
Big Data Analytics dengan PySpark: Dataset Mall
Kevin Gustian The


Summary
Apache Spark adalah engine analisis terpadu untuk memproses data dalam skala besar dengan sangat cepat. Fitur utama Apache Spark adalah komputasi cluster di memori yang meningkatkan kecepatan pemrosesan aplikasi. Apache Spark dirancang untuk dapat menangani berbagai macam beban kerja seperti batch, iterative algorithms, interactive queres, dan streaming. PySpark adalah Python API untuk Apache Spark, open source, kerangka kerja komputasi terdistribusi dan kumpulan library untuk pemrosesan data skala besar waktu nyata. PySpark sangat cocok digunakan untuk memproses dataset yang sangat besar (Big Data). Dalam portofolio ini akan dilakukan analisis Big Data dengan PySpark pada dataset Mall (https://drive.google.com/file/d/1e4gTzUetGIlU_wh75vEWz5b4BUVBKmO9/view).
Description
Langkah-langkah proses analisis Big Data dengan PySpark, yaitu sebagai berikut:
- Install PySpark

- Membuat Spark Session

- Membaca dataset

- Menampilkan tipe data pada setiap kolom

- Menampilkan nama kolom, jumlah baris, dan jumlah kolom

- Menampilkan statistik data pada setiap kolom

- Menampilkan kolom CustomerID dan Gender

- Membuat kolom baru yaitu Total Income dengan nilai Annual Income + Bonus Income


- Mengubah nama kolom TotalIncome menjadi Total Income (k$)

- Melakukan filter data dimana Age (Umur) lebih besar dari 30 tahun

- Melakukan imputasi data jika ada data yang kosong pada dataframe

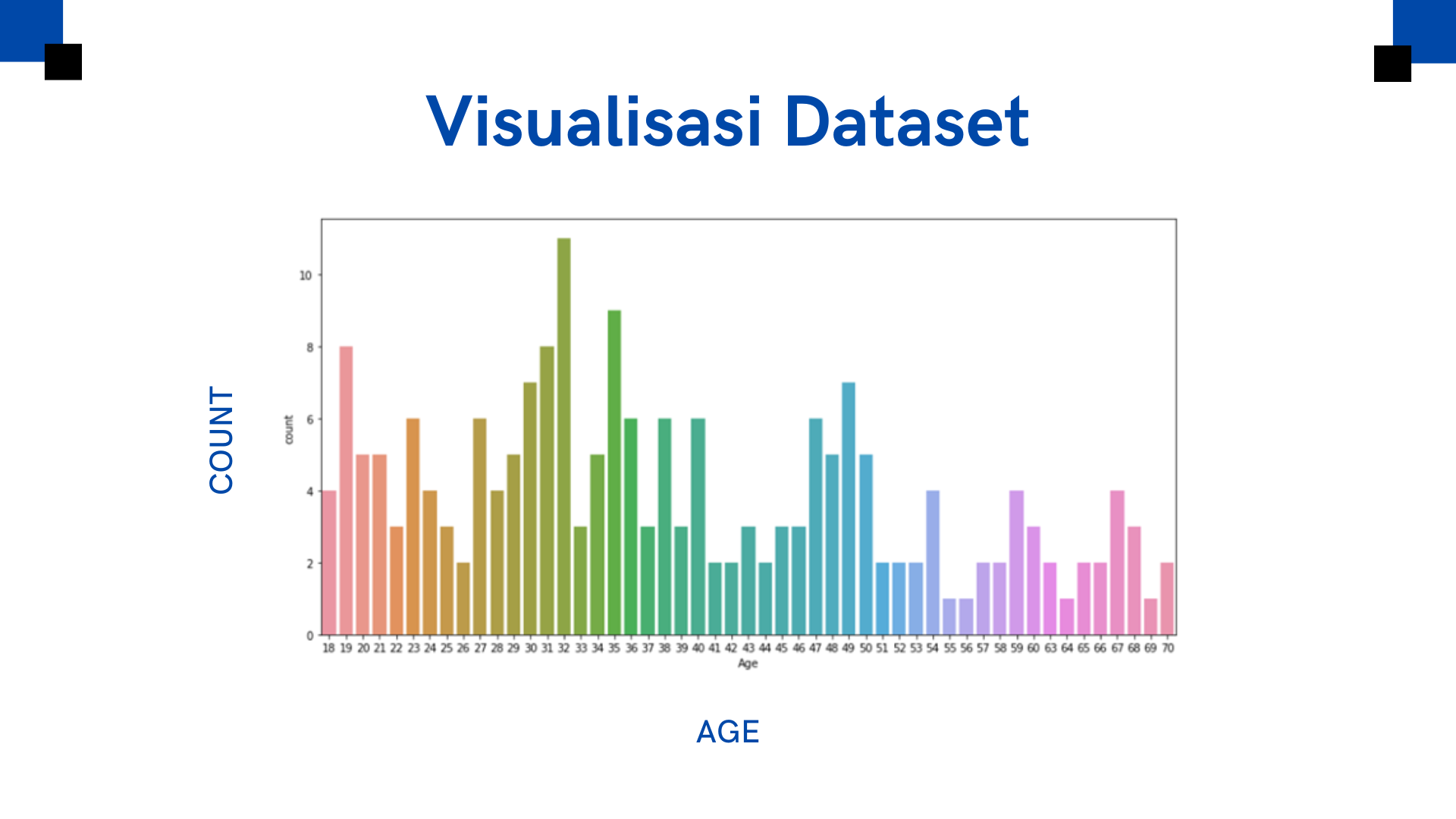
- Melakukan visualisasi data pada kolom Age

Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Big Data Analytics dengan PySpark



