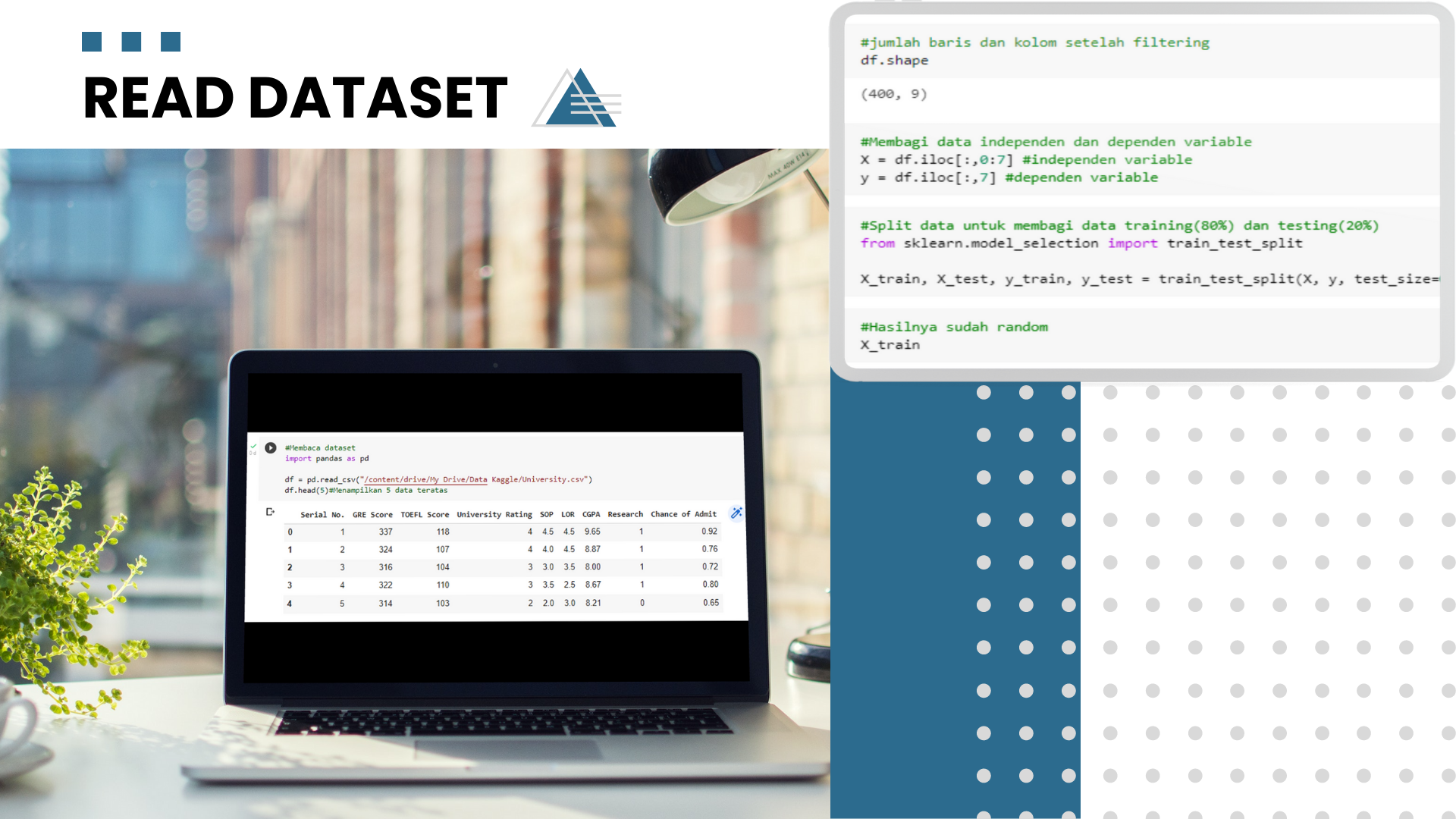
1. Read Dataset

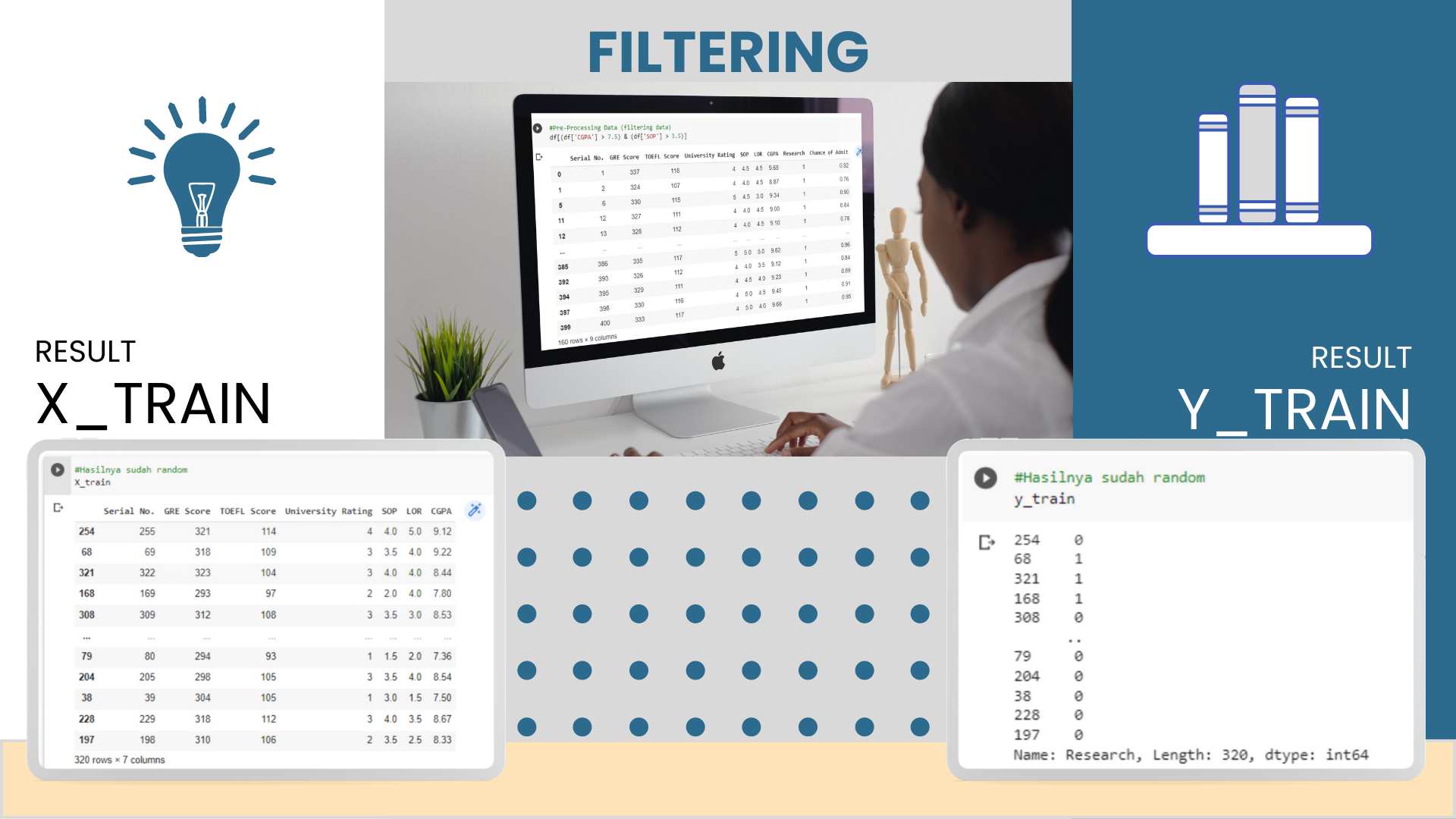
2. Pre-Processing Data

3. Split Data Into Training and Testing

3. Training model


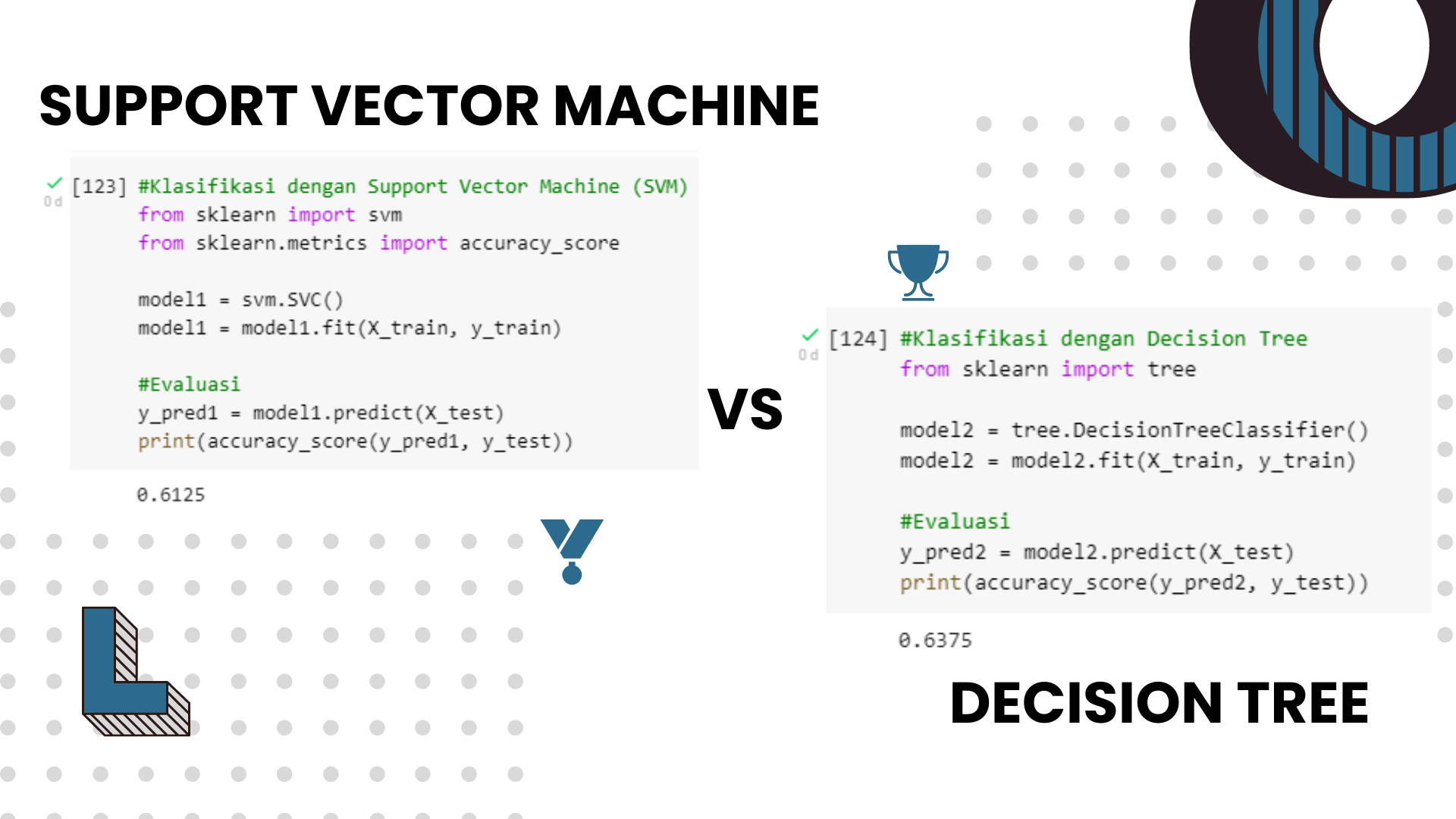
4. Model Cerdas & Evaluasi
- Support Vector Machine

- Decision Tree

Informasi Course Terkait
Kategori: Artificial IntelligenceCourse: Produk dan Desain Kecerdasan Artifisial (SIB AI-Hipster)
